Results
Selenoprotein analysis
On the next table we show the results from our predicted proteins of Ceratotherium simum usign Homo sapiens, Mus musculus and Equus caballus as querys.
| Protein | Selenocystein | BLAST | Exonerate | Genewise | T-Coffee | SECIS | Seblastian | Selenoprofiles |
|---|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
Machinery analysis
We have checked the presence of the genes encoding the machinery proteins (see above for SPS1 and SPS2)
| Protein | Selenocystein | BLAST | Exonerate | Genewise | T-Coffee | SECIS | Seblastian | Selenoprofiles |
|---|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
tRNA scan
Selenocysteine needs a specific tRNA, typically known as selenocysteine tRNA, codified by all the organisms that express selenoproteins. In order to get them, we have run the program tRNAscan-se, which will find all the tRNA presents in the target organism. Although we have described several differences between the selenocysteine tRNA and the typical tRNA, the program is able to find both types of tRNA. Therefore, we download the executable form of tRNAscan-SE and we install it changing the directories and permissions and we run it with the follow command line:
The tRNAs.txt contains all the tRNA that can be predicted using the structural and sequences parameters of the tRNAscan-SE program, including all the selenocysteines tRNA. We select the selenocysteine tRNA using the command line that follows, which choose only those tRNA that recognize our codon of interest –UGA-.
gi|398923655|gb|JH767743.1| 15 12537325 12537244 Ser TGA 0 0 78.58 gi|398922777|gb|JH767762.1| 6 158858 158939 Ser TGA 0 0 78.00 gi|398920810|gb|JH767833.1| 52 3878421 3878502 Ser TGA 0 0 79.60 gi|398920810|gb|JH767833.1| 53 3913318 3913399 Ser TGA 0 0 79.60 gi|398920810|gb|JH767833.1| 73 3849519 3849438 Ser TGA 0 0 79.60 gi|398920810|gb|JH767833.1| 100 2179280 2179199 Pseudo TGA 0 0 38.49
These are the tRNA obtained in C. simum that are able to recognize the selenocysteine and thus leading to the synthesis of selenoproteins. Remarkably, the third selenocysteine tRNA is located in the same genomic region than the GPx5 and GPx6 selenoproteins.
Discussion
DI Family
The iodothyronine deiodinases family (DI) is essential in the thyroidal hormones due the role that they have in the activation and deactivation of this hormones. The literature (and also our work) says that we can find 3 of this proteins (DI1, DI2, DI3). This family presents a high level of homology between their members. DI2 is a protein that activates the hormones by deionidation of the outer tyrosol ring. Talking about DI3 the literature says that all of the genes associated to this protein are made by just one exon.
It has been seen that this family is related to the Kashin-Beck disease, and the cause is a selenium or iodine deficiency. As we said before, DIO family is directly related to Thyroid hormone production. Click here to see the multiple sequence alignment among the predicted members of the DI family.
DI1
The selenoprotein DI1 is located in the scaffold gi|398921711|gb|JH767796.1 between positions “6276177” and “6291609” on the forward strand. The predicted gene for H.sapiens query contains 3 introns and 4 exons. This intron/exon structure stays consistent in the horse and the mouse. Click here to see the gene structure.
We have found the different predicted proteins using human, mouse and horse protein. As we can see in the next alignment, This can be explained by the high similarity between the three queries. Click here to see the multiple sequence alignment among the different predicted proteins.
We have found additional hits for DI1 in other genomic regions, all of they are in the DI2 and DI3 regions, this Is due the similarity between the proteins of the DI family. It is true that Gpx7 gives the same scaffold, but the position is up to 1,000,000 of bp away.
The seblastian analysis shows that this protein contains a single SECIS element of the grade A, it is found in the position 6,342,564 and ends at 6,409,019.
Looking at the homology between mammalian species we can describe that DI presents a high homology between C Simum and the other three queries. Click here to see the multiple sequence alignment among the predicted protein and other mammals'. No pseudogenes nor unassigned hits nor duplications have been predicted.
This selenoprotein (Thyroid hormone deiodinase ) is located in the plasma membranes, its function is to remove the iodine from the outer ring of t4, and produce plasma T3, it also catalyze the deionidation and inactivation (associated to deionidation) of t3.
{kind=link}
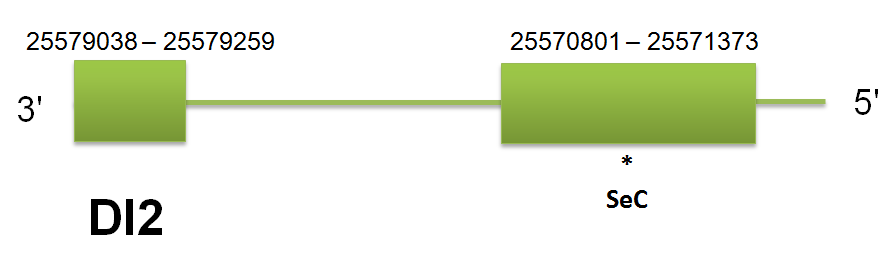
DI2
The selenoprotein DI2 is located in the scaffold gi|398923836|gb|JH767740.1 between positions “25570801” and “25579259” on the reverse strand. The predicted gene for H.sapiens query contains 1 intron and 2 exons. Click here to see the gene structure. We have found the same predicted protein using human, mouse and horse protein sequence as well as using Selenoprofiles. Genewise did not showed any accurate results. This can be explained by the high similarity between the three queries. Click here to see the sequence of the predicted protein.
We have found additional hits for DI2 in other regions of the DI family, it is normal due the high similarity between the proteins of the family, and correlates with the information obtained in DI1, and DI3. Also GPx2 it is found in the same Scaffold, but aproximately 14 milions of bp away.
The seblastian analysis did not give us a selenoprotein, but using Selenoprofiles and Genewise we can ensure that DI2 have one selenocistein. Also the literature says that the DI family presents selenoproteins in all of their members.
DI2 also presents A secis element whch is detected by Seblastian. We can find it at the position 25,565,892 and ends at the 25,565,966 . This secis element free energy of -18,77.
When we analyze the homology between different mammalian species proteins we obtain a high homology between C simum and the three one used to predict: Human, Mouse, Horse. Click here to see the multiple sequence alignment among the predicted protein and other mammals'. No pseudogenes, unassigned hits or duplications were predicted.
{kind=link}
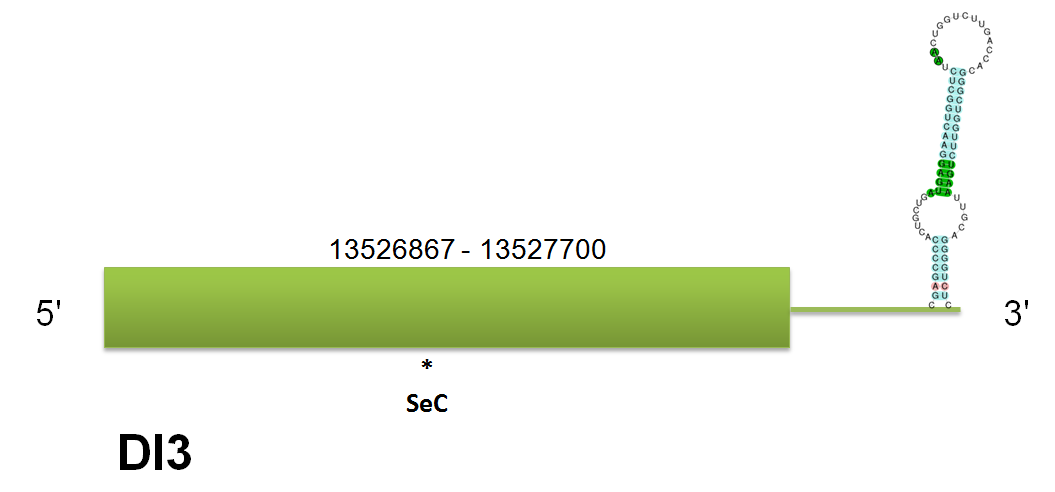
DI3
The selenoprotein DI3 is located in the scaffold gi|398922406|gb|JH767771.1 between positions “13526867” and “13527700” on the forward strand. We have predicted diferent proteins according to the different querys used. Click here to see the multiple sequence alignment among the different predicted proteins.
We have found the same predicted protein using human and mouse but SelenoDB did not have the same query for Horse. Selenoprofiles and Genewise predicted the same protein, but in the case of Selenoprofiles we find that it predicts more exons than the predicted with our program and Genewise. Click here to see the gene structure predicted with the human query. This is an important point, in this case the query used is the master blast query. As we had told in the beginning of the DI family analysis all DI3 genes obtained are intronless so the results obtained by Selenoprofiles could be due an isoform or due an error in the program. Finally we can conclude, by using our programs (except selenoprofiles), that the correct results is the the one with just one exon. The seblastian analysis show that this protein contains a single SECIS element of the grade A and a single selenocistein in the only exon predicted.
We have found additional hits for DI3 in other genomic regions, all of they are in the DI2 and DI1 regions, this Is due the similarity between the proteins of the DI family. When we analyze the homology between different mammalian proteins we obtain a high homology between C simum and the three one used to predict: Human, Mouse, Horse. Click here to see the multiple sequence alignment among the predicted protein and other mammals'.
When we analyze the homology in the proteins of the same family we observe that the DI family conserve a lot of domains, but presents (as normal) many variations. No pseudogenes nor unassigned hits nor duplications have been predicted.
This protein located in the plasma membrane is essential in catalyze the deionidation (T4-T3) in the periphereal tissues.
{kind=link}
GPx Family
There are described 8 members of the GPx family, 5 of which contain a selenocysteine, while the other three are formed by a homologous cysteine. Mariotti et al have established an evolutionary tree where three different groups were observed: GPx1 with GPx2; GPx3 with GPx5 and 6; and GPx4 with GPx7 and 8. We will follow this estimated structure in order to perform the analysis of the Ceratotherium simum GPx family.
The importance of this evolutionary tree resides in the similarity between the different GPx of the same group, possibly greater than the one expected in the same family. Thus, GPx5 and 6 arose from GPx3 in tandem duplication at the root of placental mammals, while GPx7 and GPx8 have evolved from a GPx4-like selenoprotein ancestor, prior to separation of mammals and fishes. Surprisingly, no GPx5 containing a selenocysteine has been found yet, meaning that the Sec to Cys replacement took place very early and we do not expect any GPx5 with Sec in mammals.
Click here to see the multiple sequence alignment among the predicted members of the GPx family.
GPx1 and GPx2
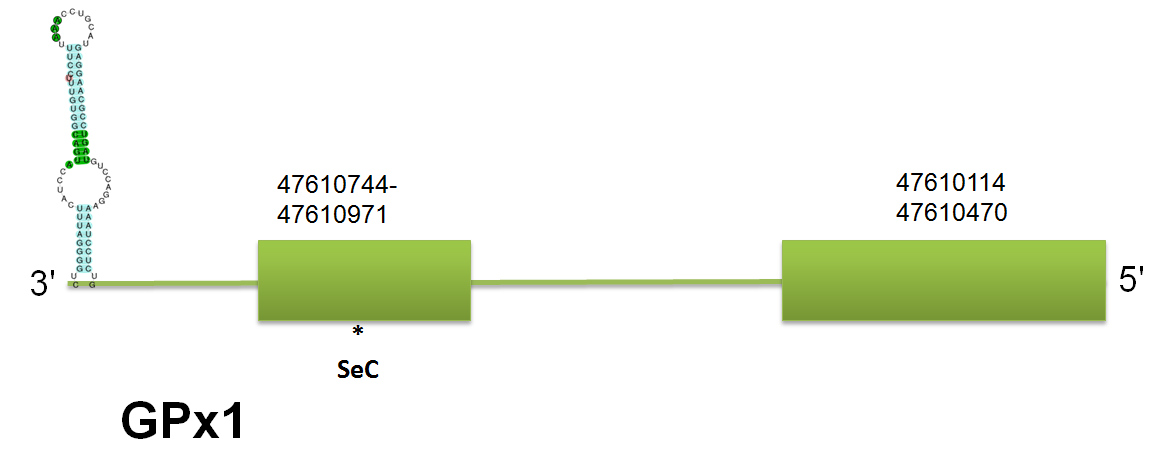
The selenoprotein GPx1 is located in the scaffold gi|398925264|gb|JH767725.1 between positions 47610114 and 47610971 on the reverse strand. The prediction using the mouse query for GPx is coincident differences up to 9 bp in the total gene length). There is no prediction for horse because there is no query available. Click here to see the multiple sequence alignment among the different predicted proteins. The predicted protein by the H. sapines query has 2 exons, the same number of exons predicted by the mouse query. Click here to see the gene structure predicted with homo sapiens.
As we can see in the following alignment, GPx1 is conserved among mammals. Click here to see the multiple sequence alignment among the GPx1 predicted protein and other mammals'.
Using the Selenoprofiles, we have predicted the same scaffold located on the reverse strand, using as a query GPX1_CALJA, which will find not only GPx1 but possibly others -although the program show some bugs in identifying GPx family and probably we miss some of them-. It has also 2 exons, where the exon 1 is comprised in the same exact region than in mouse, where the second exon is comprised in the same exact region than in human. Thereby, this supports the point that more information in the queries will allow better determination of the elements in C. simum. According to Genewise, we could not find any coincident result. Moreover, Seblastian has predicted a selenoprotein with one selenocysteine and with two SECIS elements, one of grade A and another one of grade B, being both of them on the reverse strand and thermodynamically stable.
Interestingly, our program output several other results for the query of GPx1 with a high rate, which is due to the great conservation between sequences. For instance, the second best alignment, which is really similar to the first one, correlates with GPx2. These results coincide with the initial hypothesis of the same evolutionary tree. Moreover, we have performed an alignment between the two GPx predicted in C. simum and they are coincident with slight differences, which means that there is a high conservation rate between both sequences. We also find an interesting hit with a scaffold that we have defined as SelI, and doing the correspondent sequence alignment between the original queries, we are able to identify certain homology in certain domains, but more likely due to the big size of SelI, which will generate a larger number of outputs but not specific alignments. Indeed, the common domain might be conserved in other selenoproteins.
Surprisingly, we found three unassigned hit using that query, located in the scaffold gi|398922855|gb|JH767759.1| and gi|398922892|gb|JH767757.1 and gi|398921984|gb|JH767785.1. We have searched those domains in the NCBI database using as a query the cDNA sequence and the target the genome of Ceratotherium simum in a blastp program. Which is consistent with the literature, where some pseudogenes in GPx1 were described, for instance by Diamond et al.
Finally, with GPx1 of both human and mouse we were able to find some of the others members of GPx family as expected due to the conserved domain along the different selenoproteins (especially GPx3).
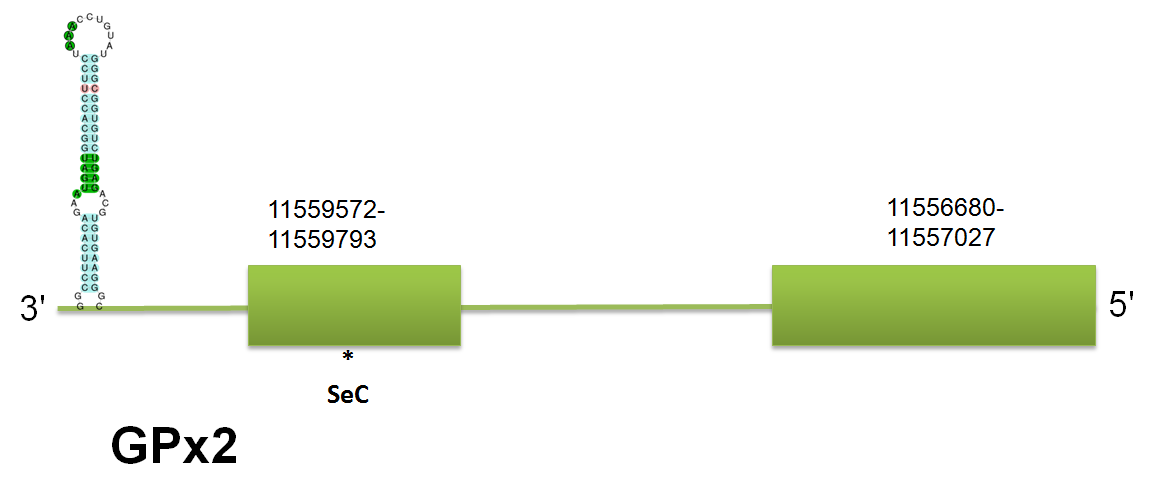
The selenoprotein GPx2 is located in the scaffold gi|398923836|gb|JH767740.1 between positions 11556680 to 11559793 on the reverse strand. In this case, we were able to predict exactly the same position and the same scaffold with the three queries used: mouse, human and horse, probably due to the great conservation of the sequences. Click here to see the gene structure. Moreover, the results are consistent with the ones found with the GPx1 query, which can also be explained by the homology between queries.
The structure of the protein predicted consists of 2 exons. The length and characterization of the exons is exactly equivalent in the three models: human, mouse and horse. Interestingly, the size of the exons is similar to the ones predicted for GPx1. Click here to see the multiple sequence alignment among the predicted protein and other mammals'. The prediction of Selenoprofiles, using a mouse GPX2, is exactly the same as we predicted. However, the Genewise program does not work properly, probably because it was not run with the option exhaustive or due to functionality of the program. Seblastian has predicted a selenoprotein with one selenocysteine in the fastasubseq and two SECIS elements. Of those, one is located in the forward strand, therefore we won't examine it. The other one, a SECIS element of grade A, is located between the 11556391 and 11556455 on the reverse strand, and the free energy of structure is -25, which means that this structure is thermodynamically stable.
As happened before with GPx1, we were able to found other hits using the three queries, the most important of which is GPx1, and the other are some selenoproteins of the GPx family, and the same unassigned hits that we will discuss.
{kind=link}
{kind=link}
GPx3, GPx5 and GPx6
The selenoprotein GPx3 is located in the scaffold gi|398923363|gb|JH767748.1 between positions 261641155 and 26171448 on the reverse strand. The predictions are coincident with the different query system used. The structure of the protein predicted consists of four exons. Click here to see the gene structure.
Our prediction shares identity with the output of Selenoprofiles, which shows the same structure and localization. Interestingly, and linked with the phylogenetic tree of the GPx family, Selenoprofiles used as a query the GPx6 from Sus scrofa. It is important to take into account that GPx6 evolved from GPx3 as a result of duplication prior to placental mammal separation. Click here to see the multiple sequence alignment among the predicted protein and other mammals'.
As happened before in GPx1 and GPx2, Genewise was not able to produce any consistent output. Seblastian has predicted one selenocysteine and one SECIS element, comprised between 26163437 and 26163511 on the reverse strand, with a total length of 74 bp. The free energy of the structure is -15.76, which means that it is thermostable.
In relation with the number of hits, we were able to find several hits, the most important of which was the one that later on we associated with GPx5, also consistent with the phylogenetic tree. Moreover, we were able to found two unassigned hits, one of which was present as well in GPx2 and GPx1 and the other one is gi|398925389|gb|JH767724.1. Being able to find GPx5 with a good hit while using a GPx3 query is due to the origin of GPx5 and 6 from GPx3, which is moderately old. Its stability to subsequent rearrangement over a billion years suggest shared upstream promoter and regulatory elements difficult to separate with retention of functionality. Probably, the GPx5 selenocysteine was displaced by cysteine after duplication, even prior to divergence. This phenomenon is not shown as clear in GPx6, because both forms, with Sec and with Cys, are described.
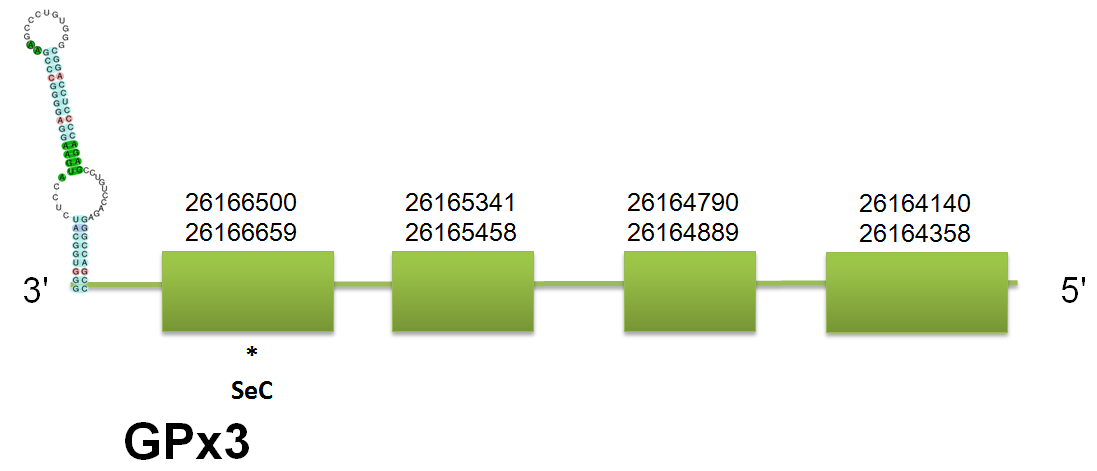
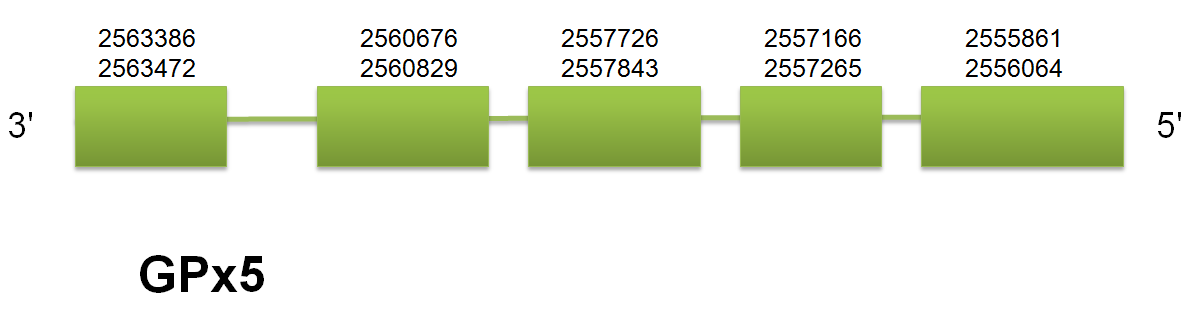
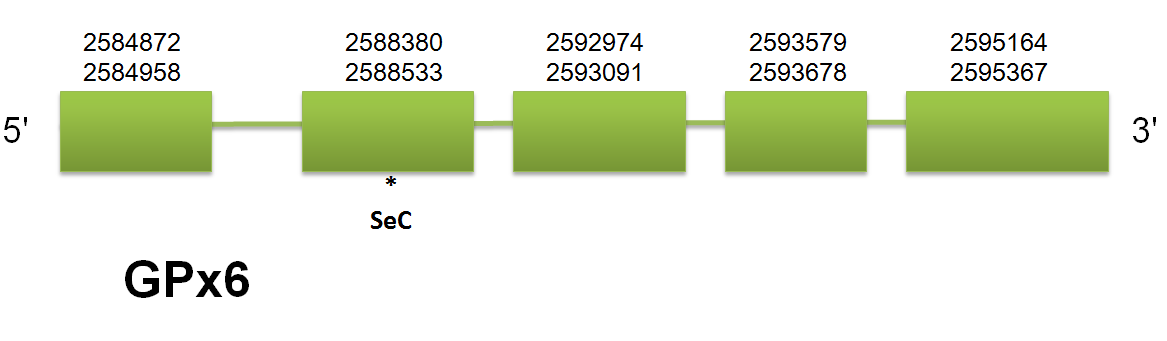
Concerning to GPx5 and GPx6 location, our program find out one problem to predict the correct position of these genes. Both proteins are generated as a result of tandem duplication of GPx3, and this phenomenon makes the localization of both genes on the same scaffold but on different strands. Therefore, the hits obtained by blast contain both genes in one single scaffold, thus modifying the fastasubseq obtained and making difficult to exonerate the prediction of genes. For that reason, the exonerate predicts two different genes, one in the forward strand and the other on the reverse strand, which leads to a bad t_coffee alignment. In order to solve the problem, we modified the blast hits to remove the ones that were on a different strand in order to make easier the prediction with a shorter fastasubseq. This will not avoid the double prediction of exonerate, for that reason we will choose only one of the two genes and follow the program with only that gene in order to obtain the good t_coffee alignment. Thereby, we obtained the real localization of both GPx5 and GPx6: GPx5 and 6 are both located in the scaffold gi|398920810| gb JH767833.1|.
GPx5 is comprised between 2555864 and 2563472 on the reverse strand. These results are consistent in the three species analyzed. The structure predicted consists of a total of 5 exons and 4 introns, also consistent in the three models. Click here to see the gene structure. No selenocysteine was predicted by Seblastian, but two SECIS elements both located on the reverse strand were found. Click here to see the multiple sequence alignment among the GPx5 predicted protein and other mammals'.
GPx6 is comprised between 2584872 and 2595364 on the forward strand. These results are consistent within the three models. We have predicted a structure of 5 exons. Selenoprofiles has predicted GPx6 in the forward strand, using a GPx6 query, that goes from 2584872 to 2595367, with a total of 5 exons, and it is able to predict the selenocysteine, which means that in C. simum there is not cysteine homologue as happens in mouse but selenocysteine. Click here to see the gene structure. Seblastian did not predict any selenocysteine, although it has predicted several SECIS elements in both strands. Selenoprofiles has not predicted any GPx6.
With all this data, we are able to reassert the evolutionary theory proposed before, which explains the evolution from GPx3. No unassigned hits were detected in those proteins.
An important fact to highlight in the query selection is the phenomenon that our query system has covered all the possibilities concerning the prediction of GPx6. GPx6 has been described as a selenocysteine-containing protein, but in some cases, for instance in mouse, rabbit or marmoset, it has suffered a conversion to cysteine. With our query system we guarantee that both options are analyzed, because both human and horses have the selenocysteine, but mouse has an homologous cysteine. Click here to see the multiple sequence alignment among the GPx6 predicted protein and other mammals'.
{kind=link}
{kind=link}
{kind=link}
GPx4, GPx7 and GPx8
The selenoprotein GPx4 is located in the scaffold gi|398920950|gb|JH767828.1 between positions 4786047 and 4788142 on the reverse strand, found only with human queries, because neither horse nor mouse queries were found. Its structure consists of 7 exons. Click here to see the gene structure. With Selenoprofiles we have predicted the same scaffold but a different protein structure. We suggest two possibles explanations: 1) GPx4 has specific isoform or 2)the differences could be explained by the problems we had running the Selenoprofiles against GPx family.
The Selenoprofiles output was a predicted protein consisting of three exons on the reverse strand, comprised between 4786546, and 4787062. Although the localization along the genome is similar, the structure is not the same. At this point, it is important to realize that our prediction starts with an exon with Met, whereas the Selenoprofiles prediction does not start with it, possibly meaning that is not the first exon but the second one. Moreover, in our prediction we have more gene length, leading to a larger protein size. We suggest that the Selenoprofiles prediction is restricted to the central domain of the protein, hence missing the start and the end of the protein in C. simum.
Another possible option would be that the Selenoprofiles has predicted a pseudogene, because GPx4 has some pseudogenes described. However, with our data (they share scaffolds) we are not able to demonstrate this. Seblastian protein prediction consists on one selenocysteine and a structure of six exons. Although we have not used Seblastian to predict proteins structure, in this case we use it to be sure that our suggestions were meaningful. About SECIS elements, it only predicts one SECIS of grade A comprised between 4785917 and 4785989, with a total length of 72 bp. Genewise does not give any consistent output.
To conclude the discussion of the structure predicted, it is important to highlight that GPx4 is the most conserved protein, with about 90% of conservation, thus meaning that possibly the prediction with one single query, the one obtained from human and well-annotated, will be the most accurate. Therefore, we suggest that the real structure of the protein is closer to the one we have predicted that the one predicted by Selenoprofiles using a BLAST MASTER QUERY -in this case it could not be the best option-. Click here to see the multiple sequence alignment among the GPx4 predicted protein and other mammals'.
Concerning to the hits obtained with the human GPx4 query: two of the hits are GPx7 and GPx8, which is consistent with the evolutionary theory presented before. The other two hits are the ones that correspond to GPx1 and GPx2, which also is consistent with all the data explained, because they are conserved Gpx. No unexpected hits were found here.
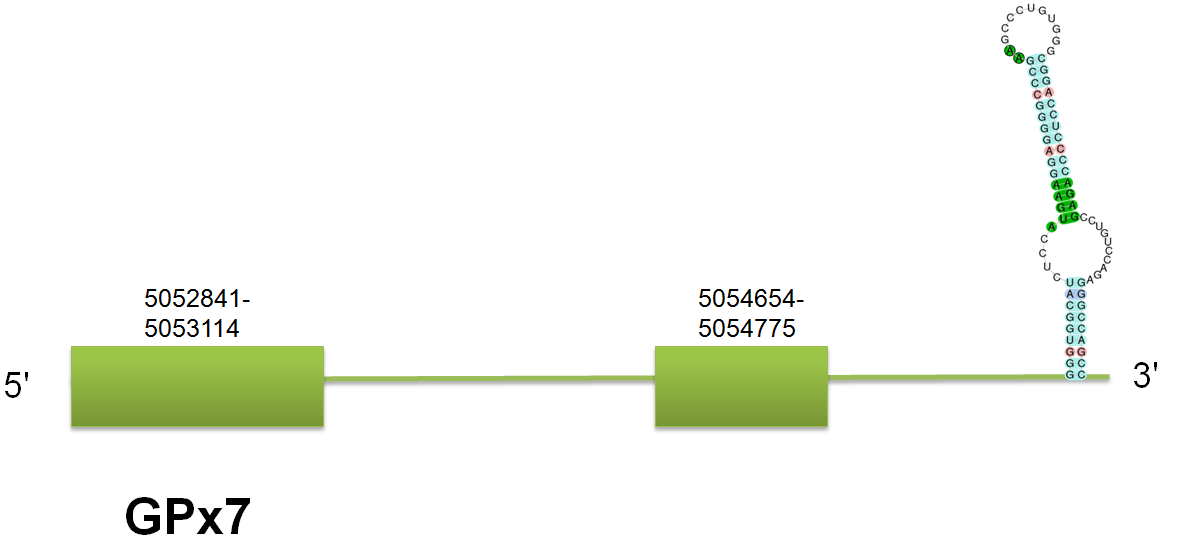
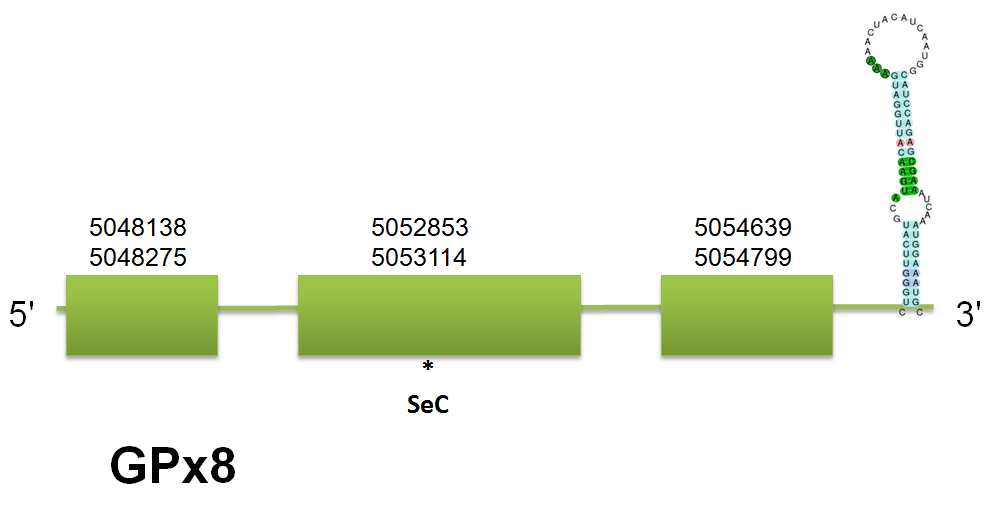
The selenoprotein GPx7 is located in the scaffold gi|398921711|gb|JH767796.1 comprised between 5048138 and 5054799 on the forward strand. We have predicted a protein consistent of 3 exons in human, whereas there are some differences in mouse and horse. Click here to see the gene structure predicted with the human query. We suggest that these differences could be explained by a possible isoform or, more probably, to a problem in the query acquisition in mouse and horse. No Selenoprofiles output was obtained as a consequence of the bug we had. Tne Genewise results correlates with our results. No selenocysteine was predicted by Seblastian as expected. Click here to see the multiple sequence alignment among the GPx7 predicted protein and other mammals'.
The selenoprotein GPx8 is located in the scaffold gi|398924304|gb|JH767731.1 comprised between the positions 29270945 and 29275470 on the forward strand. Two different protein structures have been predicted: 3 exons by the human query and 2 exons by the horse one. Click here to see the predicted gene structure with the human query. No mouse query was available. As happened in GPx7, we were able to predict two distinct protein structures, possible due to a bad annotation or to the presence of isoforms. Click here to see the multiple sequence alignment among the predicted GPx8 protein and other mammals'. The others hits obtained with both GPx7 and GPx8 coincide with GPx4 and GPx7, as we expected.
To conclude the GPx family analysis, we have performed a whole family alignment. Click here to see the multiple sequence alignement among the different predicted members of the GPx family.
Interestingly, with the multiple alignment of the sequences found for GPx4, 7 and 8, we are able to observe the three large deletions in GPx4, GPx7 and GPx8 in relation with other GPx. The deletions occurred once in the common ancestral sequence to GPx4 and GPx7 and 8 and have been described before. Furthermore, we are able to identify the homologous domains of the family, conserved in all of the members.
{kind=link}
{kind=link}
{kind=link}
| Protein | Selenocystein | Exonerate | Genewise | T-Coffee | SECIS | Seblastian | Selenoprofiles |
|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
The unidentified element 1 detected in the GPx family is located in the scaffold gi|398925635|gb|JH767723.1|, where we also found SelI, however we consider that the separation between both is enough to consider them unrelated sequences. Interestingly, the hit we have obtained in the exonerate and in the t_coffee alignment has two good regions: one which is coincident with the exon 1 of GPx1 and the other one coincident with the last exon, with a relative high conservation rate. Thus, we could suggest that this unidentified element is a result of a duplication. Once detected, we have search the genome of the C. simum in order to find any change in start codon or in stop codon. Therefore, using the in-frame read proposed by exonerate we were able to find an interesting phenomenon: there is an ATG in-frame at 14 codons from the predicted origin, which would make possible that the protein is actually codified. However, in the same in-frame read and a few codons after the initial codon, we have found one stop codon, which possible will be the reason why this sequence is not expressed.
Thus, we suggest that we have found partial duplication of GPx1 gene. We would like to add that more research is needed to understand why there are some regions better conserved than others, thus possible meaning that there is some evolutive pressure. In the multiple sequence alignment, where the first sequence is the GPx1 detected and the second the unidentified element partially duplicated, we can see how the first part of the domain is conserved, as we have expected due to the fact that the duplication stands for the first exon. Interestingly, there is another conserved region at the end of the alignment, and we presume it is consistent with the last exons. Interestingly, we have generated one fastasubseq and ran a Seblastian, and we have detected one SECIS element. From this we can extract two possible conclusions: that the duplication has included some 3'-UTR region, including the SECIS element, or that the SECIS element predicted has nothing to do with the pseudogene and it is a result of the low threshold of acceptance for SECIS elements. Finally, our search in NCBI databases has lead to the conclusion that this domain found could only be present in GPx family members, thus being consistent with our theory. Click here to see the multiple sequence alignment among the predicted protein and the unidentified element 1.
The unidentified element 2 detected in the GPx family is located in the scaffold gi|398922855|gb|JH767759.1|, where no other protein has been detected in that region and, moreover, only members of the GPx family were able to find this element. When analyzing the exonerate, we can see that our identification is restricted to one specific domain of the protein. Specifically, we have seen that this domain is coincident with the first exon of GPx1, although the rate of conservation is much lower than the one observed in the previous situation. This can mean two things: that it has occurred a partial duplication in that gene and due to the lack of selective pressure we have lost some homology or that this domain is from another member of the GPx family. Click here to see the multiple sequence alignment among the predicted protein and the unidentified element 2.
The unidentified element 3 described in the GPx family by using the GPx2 query is located in the scaffold gi|398925389|gb|JH767724.1, where no other protein has been detected. Analyzing the exonerate we can see that we found one good region of homology between the positions 51 and 173 of the query sequences. Thus, we are probably predicting a domain of GPx2 which has been duplicated. Moreover, as we can see analyzing the t_coffee, this domain is highly conservated in one concrete region. This region is coincident with most part of the exon 2 and a small part of the exon 1. However, we were not able to detect any intron -at least using exonerate as we have performed-. We are not sure if there is a lack of power of our predicting system or a case of processed (retrotransposed) pseudogenes, which are described to be intronless. Concerning to the structure of this unidentified element, we were not able to find any start codon -at least not after a codon stop that we have detected a few codons before the ORF predicted by the exonerate-, therefore we are not able to asses if we have an in-frame sequence able to be translated. When performing the alignment beween this pseudogene predicted and the real GPx2 found in C. simum we can see that the alignment is almost the same than the one using the query and the pseudogene, thus meaning that there is a high homology between query and GPx2 predicted in C. simum. We have found also a SECIS element, which can be explained by the same two theories explained above.Click here to see the multiple sequence alignment among the predicted protein and the unidentified element 3.
The undefined element number 5 is located in the scaffold gi|398922892|gb|JH767757.1|, where no other protein have been described. This element was only predicted using the GPx queries, and after examination of the NCBI database we suggest that these domains are only found in GPx family, thus being consistent with our results. When analyzing the exonerate file, we can see that the homology is found in most of the query sequence, thus meaning that the conservation is extended on almost all the protein. This can be confirmed by the t_coffee alignment, where we can see that there is a lot of conserved domains in our sequence of interest, not only one. Thus possible meaning that we are facing a pseudogene event not a duplicaiton.
Interestingly, the Selenoprofils program has found the same hit using the blast master query, which means that the conservation is high enough. Surprisingly, we have found a selenocysteine. This phenomenon is totally unexpected. Usually, pseudogenes are not involved in evolutive pressure, and therefore they tend to mutate randomly, thus losing even the functional parts. Moreover, the synthesis and addition of selenocysteine to a protein is difficult and expensive. With this data, we are able to suggest two main theories:
- We have found a pseudogene of GPx1 which has a high rate of conservation in all the regions but the first one, even in the selenocysteine residues. This can be explained by a relatively recent generation of the pseudogene, and we expect a further lost of the selenocysteine and the conserved structure.
- We have predicted other GPx family member, or a different isoform of one of the GPx predicted for some reason in a different scaffold localization.
Finally, we have performed an alignment between the GPx1 predicted in C. simum and our pseudogene_5, and we can see a really good homology in all the sequence but the beginning. This phenomenon could have changed the in-frame read, thus generating a non-codified protein, but we cannot confirm it. Click here to see the multiple sequence alignment among the predicted protein and the unidentified element 5.
MsrA
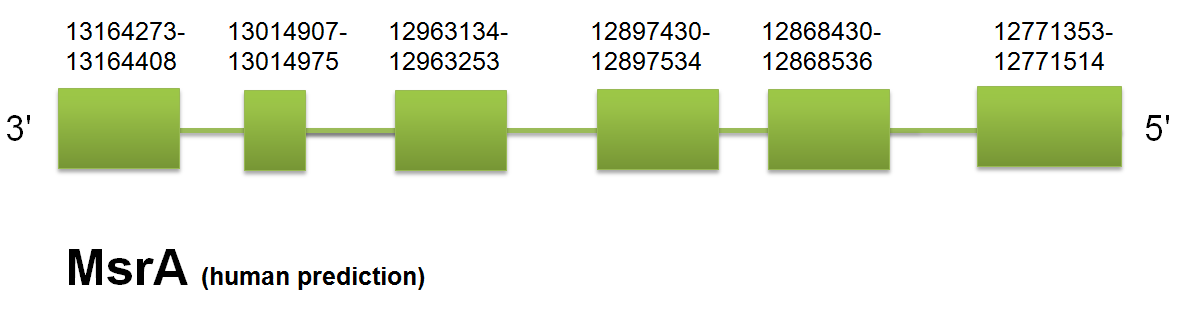
The selenopotein is located in the scaffold gi|398922613|gb|JH767767.1| between positions “13014907” and “12771353”. On the reverse strand. The predicted gene for MsrA contains 4 introns and 5 exons. Click here to see the human gene prediction.
In this case the query selected was the horse one. The human and the mouse proteins were predicted with 6 exons and 5 intron, while horse had an exon in the beginning that in horse were not present. We had selected as correct the horse one with the support of Selenoprofiles and the major phylogenical proximity between horse and the C. Simum. Both present equivalent results and this helps us to select this prediction as the correct one.
However in this process Seblastian was unable to determinate the presence of a selenocistein even though the literature says that this protein presents one. When we look through Selenoprofiles MSRA has a selenocystein in the second exon. The question here is where is the problem, if in our program (and Seblastian) or in Selenoprofiles. The outpout of Genewise is not relevant, it did not worked properly in MsrA. It is not easy to arrive to a conclusion in this case. Due the high homology between the queries we cannot easily say that they are wrongly annotated. To determinate the answer and define the correct one we were obliged to go through the literature, and its here were Selenoprofiles has the chances of winning, in the literature it seems evident that the presence of selenocystein is common in major mammals.
The different proteins predicted are homologous up to a certain point, as we can see in the tcoffee the homology differences are found in the first exon which matches with the conclusions reached previously. Click here to see the multiple sequence alignment among the different predicted proteins.
The element SECIS predicted by the horse is a grade B and it starts at the 13021256 position, and ends at the 13021331 position.it has an free energy of -18,95. Click here to see the multiple sequence alignment among the predicted protein and other mammals'.
MsrA is a repair enzyme that reduce methionine sulfoxyde residues in cell stress situations. Its role is directly related with delaying the aging process, and the degeneration due oxidative reactions. They are a important point in actual study for their relation with various diseases. Enzymatically his activity is significantly improved when it has the selenoprotein structure (a selenocystein in the active site), and has been used a lot to determinate the importance of selenocystein in redox enzyms.
{kind=link}
Sel15
The selenoprotein SEL15 is located in the scaffold gi|398920364|gb|JH767859.1 between positions “1868259” and “1905106” on the forward strand. In this case we have predicted two different proteins: one with mouse and horse and another with human query. Click here to see the multiple sequence alignment among the different predicted proteins.
We have found two diferents proteins acording to the used query, the human one gives an output with 3 exons and 2 introns all the other methods (seblastian, selenoprofiles, genewise and mouse/horse outputs of our program) presents a structure of 5 exons and 4 introns. Click here to see the gene structure predicted with the human query. This difference can be explained by the presence of an isoform in human, or due a variation of the protein in the phylogenical variation distance, as human is the more distant to C simum we can accept that the data obtained from everything except the human is the most provable.
Using seblastian with the equs input (the mouse one works good also) we obtain a selenocistein in the second exon. The secis element is a grade A, it starts at 1,905,696 and ends at the position 1,905,773, with a free energy of -20.36. The Sel15 found in C simum also shows high identity with the majority of mammalian annotated Sel15 “Click here” to see multiple sequence alignment.
This proteins shows high homology between placental mammals, as we can see in the next alignment. Click here to see the multiple sequence alignment among the predicted protein and other mammals'.No pseudogenes nor unassigned hits nor duplications have been predicted.
SEL15 is a thioredoxin-like, endoplasmic reticulum-resident protein related with the control of the glycoprotien floding proces. It works through its interaction with Udp-Glucose. Another interesting fact is that SEL15 is related to cancer, it is known that selenuium has a role in cancer prevention due to this position in a genetic locus normaly mutated or delated in cancer. Mutations on this gene affect the interaction with selenium uptake and are related with the etiology of cancer.
{kind=link}
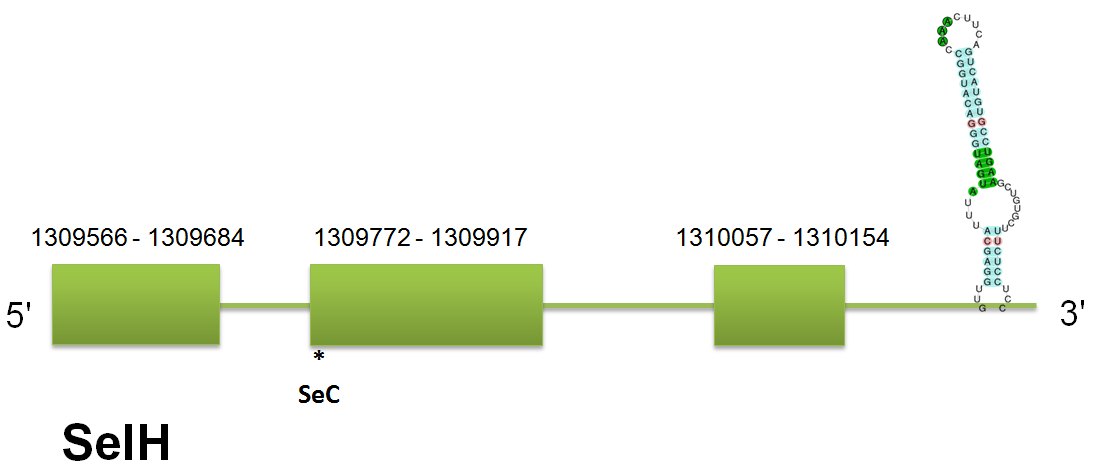
SelH
The selenoprotein SelH is located in the scaffold gi|398921812|gb|JH767791.1| between positions “1309566” and “1310154” on the forward strand in the Ceratotherium simum. The predicted gene for H.sapiens query contains 2 introns and 3 exons. Click here to see the gene structure. This prediction is the same using the three queries, Selenoprofiles and Genewise. So we can arrive to conclude that this is the protein in Ceratotherium simum. It is true that if we analyze the exons of the different queries they present little variations, as 18bp. But these differences can be explained by the lack of conservation of certain domains among the three proteins that have been used as query for this prediction. We have found that the predicted proteins are almost identical, showing just several differences in particular regions. Then, we consider that these different hits correspond to the same protein.
Click here to see the multiple sequence alignment among the different predicted proteins.
Using seblastian we obtain a selenocistein in the second exon. The secis element is a grade A, it starts at 1,311,040 and ends at the position 1,311,106, with a free energy of -14.1. The SelH found in C simum also shows high identity with the majority of mammalian annotated SelH. Click here to see the multiple sequence alignment among the predicted protein and other mammals'. No pseudogenes nor unassigned hits nor duplications have been predicted.
SelH Is one of the ancestral vertebrate selenoprotein which seems to be found in all vertebrate. This protein presents a Trx like fold, with an intranuclear position that can act as a transcription factor due to his capacity to bind to DNA. His function is related to the antioxidant protection against H2O2 by increasing the mitochondrial biogenesis and the CytC production. It also reacts to redox variations facilitating synthesis of genes related to de novo production of GSH, and related with phase II detoxificaction. A up regulation of other selenoprotein in stress situtations is also enhaced by SelH.
{kind=link}
| Protein | Selenocystein | Exonerate | Genewise | T-Coffee | SECIS | Seblastian | Selenoprofiles |
|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
The undefined element is located in the scaffold gi|398924001|gb|JH767737.1| where no other proteins where predicted. These elements consists of a total length sequence of 271, although only 83 pb are predicted by the query. This presents an interesting scenario: there are a lot of gaps but no one considered as an exon, maybe because there are not any splice sites detected by exonerate. For that reason, if we assume that the exonerate prediction is correct, this protein will be codified all together, thus containing non-functional parts that will eventually made the protein non-functional. When analyzing the SelH protein, we are able to find a structure of three exons: the first of which is separated from the second by a distance of 87bp, then the second and the third exon are separated by an intron of 139bp. Having said that, what we have found in our undefined element is a structure that starts at the beginning of the second exon and then follow all the sequence, missing the second intron. When aligned both sequences (the query and the undefined element) we are able to detect a high rate of conservation in those two exons (although in the undefined element they are considered as a single exon). Here, we suggest that we are facing a pseudogene, as the structure exon/intron is degenerated and the sequence is presumably in-frame.
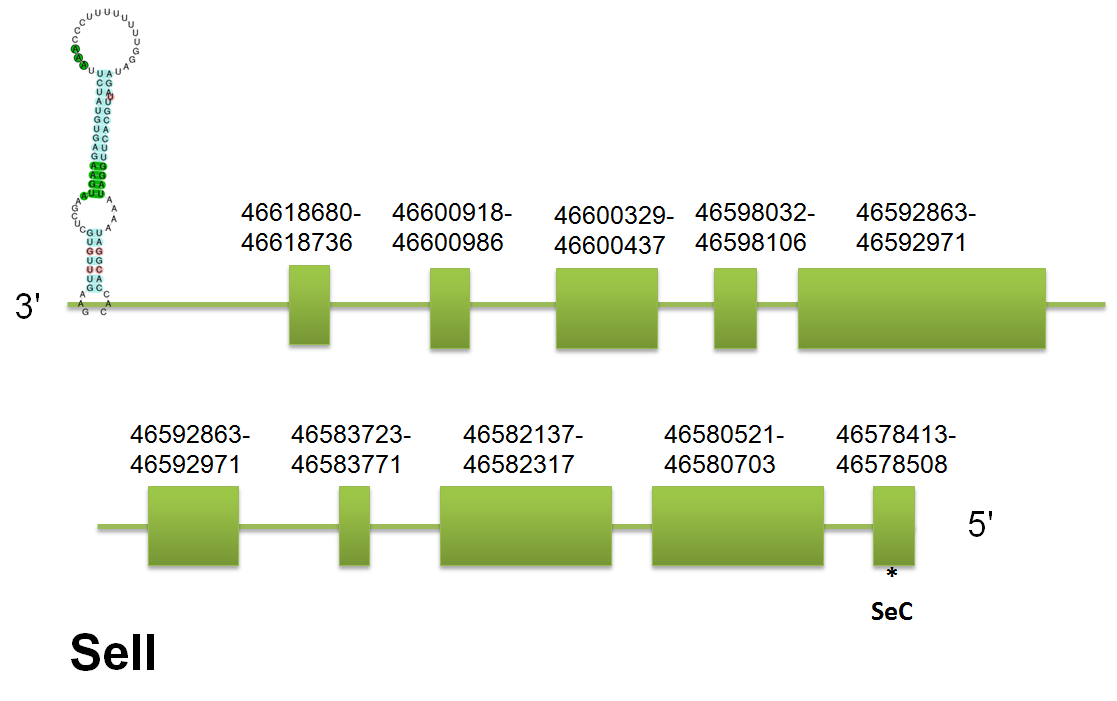
SelI
The selenoprotein SELI is located in the scaffold gi|398925635|gb|JH767723.1 between positions “46618680” and “46578413” on the reverse strand. The predicted gene for H.sapiens query contains 9 introns and 10 exons. And this intron/exon structure is highly preserved in the three predicted proteins. Click here to see the gene structure.
We have found the same predicted protein using human, mouse and horse protein sequence as well as using Selenoprofiles. Here Genewise did not make a corrrect output. This can be explained by the high similarity between the three queries. Click here to see the sequence of the predicted protein.
In this case Seblastian omits the presence of the first exon, and in their output we have 9 exons, in order to confirm if we can find a selenocistein in this exon we can look through Selenoprofiles. The results of Seblastian and Selenoprofiles share the same position for the selenocistein in the last exon, so the first exon must be free of selenocistein. The Secis element predicted is a Grade A, it starts at the position 46577086 and ends at 46577009. It has a free energy of -5.71.
If we compare the queries of the different mammals used and the final query predicted the homology obtained is high. Click here to see the multiple sequence alignment among the predicted protein and other mammals'.
This selenoprotein is expressed in the cell membrane, but his function remains unclear.
{kind=link}
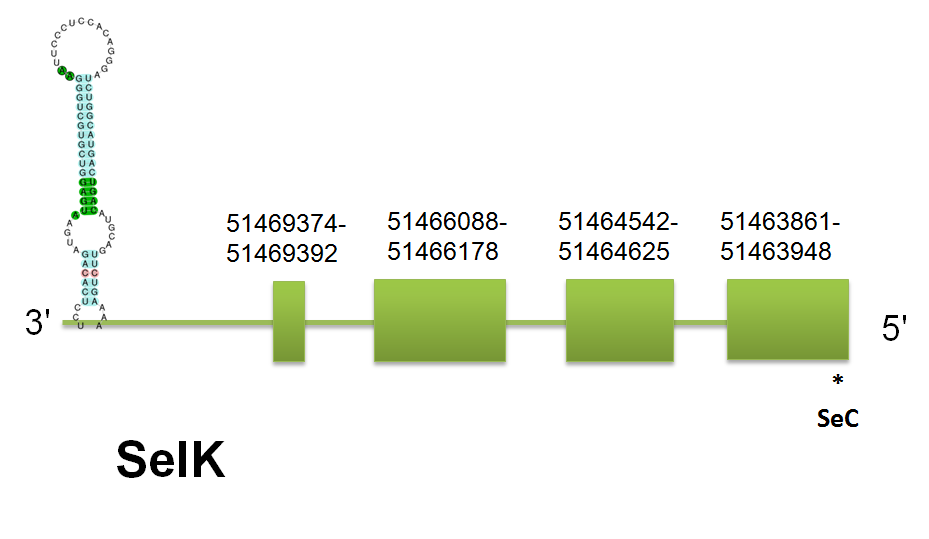
SelK
The selenoprotein SelK is located in the scaffold gi|398925264|gb|JH767725.1 between positions “51463861” and “51469392” on the reverse strand.The predicted gene for H.sapiens query contains 3 introns and 4 exons. This exon/intron structure is mantained in mouse and Equus. Click here to see the gene structure.
We have found the same predicted protein using human, mouse and horse protein sequence as well as using Selenoprofiles. Genewise did not give a correct output. Click here to see the sequence of the predicted protein. This stability (even with the usual malfunction of genewise) can be explained by the high similarity between the three queries. The output obtained with Seblastian says that SELK has one selenocistein in the fourth exon. Furthermore the Secis element predicted can be found in the position 51,463,460 an ends at the position 51,463,385. The free energy of this Secis element is -15,03.
In the same scaffold we can find Gpx1 and also SelT, SelT starts at 1,000,000 bp and 47,000,000 bp in the case of Gpx1. Far away of the 51,463,861 bp of the start position of SelK. So we can conclude that they are different proteins.
When we analyze the homology between the different species (tcoffe) we can see that the homology is really high for the three initial mammalian queries (versus the one predicted). Click here to see the multiple sequence alignment among the predicted protein and other mammals'.
This Selenoprotein is a litlle bit especial beacause is the Selenoprotein analyzed with most pseudogenes and isoforms detected. One fact that could justify is that we have a stop codon in an exon with an splice site, this can increase the translation and produce this variations.
{kind=link}
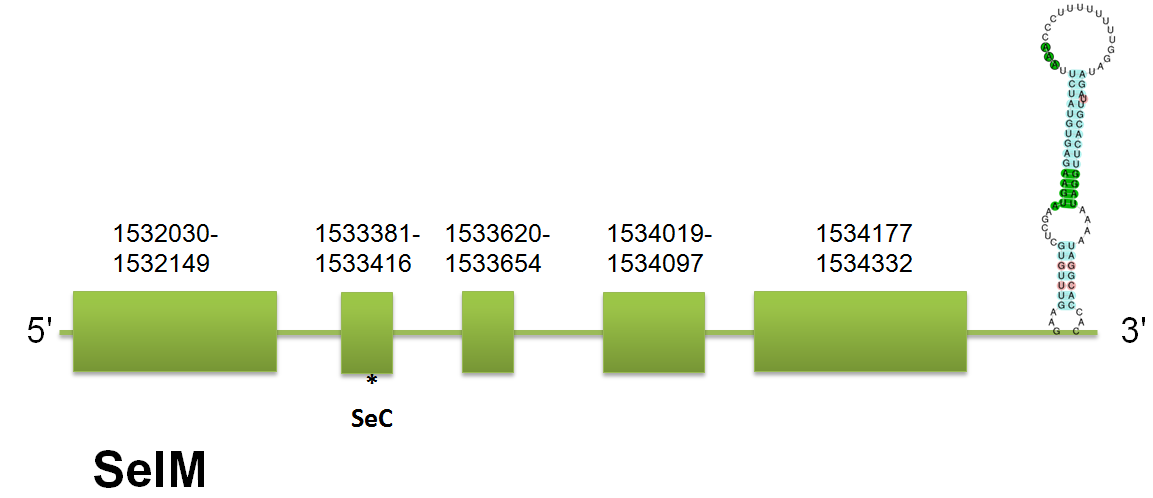
SelM
The selenoprotein Sel M is located in the scaffold gi|398923055|gb|JH767752.1| comprised between positions 1532030 and 1534332 on the forward strand. These results are coincident in the queries of human and horse, but not in mouse, that has 27 pb more in his first exon.Click here to see the multiple sequence alignment among the different predicted proteins. This could be explained by the lack of conservation of certain regions among the proteins that have been used as query for this prediction. The structure of the protein predicted consists of 5 exons and 4 introns, consistent on the three queries. Click here to see the gene structure.
Regarding to Selenoprofiles, we have obtained the same profile: 5 exons located in the correspondent region. Genewise output is unconcluded and does not provide reliable information. Seblastian has predicted one selenocysteine in the 2nd exon and SECIS element grade A comprised between 1534278 and 1534439. It has a free energy of -21.67. No unassigned hits were obtained.
The homology between different mammalian species shows that predicted C. simum’s SelM present a high identifies with horse, mouse and human queries of Sel M. Click here to see the multiple sequence alignment among the predicted protein and other mammals'.
Sel M is an eukaryotic selenoprotein and is expressed in a variety of tissues, with increased levels in the brain. It is localized to the perinuclear structures, and its N-terminal signal peptide is necessary for protein translocation. It seems to play a role in protecting neurons from oxidative stress.
{kind=link}
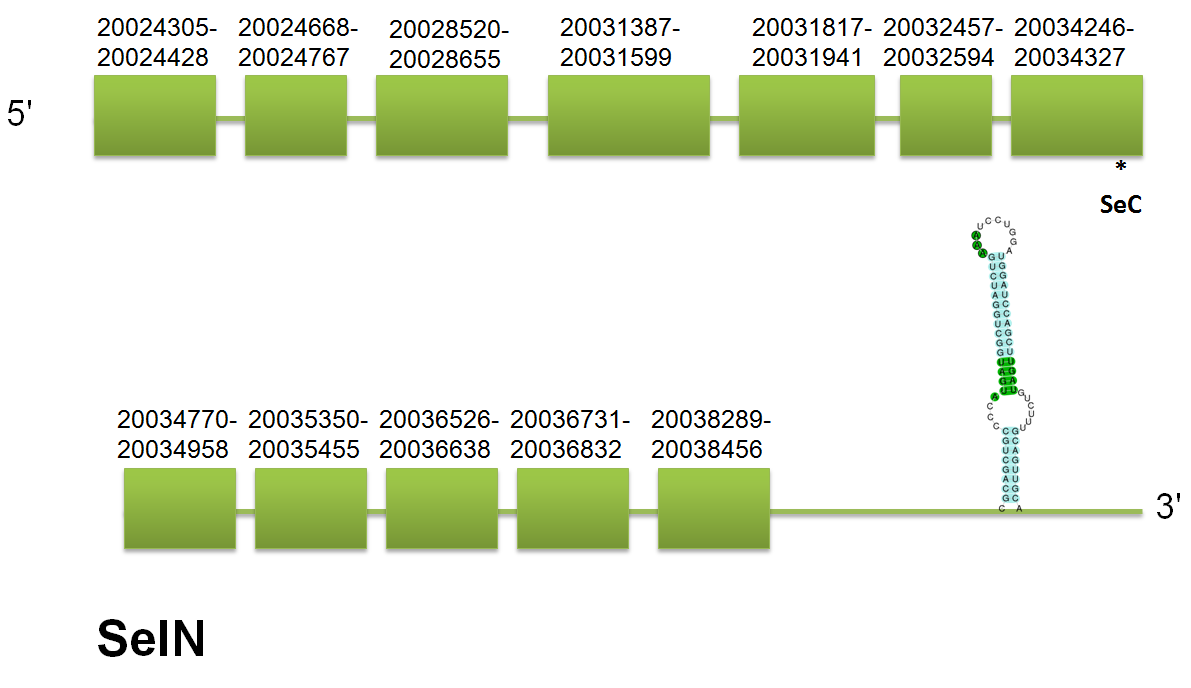
SelN
The selenoprotein SelN is located in the scaffold gi|398923877|gb|JH767739.1| comprised between positions 20024305 and 20038456 on the forward strand. These results are coincident in the three queries of human, mouse and horse.
The protein predicted by the H.sapiens query consists of 12 exons. Click here to see the gene structure predicted using the human query. We have found that the predicted proteins have a different gene structure depending on the query used. The prediction using horse and mouse has 11 exons, 1 less than using H. sapiens. We can observe that this extra exon in H. sapiens has only 99 pb and is located between 1st and 2nd exon of Equs. It is possible that in horse and mouse, this region has been recognized as part of the first intron. However, These differences between human and the other analyzed species also could be explained by the lack of conservation of certain domains among the proteins that have been used as query for this prediction. We have found that the predicted proteins are almost identic, showing just several differences in particular genomic regions.Click here to see the multiple sequence alignment among the different predicted proteins.
Using Selenoprofiles, we have obtained the same exon prediction than using mouse and horse queries. We were not able to assess if the protein with an exon more, predicted by the H. sapiens query was actually an isoform, although it could be possible, as different isoforms have been described in other organisms. Expression analysis will help to find out the isoforms present in C. simum. In the same way, the prediction using Genewise also presents 11 exons. Seblastian has predicted one selenocysteine in the 4th exon and a SECIS element grade A comprised between 20.039.567 and 20.039.634. It has a free energy of -28.9. No unassigned hits were obtained.
The homology between different mammalian species in SelN sequence is high as we can see the next alignment. Click here to see the multiple sequence alignment among the predicted protein and other mammals'.
We can observe that, the scaffold id of SelN is also present in others selenoproteins: Sel U3, Secp43. Even so, the start-point of these is different, so we can conclude that they are different proteins.
SelN is a eukaryotic selenoprotein expressed in skeletal muscle, heart, lung and placenta. It seems to play an important role in congenital myopathy.
{kind=link}
SelO Family
Researchers have found, by using bioinformatics tools, the three-dimensional structure of SelO, which appears to be similar to the protein kinase folding. However, there is no conservation of the His-Arg-Asp motif typically found in kinase. Therefore, they suggest that SelO might have retained catalytic phosphotransferase activity in an atypical active site. Thus, the role of the selenocysteine residue has been largely discussed.
In most eukaryotes and many bacteria, SelO is present as a single-copy protein, while duplicate copies in many metazoans.
When talking about SelO there is an interesting phenomenon. Some studies suggested that the common ancestor of Metazoa had a duplicated SelO-like gene, but this duplication is lost in some lineages such as primates, rodents and other mammals lineages. Moreover, the different SelO are not good conserved. Here, we will discuss SelO, and we will suggest the presence of a SelO.2 in C. simum although not much is found in the literature.
SelO1
The selenoprotein SelO1, defined as the homologous found in both human and mouse and horse, is found in C. simum located in the scaffold gi|398921791|gb|JH767792.1| on the forward strand comprised between 11562147 and 11608610 . These results are consistent with the three queries used. Actually, the three queries are really similar, thus explaining why the results are so correlated.
The protein predicted with our data consists of 10 exons and 9 introns using the human query. Click here to see the gene structure predicted with the human query. However, using the two other queries we have obtained a slight diversity in the number and positions of the exons. With horse we were able to find the same 9 exons than in human but we miss the 10th, probably due to the big intron which separate both of them -up to 34000 bp-. Thus, could be that the real protein include the 10th exon and the exonerate with the horse query has not ran properly. It could also be that this gene present some isoforms, but we are not able to prove this hypothesis. Concerning to the prediction using the mouse query, we have found that the protein predicted has two more exons located downstream in the genetic sequence. However, it does not start with Met and it is located 27000 downstream in relation with the first exon with human and equs prediction. Here we can see the alignment of the different proteins predicted. Click here to see the multiple sequence alignment among the different predicted proteins.
Selenoprofiles has predicted a 10 exon protein structure starting on the same exon as the human prediction. However, it ends before the big intron described, thus considering the protein 30.000 shorter. The main difference between our prediction and the Selenoprofiles one resides in the fact that Selenoprofiles consider the intron length of only 69 introns whereas our programs considers the intron longer than 30.000. We are not able to assess if this is because of the presence of different isoforms or because a lack of power of the programs used.
Finally, Seblastian has predicted a protein similar to the one predicted with the mouse query: with 12 exons, the two first before the first detected by the human query, and finishing just before the long intron described. It has detected one selenocysteine located in its last exon. Moreover, it has found one SECIS element on the forward strand, comprised between 11574597 and 11574667, and it is classified as a SECIS element grade A. Click here to see the multiple sequence alignment among the predicted protein and other mammals'.
{kind=link}
SelO2
In the literature we have found that both human and rodent have lost the SelO2 form. However, horse, our third element in the query system, has conserved SelO2, and for that reason we ran our program with both horse queries in order to discover if C. simum has conserved or not the protein.
First of all, is important to notice that even with the human and mouse query, which correspond to SelO1, we were able to find a relative good hit in the scaffold gi|398923956|gb|JH767738.1|. However, the alignment was not enough good to conclude nothing, and actually the scaffold coincide with the one obtained for SelR2. The position of the gene predicted with that queries correlates with the original SelO2 gene. In order to resolve our doubts, we annotated the second query found in Equus in Seleno DB 2.0 (the query does not specify the type of SelO we are using) and we ran our program. Surprisingly, we found a very good hit which we suggest is SelO2 that is conserved in C. simum and not in human and rodents.
The selenoprotein SelO2 is located in the scaffold gi|398923956|gb|JH767738.1| comprised between 9193800 and 9204259 on the forward strand. It does not contain any selenocysteine, as it happens with the horse query. The structure predicted consists of 8 exons on the forward strand. Click here to see the predicted gene structure.
Seblastian has not predicted any selenoprotein, so in this case we have a cysteine-containing selenoprotein, as happened in horse as said previously. However, it has predicted two SECIS elements. The one located on the forward strand is classified as a SECIS of grade B and it is found between 9186856 and 9186930, with a free energy of -7.81. Interestingly, we were not able to find a good hit of SelO2 using the queries of SelO of human and mouse because this protein is poorly conserved.
{kind=link}
| Protein | Selenocystein | Exonerate | Genewise | T-Coffee | SECIS | Seblastian | Selenoprofiles |
|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
We have found and undefined element when searching against SelO, located in the scaffold gi|398923956|gb|JH767738.1|, where other proteins have been detected but not near this new one. Interestingly, and probably due to the great size of the SelO query, we have found different exonerates predicting different domains, separated for non homologous sequences, probably introns or exon regions mutated. When analyzing the exonerate, we are able to predict three different elements that exonerate assume as different. The first one consists of what resembles a protein: a structure with three exons and two introns. This phenomenon highlight an important fact: this protein has a conserved structure/intron structure, with splice sites and other elements that in some cases are lost in the evolution of pseudogenes. This can mean that the pseudogen has arose early in the evolution. The other two files obtained from the exonerate are different domains of the SelO located at a distance enough that the exonerate consider as different outputs. However, all of them together maintain homology with some concrete regions of the SelO protein. Selenoprofiles has predicted as well a protein there, with its own exon structure similar to the one we have predicted -variability in considering pseudogenes cannot be avoided due to the lack of consensus domains in those rapidly evolving regions-. However, we suggest that the prediction is consistent with our own prediction because the introns it has predicted extend longer than 60.000bp. Therefore, what we are predicting is different domains conserved in that concrete region more than a complete protein. To conclude, we suggest that what we have here is not a complete pseudogene but a several domains duplication, as we can see clearly in the t_coffee alignment, where only three domains are correctly aligned and all the other show an empty alignment.
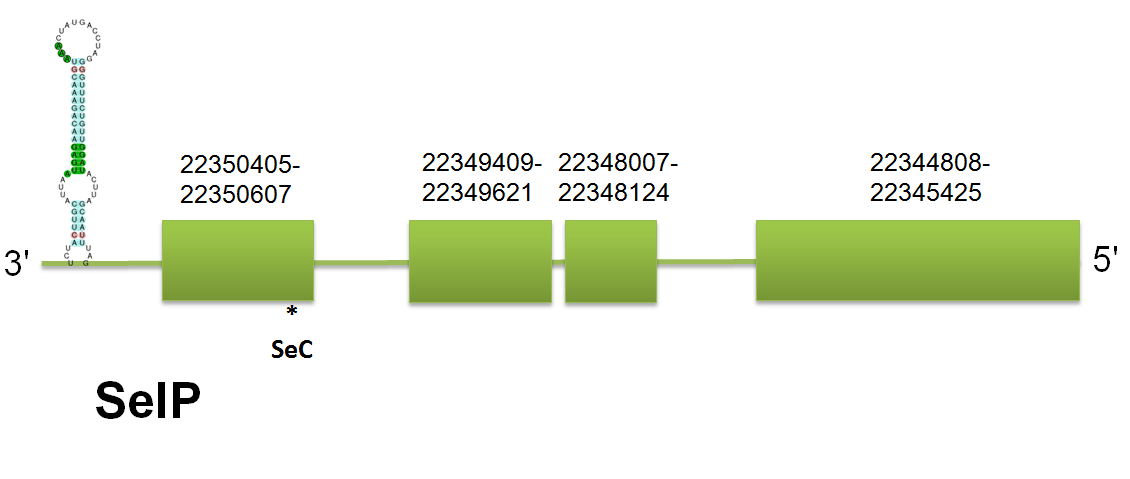
SelP
In C. simum, SelP is located in the scaffold gi|398924304|gb|JH767731.1| comprised between 22344808 and 22350607 on the reverse strand. These results are coincident with the three queries system used. Click here to see the sequence of the predicted protein. To see the predicted protein sequence. SelP in C. simum consists of 4 exons, being the 4th one the longest and the one that contains the most of the selenocysteines present (a total of 13 in C simum), whereas the first exon contains the other selenocysteine, the one found in the N-terminal region. It is important to take into account that the exon prediction is on the reverse strand. Therefore, our program has predicted 14 selenocysteines in the C. simum SelP using the three systems of queries. Click here to see the gene structure.
Regarding to Selenoprofiles, the protein predicted has also 4 exons. However, the length predicted for the 4 exon is smaller than the one predicted with our program, thus leading to the prediction of SelP with only one selenocysteine by Selenoprofiles. These phenomenon could be explained by two main events: 1) Selenoprofiles has predicted another isoform of SelP or 2) Selenoprofiles has missed a great part of the exon because there are up to 14 different stop codons in this sequence and maybe it has considered one of them as the real stop codon. To conclude, we are not able to assess if it is a different isoform, because expression data is required, but we suggest that the SelP present in C. simum has at least 14 selenocysteines. Genewise does not output any proper result.
When aligned the sequence predicted with the queries used, we can see that there are several domains conserved, specially the first ones which contain the N-terminal part of the protein an is the most conserved one. However, this really good homology is not found in all the sequences, being the last domains the more variable, although they are similar. This is consistent with the fact that the C-terminal part is more variable and contains a lot of selenocysteines that depends on the lineage are converted to cysteine or not. Click here to see the alignment. Click here to see the multiple sequence alignment among the predicted protein and other mammals'.
Concerning to Seblastian, the exon/intron structure predicted is the same as our prediction -the same number of exons with the same extension- and the exact number of selenocysteines. About the SECIS elements, we have found two good SECIS elements as expected (although in our Results table we haven't include both of them because there is not enough space). The first one is comprised between 22344475 and 22344546 on the reverse strand, with a total length of 71 and defined as a grade A SECIS element. The other SECIS element is located between 22344035 and 22344098, on the reverse strand as well and classified as a grade A SECIS element. No unassigned hit nor pseudogenes detected.
SelP is a secreted protein made up of 2 different domains: the N-terminal domain which contains one selenocysteine while the C-terminal contains the other 9 selenocysteines in H. Sapiens. However, it exhibits variation in the total number of Selenocysteine presents in other mammals, thus suggesting that not all the selenocysteine described are useful for the SelP function. Some isoforms have been described, although not well-characterized. Interestingly, SelP is involved in the general homeostasis of selenium.
The N-terminal domain contains the motif UxxC, which is shown in several selenoproteins and is though to be important in selenoprotein functionality due to its relation with redox reactions. Some studies suggest that the repetitive selenocysteine is generated as a succession of changes in the in-frame sequence, thus leading to the acquisition of new selenocysteines due to the high proportion of codon stop UGA sequences.
Due to its abundance of selenocysteine, SelP has arose a high interest. It has been described two SECIS elements with different functions. Hence, SECIS 2 is thought to carry out the insertion of the first selenocysteine whereas the SECIS 1 is thought to process the others selenocysteines with a greater efficiency. The great difficult in SelP synthesis will possible allow the presence of several isoforms, which will need to be described by expression analysis.
{kind=link}
SelR Family
In the literature the SelR family it's seen as only one protein. SelR is a member of the methionine sulfoxide reductase family and works in the process of reduction of the sulfoxymethil group. So it reduces the Methionine-R-Sulfoxide to Methionine. SelR is present in all the animals (except some parasites) and it presence is related to the presence of MsrA. It arrives to be clustered or fused with this gene, and this fact suggests that they can be involved in the same function. In this case we find huge evidences of convergent evolution, because both proteins did not present any homology. We had tried to define the viability of this premise we can compare the position of both. More information will be found in the SELR2 discussion. Click here to see the multiple sequence alignment for the predicted members of the SelR family.
SelR1
The selenoprotein is located in the scaffold gi|398921774|gb|JH767793.1 between positions “10103490” and “10107147” on the forward strand. The predicted gene for H.sapiens query contains 3 introns and 4 exons. Click here to see the predicted gene structure with the human query.
We have found that the predicted proteins have a different gene structure. The same protein was predicted using human and horse protein sequence as well as using Genewise. On the other hand selenoprofiles found 3 exons. The predicted protein with mouse query contains 2 introns and 3 exons and the predicted protein with horse query contains 2 introns and 3 exons. Click here to see the multiple sequence alignment among the different predicted proteins.
So here we have a dilema: the last exon present in human and in Genewise is delated in Selenoprofiles and in Horse.
To save this we start by comparing the queries, and the results show that they are homologus. The next step is to start analyzing the fastasubseq. The exon present in human, but lost in all the other methods, is the last one. If we look after the 3rd exon (the last exon present in all the methods) we find a codon STOP (TGA). This codon stop represents the limit of our proteins but with the human query this codon stop is avoided . This fact can suggest the presence of an isoform. Our data, and the presence of TGA, suggest that Ceratotherium Simum has the protein as is presented by horse prediction, mouse prediction and selenoprofiles. Seblastian predicts a Selenocistein in the 3rd exon. The element Secis (grade A) starts at 10107591 position, and ends at the 10107661 position. This element has a free energy of -21,24.
The homology between the queries is high due the similarity between them. Furthermore the homology between the predicted proteins is also really evident. We also find significant homology in this protein between mammals. Click here to see the multiple sequence alignment among the predicted protein and other mammals'.
{kind=link}
SelR2
The selenoprotein SELR2 is located in the scaffold gi|398923956|gb|JH767738.1 between positions “12339589” and “12327517” on the reverse strand. The predicted gene query contains 4 introns and 5 exons. In this protein, our program predicts the exon/intron structure with 4 exons and 3 introns. However when we search in the literature, SELR family present a selenocistein in their structure, but with our system we were not able to determinate this amino-acid. In order to avoid this limitation we use Selenoprofiles, and the output obtained with this program shows a selenocistein in a exon that others methods omit. This 5th exon is vital in the analysis of this protein,and this omission leads to the mistakes obtained with Seblastian (lost of the selenocistein) and the protein prediction program (wrong exon/intron structure). Click here to see the predicted gene structure.
In this case we choose the Selenoprofiles result even if the three outputs obtained with mouse,human and horse were really homologous. This decision has a important impact in the methodological process because it represents the obligation to have an state of art of the protein studied. Without reading the paper we would be blind against the omission of the exon, and the better results obtained with Selenoprofiles will be rejected. The three queries used have a high homology, however this data (and also the homology between the predicted proteins) is irrelevant due hat our program did not predict the correct protein. The query that give the correct output is one from the Selenoprofiles database.
We were not able to define if the limitation was on the queries used in our program (low probability due the high homology between them) or a limitation of threshold of acceptation of our program (and also seblastian). SELR2 presents a SECIS element Grade B. It starts in the position 12361154 and ends at the 1336123, with a free energy of -7.44. We have found additional hits for SELR2 in the SELR3 region too. This fact is not surprising due to the high similarity between the different members of the SELR family.
Another theoretical information that can be analyzed in this discussion is if the presence of a cluster formed by MsrA and SelR is plausible. This premise starts with a certain proximity in the genome, this is not so strict because the DNA is not in a lineal form but we cannot asses this in other terms. As we find SelR2 in the 12339589 position and MSRA in the 12771353 position, the difference is 443,928bp. This data suggest that the possibility of a cluster is real. Is an important distance, but in the immensity of the genome they are close. This is a great example about the possibilities of our program, and defines the importance of a human interpretation of the data obtained.
Click here to see the multiple sequence alignment among the predicted protein and other mammals'.
{kind=link}
SelR3
The selenoprotein SelR3 is located in the scaffold gi|398923229|gb|JH767750.1 between positions “22093863” and “22254999” on the forward strand. The predicted gene for H.sapiens query contains 5 introns and 6 exons. “Click here” to see the representation of the gene structure. Click here to see the gene structure.We have found the different proteins by using human, mouse and horse querys as using Selenoprofiles and Genewise. Click here to see the multiple sequence alignment among the different predicted proteins. These differences can be explained by the lack of conservation of certain domains among the three proteins that have been used as query for this prediction.
Seblastian did not predicted any selenocistein, but it did predicted one SECIS element, to confirm if it is a mistake in Seblastin we can look at Selenoprofiles, and there we can found a selenocistein in the last exon and this is the output that we will accept. The SELR3 found in C simum also shows high identity with the majority of mammalian annotated SELR3. “Click here” to see multiple sequence alignment. Click here to see the multiple sequence alignment among the predicted protein and other mammals'.
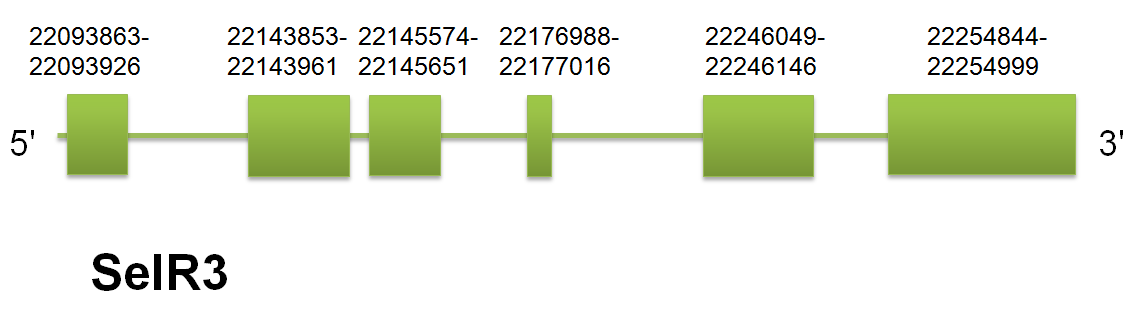{kind=link}
| Protein | Selenocystein | Exonerate | Genewise | T-Coffee | SECIS | Seblastian | Selenoprofiles |
|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
We have found one unassigned hit using SelR2 query, located in the gi|398923006|gb|JH767753.1|, where no other proteins were described close to it. The actual length predicted by the query range is up to 107 bp, however the total prediction by exonerate arrives to 247 bp. This phenomenon is due to the fact that exonerate is not able to distinguish any intron in the sequence (bare in mind that the lack of introns can be an indicator of pseudogenes presence, as a result of the degeneration of the splice sites as they are not evolutive selected). Interestingly, what we have found in SelR2 predicted protein is an structure similar in length -introns not included- and there are some domains repeated. However, the main difference resides in the detection of introns in the predictes SelR2 sequence that we are not able to predict in the pseudogene. Moreover, if we look at the t_coffee alignment we can see a high rate of conservation between the query and the pseudogene sequence, although the first part of the query remains unaligned -it has not found any result consistent, as happened with SelR2-. When compared both sequences, the predicted for SelR2 and the one we suggest is a pseudogene, we can observe a pretty good alignment in the initial and medium part, and an empty alignment in the final part. This is explained by the fact that SelR2 has a longer alignment with the query and thus a longer protein predicted. Click here to see the multiple sequence alignment among the predicted protein and the unidentified element 5.
SelS
The selenoprotein SelS is located in the scaffold gi|398922816|gb|JH767761.1 between positions “4238447” and “4245796” on the forward strand. We have considered it as a selenoprotein because exonerate has detected a selenocysteine. However, it could also be that this selenocysteine was actually a stop codon, as it is the last codon of the protein. The predicted gene for H.sapiens query contains 5 introns and 6 exons. Click here to see the gene structure. We have found the same predicted protein using human and mouse, but our horse results were very different. After checking the queries we found that the human and the mouse queries that we were using were quite alike, while the horse's one was absolutely different to them. Click here to see the multiple sequence alignment among the different predicted proteins.
Due to the phylogenical proximity between C simum and horse (bigger with ther other queries), the fact that the horse results were incorrect was not an easy acceptable premise, and we had to find more elements to support the hypothesis of a wrong annotation. To validate the hypothesis we used Seblastian, which output was extremely helpful for us. Seblastian uses for SelS his database of queries, and we were lucky to see that the query used was a Horse one. The exon/intron structure was equivalent to the mouse/human one and this evidence is excellent for us because we thanks to it we can ensure that the annotation of horse is wrong. If the query used for Seblastian was different from horse, and more distant than horse in phylogenical distance this hypothesis will remain unclear, but in this case Seblastian saved us.The genewise results were equivalent, and support our theory.Click here to see the multiple sequence alignment among the predicted protein and other mammals'.
We have found different predicted proteins using Human/Mouse/Seblastian versus the horse one. We have found that the predicted proteins have a different gene structure. The predicted protein with mouse/human query contains 5 introns and 6 exons and the predicted protein with horse query contains 6 introns and 7 exons. The selenocystein is located in the last codon of the last exon of the protein. Thus, we have considered SelS as a selenoprotein although it is also possible that the last selenocysteine, in fact, was not a selenocysteine but a stop codon. This is one of the limitations of exonerate.
The SECIS element is A grade and it starts in the 4246183 and ends at 424625, his free energy of -5.93. No pseudogenes nor unassigned hits nor duplications have been predicted. Click here to see the multiple sequence alignment among the predicted protein and other mammals.
It is a selenoprotein located in the ER membrane that has key function in the retrotranslocation of misfolded proteins of the ER membrane by being a component of the ERAD (Endoplasmic-reticulum-associated protein degradation). It has an important relation with inflammatory diseases due his up regulation related to cytokines. The inflammatory process lead to a release of SelS from the liver. Polymorphisms in the SelS gen or machinery of expression had been described as an increased risk of inflammatory diseases due the plasma increase of inflamatory cytokines, such as TNFalfai IL-1beta. SelS has an anti-apoptotic role and reduces ER stress in peripheral macrophages and brain astrocytes.Finally a polymorphism in the promoter of Sels is directly linked to gastric cancer.
{kind=link}
SelT
The selenoprotein SelT is located in the scaffold gi|398925264|gb|JH767725.1 between positions 1063951 and 1068578 on the reverse strand in two out of three exonerates, because using the mouse SelT as a query we found an extra exon which will stretch out the sequence to 1085317 (on the reverse strand). As the T_coffee evaluation seems coincident, it is possible that the real protein contains an extra exon.
The predicted gene for H.sapiens query contains 3 introns and 4 exons. Click here to see the gene structure. This prediction is exactly the same that the one obtained from horse query. However, the one predicted with mouse is slightly different, because it contains an extra exon, which makes the predicted protein longer, resulting in 5 exons and 4 introns. These results also correlate with the ones obtained from Genewise, meaning that the differences observed between querys depend on the query and not the program. Click here to see the multiple sequence alignment among the different predicted proteins.
According to Selenoprofiles, we have predicted the same protein structure than the one predicted by the mouse query, with 5 exons located between 1063951 and 1085317, according with a query obtained from Gallus gallus. The same number of exons is seen in Seblastian, which predicted not only a SECIS element located between 1063298 and 1063372 but also selenocysteine located on the second exon.
All the data above suggests that SelT might have some different isoforms, as previously described in other organisms. The possible presence of different splicing mechanisms will lead to a different read of the proteins hence a different number of exons. The introduction of a new exon leads to early stop codons and different frameshift patron. We were not able to confirm the different splicing isoforms.
In this multiple alignment we can see the differences observed and the regions with higher conservation. It is important to notice that SelT has been described as one of the most conserved selenoproteins but in some cases the presence of an extra exon can lead to differential splicing mechanisms.“Click here” to see the multiple sequence alignment of the different predicted proteins.
Interestingly, the scaffold that contains the SelT also contains the selenoprotein SelK and also contains the GPx2 selenoprotein.
No pseudogenes nor unassigned hits nor duplications have been predicted.
Click here to see the multiple sequence alignment among the predicted protein and other mammals'.
{kind=link}
SelU Family
Mammals contain three Cys-containing SelU proteins (1 to 3). These are supposed to have evolved from fish sequences that contain all selenocysteine, although some studies were not able to find evidence that supports an early Sec to Cys-containing conversion for SelU2 and SelU3 proteins. Thus, in eukaryotic lineages SelU is widely distributed in both forms, Cys or Sec containing. While mammals, land plants, arthropods contain a Cys, fish, birds and echinoderms are Sec-containing.
Interestingly, the Sec –if present- is located near to a conserved Cys to allow the formation of a CxxC motif, present in various thiol-dependent redox proteins, as well as in some selenoproteins such as SelW, SelV or SelT. No SelU homologue is present in prokaryotes.
When compared the three different proteins predicted for SelU1, SelU2 and SelU3 in a t_coffee alignment we can see that there are few conserved domain between them, probably due to the fact that SelU separation has ocurred long ago, thus generating divergent evolution of the sequences. This is consistent with our results, where we were not able to find the other SelU members using a concrete SelU query, meaning that the homology has been reducing over the time. Click here to see the multiple sequence alignemnt among the different members of the SelU family.
SelU1
The selenoprotein SelU1 is located in the scaffold gi|398922712|gb|JH767764.1 between 20448371 and 20458468 on the reverse strand and do not have any selenocysteine but a cysteine, as expected in all mammals. We have found the same hit using both horse and mouse queries.
The structure of the predicted protein by the H.sapiens query consists of 5 exons. Click here to see the gene structure. The prediction using horse and mouse share the same number of exons with small differences in length (up to 5 bp). These differences can be explained by the lack of conservation of certain domains among the three proteins that have been used as query for this prediction. Click here to see the multiple sequence alignment among the different predicted proteins.
Regarding to Selenoprofiles, we have obtained the same profile: 5 exons located in the correspondent region above-mentioned. When using Genewise, we cannot detect the predicted protein. This could be due to differences in the way of working of the different programs or because we didn't use the exhaustive option with the Genewise program.
Seblastian has predicted no Sec-containing selenoprotein but a SECIS element grade B comprised between 20477135 and 20477206. However, it is placed on the forward strand, whereas the gene is on the reverse, which means that the SECIS element predicted is not related to our protein of interest.
No unassigned hits were obtained, although with the human query we were able to find SelU3, but not SelU2, thus suggesting that the homology between the different members of the SelU family is low.
{kind=link}
SelU2
The selenoprotein SelU2 is found in the scaffold gi|398921072|gb|JH767820.1|on the reverse strand, comprised between the positions 6872668 and 6880637 on the reverse strand. All our predictions show a gene of 6 exons. Click here to see the gene structure. We have predicted different proteins acording with the different querys used. Click here to see the multiple sequence alignment among the different predicted proteins.
The structure of the predicted protein consists of 6 exons and 5 introns, consistent on the three queries. Click here to see the gene structure. This can be seen in the next t_coffee alignment, where the protein predicted is run against the protein in horse, human and mouse, and we can see a high level of conservation in all the sequence but the first part, which is slightly more variable.Click here to see the multiple sequence alignment among the predicted protein and other mammals'.
Surprisingly, Selenoprofiles was not able to generate a good output, nor did Genewise, and Seblastian did not find neither selenoproteins –there is no Sec as we previously explained- nor SECIS elements. No unassigned hits were obtained.
{kind=link}
SelU3
The selenoproten SelU3 is located in the scaffold gi|398923877|gb|JH767739.1| comprised between the positions 1504325 and 1507002 on the forward strand. These results are coincident in mouse and in human, but not in horse due to the lack of query on the databases. The predicted proteins are different acording with the used query. Click here to see the multiple sequence alignment among the different predicted proteins.
The predicted protein has 6 exons located in the forward strand. The gene predicted with the mouse query has the same first 6 exons and a seventh one, located as well in the forward strand between 1507512 and 1507535. Interestingly, when we analyze the fastasubseq, we are able to find the 6th exon in humans followed by a stop codon but not in frame, according to the prediction of exonerate.
Regarding to Selenoprofiles, we have obtained the same exon prediction than in mouse, exactly in the same region and with the presence of the 7th exon on the forward strand. We were not able to assess if the protein with the 7th exon was actually an isoform, although it could be possible as different isoforms have been described in other organisms. Expression analysis will help to find out the isoforms present in C. simum. Genewise output relevant results that are consistent with what we have previously discussed, with the difference that it was not able to predict the 7th exon using the mouse model. Seblastian does not predict any Sec nor SECIS element, as expected.
The alignment of the mammalian SelU3 (human, C. simum and mouse) shows a high rate of conservation between sequences, even in the final part, although the C.simum protein predicted by human query lacks the seventh exon, thus meaning either that the exon is really small or the mouse query does not contain that exon although it find it on C. simum. Click here to see the multiple sequence alignment among the predicted protein and other mammals'. Neither unassigned hits nor pseudogenes detected.
SelV
The selenoprotein SelV is located in the scaffold gi|398920895|gb|JH767830.1 between positions 1582451 and 1585968 on the forward strand.
The predicted gene from the Homo sapiens query contains 3 introns and 4 exons. We didn’t find an annotation of SelV in SelenoDB for horse and mouse. However, we found interesting predictions from Equus caballus and Mus musculus SelW placed in the same scaffold (gi|398920895|gb|JH767830.1). Those predictions emerged from a second hit for SelW and they showed low scores in the T-Coffe analysis. Furthermore, a second prediction from Selenoprofiles for SelW was also placed in the same scaffold. Interestingly, that prediction used a SelV as a query. This proteins present some differences on their structure that we will discuss in the following words. Click here to see the sequence of the predicted protein.
First of all, it is important to know that SelV has been described in the literature as the least conserved selenoprotein in mammals, what can explain why the scores obtained in the T-Coffe analysis are relatively low. It presents the same gene structure than SelW, probably because it appeared from a duplication of SelW, it contains 5 introns and 6 exons. Coding regions are within exons 1–5. Exon 6 contained only the last portion of the 3′-UTR, including the SECIS element. Exon 1 presents significant variation while exons 2-4 are better conserved through the phylogeny (Mariotti et al, 2012).
We conclude from our results that the gene prediction from Homo sapiens contains only the exons 2-4, the conserved ones and the same happens with the Mus musculus prediction. It is remarkable to point that exonerate shows a second gene prediction were the first exon –corresponding with exon 2 of SelV- is splitted in two different exons. It is plausible that exon 1 couldn’t be found with those phylogeneticcaly-distant organisms due to its variability. Supporting this idea, the gene prediction from Equus caballus contains 5 introns and 6 exons; including exon 1, probably because Equus caballus is a very closer organism with Ceratotherium simum in the phylogeny. Selenoprofiles was also able to find this non-conseved exon 1 and it contained the splitted version of exon 2, also found by exonerate from the human query.
In conclusion, SelV is not a high-conserved protein, for this reason it was difficult to predict the right gene structure from our queries but much evidence supports that is composed of 6 introns and 7 exons: exon 1 is un-conserved while exons 2-5 are much more conserved and consequently, more probably to predict. The last exon also presents prediction difficulties because it contains only the last portion of the 3′-UTR. The GeneWise analysis showed corresponding results, it was able to predict the 5 conserved exons but not exon 1 and 6 due to their variability. Even though SelV contains a SECIS element, Seblastian was not able to predict it. This happened because the exon 6 could not be predicted from and it is located on the 3'UTR containing the SECIS element.
As explained, the SelV is not a high-conserved selenoprotein amog the mammals. For this reason, the protein found in Ceratotherium simum showed low identity with the majority of mammalian annotated SelV. Click here to see the multiple sequence alignment among the predicted protein and other mammals'. No pseudogenes nor unassigned hits nor duplications have been predicted.
SelW1
The selenoprotein SelW1 is located in the scaffold gi|398921259|gb|JH767812.1 between positions 4946893 and 4947388 on the forward strand.
The predicted gene from the Homo sapiens query contains 2 introns and 3 exons. The same hit and structure was predicted using Equus caballus query. Predictions from Selenoprofiles, GeneWise, Seblastian and, surprisingly, Mus musculus query showed SelW1 located in the same hit but they presented slightly differences in the gene structure that can be explained analyzing previous literature. As described on SelV’s discussion, SelW contains 5 introns and 6 exons. Coding regions are within exons 1–5. Exon 6 contained only the last portion of the 3′-UTR, including the SECIS element. Exon 1 presents signifant variation while exons 2-4 are better conserved through the phylogeny (Mariotti et al, 2012). Click here to see the sequence of the predicted protein.
Homo sapiens and Equus caballus queries showed correlated results although they didn't predicted the complete gene structure for SelW1. Only the conserved exons -exons 2-4- from SelW1 were predicted. On the other hand, we obtained a common predicted structure of 4 introns and 5 exons using Selenoprofiles, GeneWise and Seblastian. Mus musculus prediction was almost identical; it presented 4 exons, skipping the very small exon 2. More evidence supporting this hypothesis is that for Homo sapiens and Equus caballus -the methods that didn't predict the highly-variable exon 1- the first aminoacid is not methionine indicating that this would be, actually, exon 2. On the other hand, the first exon of Selenoprofiles, GeneWise, Seblastian and Mus musculus predictions is initiated with a Methioine. Exon 6 was not found because it contains the last portion of the 3′-UTR ans consequently, it does not appear on the queries we used as a model for predictions.
For this reason, we don't accept the human query prediction as right. Although we conclude that SelW1 obtained from Selenoprofiles, GeneWise and Seblastian must be the correct one. In order to discuss SelW1, two predictions were used that are not showed in the results; corresponding to SelW from Equus caballus and Mus musculus. The annotation of SelW for those organisms was not specific between SelW1 and SelW2. Thus, only a SelW version was annotated. When using this protein as a query we predicted the same protein we did using human SelW1.
No pseudogenes nor unassigned hits nor duplications have been predicted. Click here to see the multiple sequence alignment among the predicted protein and other mammals'.
SelW2
The selenoprotein SelW2 is located in the scaffold gi|398922382|gb|JH767772.1 between positions 2756374 and 2757364 on the forward strand.
The predicted gene from the Homo sapiens query contains 3 introns and 4 exons. GeneWise predicted a protein with the same structre and located in the same genome region. Nevertheless, there are not annotations for SelW2 in selenoDB for Equus caballus and Mus musculus. The resulting hit for SelW2 was not found by any other query. Selenoprofiles and Seblastian could not predict a selenoprotein for SelW2. For this reason, we cannot ensure that the described structure is SelW2 due to a lack of supporting data. Click here to see the sequence of the predicted protein.
As described on SelV’s discussion, SelW contains 5 introns and 6 exons. Coding regions are within exons 1–5. Exon 6 contained only the last portion of the 3′-UTR, including the SECIS element. Exon 1 presents signifant variation while exons 2-4 are better conserved through the phylogeny (Mariotti et al, 2012).
The exons found with the human query and GeneWise correspond to exons 1-4 of SelW2; our hypothesis is that exon 6 was missed because it is the last portion of the 3'-UTR and it is not present in our queries. Click here to see the multiple sequence alignment among the predicted protein and other mammals'.
SPS family
Selenophosphate synthetase (SPS) is a family of proteins that catalyzes the activation of selenide with adenosine 5'-triphosphate (ATP) to generate selenophosphate. This is the essential reactive selenium donor for the formation of selenocysteine (Sec) and 2-selenouridine residues in proteins and RNAs, respectively. Some SPS are themselves Sec-containing proteins, like SPS1 and SPS2.1.
In vitro studies have been shown that SPS2 synthesized selenophosphate from selenide, whereas SPS1 may use a different substrate. Furthermore, it has been demonstrated that SPS2 knock down in cells culture using small interfering RNA cause the selenoprotein biosynthesis impaired, whereas knockdown of SPS1 had no apparently effect. Additionally, transfection of SPS2 into SPS2 knockdown cells restored selenoprotein biosynthesis, indicating that SPS2 is strongly related to the generation of selenium donor for selenocysteine biosyntehesis in mammals.
However, SPS1 function is not entirely defined. It was suggested to be responsible for Sec recycling. Same time, there are some studies that speculate about the implication of SPS1 in a new pathway of selenium utilization in animals.
Click here to see the multiple sequence alignment of the diferent predicted members in the SPS family.
SPS1
The selenoprotein SPS 1 is located in the scaffold gi|398923956|gb|JH767738.1 between positions 20834639 and 20834831 on the forward strand. These results are coincident in the queries of human and horse, but not in mouse due to the lack of query on the databases.
The protein predicted contains 8 exons and 7 introns. Click here to see the gene structure.
The prediction using horse and human, share the same amino-acid sequence with a difference in the 383 position: In Equus predicted sequence we observe a Serine residue, contrary in human predicted sequence there is an Asparagine residue. This could be explained by the lack of conservation of certain regions among the protein sequence. Click here to see the multiple sequence alignment among the different predicted proteins.
The prediction of SPS1 using Selenoprofiles presents 7 exons. We were not able to assess if the protein with 7 exons was actually an isoform, although it could be possible, as different isoforms have been described in other organisms. Expression analysis will help to find out the isoforms present in C. simum.
Concerning to genewise, does give a relevant result consistent with what we have previously discussed. It predicts 8 exons and 7 introns. Seblastian does not predict any Sec nor SECIS element, as expected.
We don’t have unassigned scaffolds. Click here to see the multiple sequence alignment among the predicted protein and other mammals'.
{kind=link}
SPS2
The predicted selenoprotein SPS 2 is located in the scaffold gi|398921556|gb|JH767802.1| between positions 3393846 and 3395177 on the reverse strand. These results are predicted by the human’s query. In horse, the positions of the predicted SPS2 are slightly differents, being this last 12 amino-acids bigger. We cannot predict SPS2 with a mouse’s query due to the lack of information of the alignment between mouse query and C. simum genome. Click here to see the multiple sequence alignment among the different predicted proteins.
The protein predicted contains only 1 exon. Click here to see the gene structure.. The prediction using horse and human share the same amino-acid sequence, with merely few differences in some positions, probably explained by a lack of conservation of genomic sequences among these mammalian species. We can observe that the sequence of Equus have 9 insertions, however Human has none. This fact also could explaine this longer sequence in horse.
Regarding to Selenoprofiles, we have obtained the same profile: 1 exon located in the correspondent region above-mentioned. When using Genewise, we can observe also only one exon, but we cannot detect positions of the predicted protein. This could be due to differences in the way of working of the different programs or because we did not use the exhaustive option with the GeneWise program.
Seblastian has predicted one Sec-containing Selenoprotein and a SECIS element grade A comprised between 3393199 and 3393274 and it has a free energy of -21,67. Click here to see the multiple sequence alignment among the predicted protein and other mammals'.
{kind=link}
TR family
Thioredoxin reductase (TR) has been identified as the redox-active lipid-hydroperoxide-detoxifying selenoprotein.
As expected, the family alignment has enlightened the evolution of the TR. As we have predicted, the latest exons show greater homology than the first ones, less conserved, thus probably meaning that the functional site is found there. Moreover, although they are not exactly the same disposition, it is conserved in some way (as we have expected because we were able to predict the 3 different TR using each of the queries alone). Click here to see the multiple sequence alignment for the diferent predicted member of the TR family.
TR1
The selenoprotein TR1 is located in the scaffold gi|398925635|gb|JH767723.1| comprised between the positions 28356442 and 28397580 on the forward strand. There are some differences between the human prediction and the mouse prediction. One possible explanation can be found in the queries used. Click here to see the multiple sequence alignment among the different predicted proteins. As we can see in this query alignment, the mouse query is larger, probably as a result of a larger protein, which will mean that protein predicted will be longer as well. However, apart from that beginning, the sequence is conserved.
The variability in the prediction is mainly found in the first part of the protein, where the mouse predicted sequence is longer than the human one, as we can see in the multiple alignment presented here. Interestingly, the last part of the protein is highly conserved, probably due to the fact that the selenocysteine is located there, thus meaning that the functional part of the protein is found in the last exon. For this reason, we can prove that variations in the sequence are restricted to the less functional areas, whereas the functional parts containing Sec are highly conserved. Moreover, we can see that the predicted protein using the human query starts with a Met but so does the mouse prediction, being both good indicators of protein start. However, we cannot reject the isoform hypothesis.
Our protein predicted consists of 13 exons using the human query and a total of 14th with the mouse query, being the exon added at the start of the gene, as discussed before. Click here to see the gene structure predicted with the human query. Regarding to Selenoprofiles, we have predicted a slightly different protein structure, more similar to the mouse one but still different. It has output a protein consisting of 16 exons on the forward strand, with the same end as we have previously described –where the selenocysteine is placed- but a variable beginning, consistent of three extra exons. Interestingly, the query name of Selenoprofiles is from human, which makes more confusing the different protein prediction. We suggest that both prediction are able to capture the major part of the protein, and possibly we are facing different isoforms.
Genewise does not output any proper result for human but so it does for mouse, being closer to the one predicted by other methods. Seblastian has predicted one selenocysteine, concretely located in the same region as defined by all the other programs. Surprisingly, the exon/intron structure predicted has only 10 exons. However, we don’t use Seblastian as a selenoprotein predictor, but for predicting SECIS elements. It has found one SECIS element classified as grade A located between the positions 28397807 and 28397887 on the forward strand, with a free energy of -18,47.Click here to see the multiple sequence alignment among the predicted protein and other mammals'.
One unassigned hit was found in the three TR forms, which we consider could be a pseudogene.
{kind=link}
TR2
The selenoprotein TR2 is located in the scaffold gi|398920536|gb|JH767848.1 comprised between the positions 437383 and 489788 on the forward strand as predicted by the human query. Using the horse query we found some differences, up to 12.000 downstream (concerning to the origin of the gene) and exactly the same place in the final exon. Thus is consistent with the previous results in TR2. This fact could mean two things: first, that probably the functional region of the TR2 protein is found on the latter domain and second, that both selenoproteins, TR1 and TR2, has at a high rate of conservation (both share the same structure). Actually, our three TR we able to predict with good results the position of the other two, thus meaning that although there are different regions between proteins, the queries remain enough conserved to allow the recognizing of the all family. Further results will be obtained when the three proteins are aligned. Interestingly, the mouse predicted protein shows a great coincident with the human one.
The protein predicted by the human query has a total of 16 exons, as happened in horse, but not so in mouse. Click here to see the gene structure predicted with the human query. These differences are due to the poorly conserved first parts or probably as a result of different isoform annotations in the databases. Genewise has predicted similar protein structures, although with slight differences. Here we can find the predicted proteins aligned, and we can see that there is not a higher rate of conservation, although we expected some in the last part (not completely found). Click here to see the multiple sequence alignment among the different predicted proteins.
As happened before, Selenoprofiles has predicted a bigger protein –of 17 exons- with a different start but coincident in the end. This serves to highlight the great difficult to predict accurately the TR structure, due to its complex and bigger structure and the presence of different isoforms. Here we can see how important it is making the good query selection, because as it is a large protein, some queries annotated automatically could miss some domains or expressed different isoforms. Using Seblastian we have obtained a partial structure of the gene, with a selenocysteine located in the last part, as we have described previously. A SECIS element classified as grade A was described on the forward strand between positions 491106 and 491180. Click here to see the multiple sequence alignment among the predicted protein and other mammals'.
{kind=link}
TR3
The selenoprotein TR3 was found in the scaffold gi|398920009|gb|JH767883.1| comprised between positions 600792 and 712908 on the forward strand. As happened before, the different queries have predicted slightly different sequences length, and as before, the last position is highly conserved but there are discrepancies in the start. Mouse has a shorter sequence predicted as well as horse. Click here to see the multiple sequence alignment among the different predicted proteins.
The protein predicted using human query consists of 16 exons, whereas the mouse predicted one has 15 and the horse one 13. Click here to see the gene structure predicted with human. Interestingly, we can see a variable protein at the start, as we have expected for the reasons discussed above, but a really conserved central and final domain, thus consistent with our theory. Moreover, we have described divergences in the first parts of the sequences in the three TR members, thus meaning that not only there is homology but the same selective pressure. Hence, we suggest that the function of the TR might be conserved as well, because the functional domains are highly preserved.
Regarding to Selenoprofiles, we have found the exact length than in the human prediction but a slight different distribution of the exons –thus meaning that the introns are considered in a different way, maybe due to the fact that different splice sites are detected or due to the different isoforms annotated-. However, all together is consistent with what we have seen in the TR family. Genewise prediction are similar as the ones expected with each query but with slight differences in the exons total considered. Finally, Seblastian has found a selenocysteine in the final part of the last exon as expected, and also a SECIS element located in the 713110 and 713189 on the forward strand, classified as a SECIS element of grade B. Click here to see the multiple sequence alignment among the predicted protein and other mammals.
{kind=link}
| Protein | Selenocystein | Exonerate | Genewise | T-Coffee | SECIS | Seblastian | Selenoprofiles |
|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
The unassigned hit is located in the scaffold gi|398923323|gb|JH767749.1| where no other proteins has been identified. The exonerate has generated two different files: one consistent in the last exon of the protein TR1 and the other one, surprisingly, consistent on two exons, also found in the latter part of TR1. The first prediction probably consists of one concrete domain of the protein while the second one could be other domain. However, there is no conservation of the whole sequence, thus meaning that the process in which these regions have evolved are not the ones characterized for a pseudogene. Another interesting point of this prediction is the phenomenon that the second exonerate file contains an intron. Usually, introns are lost in the processes of formation and evolution of the pseudogenes (they are not literally lost but they mutate its splice sites, therefore they are not detected for programs such as exonerate). In fact, it is what has happened possibly in the sequence found between both predictions, where we expected in a codifying protein an intron. If we perform an alignment between our query and the sequence predicted, we can see what we have expected: a kind of good alignment in the last domains and an empty alignment in the other parts, as our duplication is restricted to the last domain of the TR protein. Therefore, we suggest that our unassigned hit corresponds to a double duplication. We support this hypothesis because there is no a complete gene duplication but only the equivalent to three exons, which means that only some domains are duplicated and conserved. For that reason, our prediction of the duplication aligns good with the last region of the query but not with the other regions.
eEFSec
The protein eEFSec is located in the scaffold gi|398920511|gb|JH767850.1 between positions 2252528 and 2514232 on the forward strand. The predicted gene from Homo sapiens query contains 6 introns and 7 exons, eEFsec was found in the same scaffold using the queries from both three organisms but its structure shows several differences. Click here to see the gene structure predicted with
the human query.
Using the human query, exonerate showed a particular protein prediction where two different genes were described in the analysis independently; the first one containing six exons and the second one containing only one exon. Surprisingly, the first one didn't present a methionine as its first aminoacid. On the other hand, Selenoprofiles predicted a protein structure of 8 exons. Exons 3 to 8 of selenoprofiles were identical to the first gene of 6 exons predicted from human query. Interestingly exon 1 from selenoprofiles prediction was identical to the second gene predicted from Homo sapiens, the one initiated with Methionine. We propose in our discussion that the protein contains, actually, 7 exons but the intron region between exon 1 and exon 2 is so large that exonerate splits the protein in two different genes when analyzing it. To support this hypothesis we regarded the protein structure obtained from Mus musculus where 7 exons where predicted; exon 1 corresponding with the independent exon on Homo sapiens and exons 2 to 7 corresponding with the first gene from HS. Finally, the prediction from horse's query presented 6 exons, corresponding with the first gene analyzed by exonerate; the exon 1 was not included. For suporting this idea with extra information we performed an alignment with the different predicted proteins.Click here to see the multiple sequence alignment among the different predicted proteins.
The genewise analysis showed predictions for the same scaffold but the alignments are shorter than the expected. This protein is part of the machinery and does not contain any SeCys. Therefore, no SECIS element has been predicted. The eEFSec found in C simum also shows high identity with the majority of mammalian annotated eEFSec. “Click here” to see multiple sequence alignment. Click here to see the multiple sequence alignment among the predicted protein and other mammals'.No pseudogenes nor unassigned hits nor duplications have been predicted
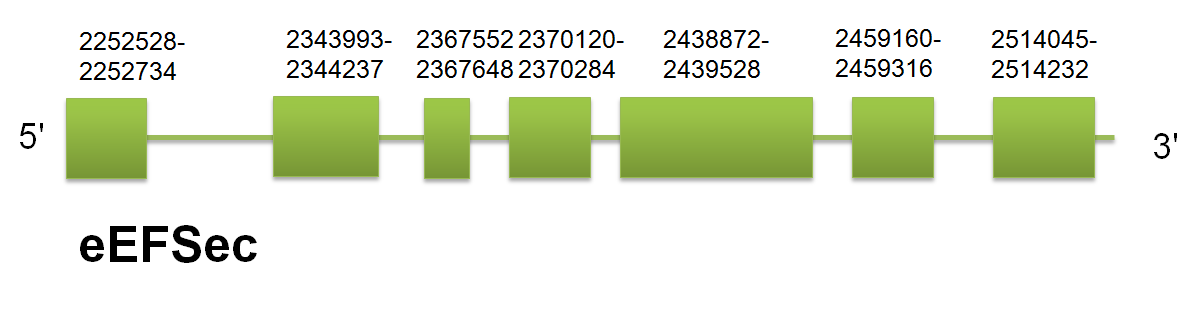{kind=link}
Pstk
The protein Pstk is located in the scaffold gi|398921680|gb|JH767798.1 between positions 20434050 and 20465046 on the reverse strand. The predicted gene from the Homo sapiens query contains 5 introns and 6 exons. Click here to see the gene structure. We have found the same prediction using human and mouse protein sequence as a model. The predicted protein with the Equus caballus query contains 4 introns and 5 exons, one less exon. Analyzing the exonerate input data we can observe that the missing exon is exon 6, the last one. Those differences can be explained by the lack of conservation of certain domains among the three proteins that have been used as query for this prediction. We analyzed those differences through a multiple sequence analysis, and we considered finally, that it was the same protein. Click here to see the multiple sequence alignment among the different predicted proteins.
The prediction from selenoprofiles showed a 6 exon structure protein, according with the predictions using human and mouse queries. Even though horse is a phylogenetically closer organism to the rhino, their selenoproteins are worst annotated and this could be a reason for the missing exon.
The pstk found in Ceratotherium simum also shows high identity with other annotated mammalian pstk. Click here to see the multiple sequence alignment among the predicted protein and other mammals'.
No pseudogenes nor unassigned hits nor duplications have been predicted.
{kind=link}
SBP2 and SBP2-like
To search SBP2 in the C. simum genome, we have used our query system, consistent on one query of mouse, one of horse and one of human, in order to cover the evolutive divergences. Consistent with this, we have found different results for SBP2 depending on the query used. Using the human query we have obtained two hits, although only one is able to predict a full SBP2. The other hit is really good but only for a concrete domain, which seems to be conserved. However, the rest of the protein predicted is poorly similar. Thus, we could have a duplication in this protein what we will go deeply below. Moreover, some authors have defined an homologous to SBP2 in vertebrates, which is considered as a paralogous. Interestingly, although there are some similarities, conservation is limited to some domains, such as SID and RBD. Hence, we suggest that we have found with human is SBP2 and one domain of SBP2-like.
The selenoprotein SBP2 predicted by the human query is located in the scaffold gi|398923423|gb|JH767747.1| and it is comprised between the positions 16289776 and 16329206 on the forward strand. It is formed by 16 exons, although the exonerate outputs a double exonerate but correlated. These results are consistent with the ones generated by the Selenoprofiles program (there are slight differences when predicting the first exon, but the last exon is predicted exactly in the same way). We consider that our prediction could be enough accurate, as it covers all the query length and starts with Met. However, we can not affirm that the one predicted by Selenoprofiles is not an isoform of the gene.
The second good hit obtained from our system of queries is located in the scaffold gi|398924730|gb|JH767728.1|. Although we have a positive exonerate with a gene prediction, we suggest that this prediction has not being properly done, as it only predicts 7 exons and we expected a larger protein -similar to SBP2 predicted-. The explanation of this hit is simple: we have detected the conserved domain which are present in SBP2-like selenoprotein. For that reason, the t_coffee alignment is only good in the specific region, which shows high conservation, but not in the other parts of the protein. Thus, we can not use the second hit of human to predict SBP2-like selenoprotein. However, running the queries of horse and mouse we can supply this lack of information, because we have detected the SBP2-like selenoprotien with a high fidelity.
When using both horse and mouse queries, we detect one really good hit, located in the scaffold gi|398924730|gb|JH767728.1| comprised between the positions 30630663 and 30673506 on the reverse strand. It is formed by 16 exons as shown by the mouse query (the horse query only predicts 15, but could be done to the large size of the protein that makes more difficult accurate predictions if the annotation of the query is not good). Selenoprofiles was able to predict the same protein as well, although with only 15 exons, but in the same range of positions. Moreover, with both mouse and horse we found a second hit, which is consistent with the original SBP2 predicted with human query. As happened before, this prediction was only good in some regions, the ones that are specially conserved in SBP2-like and SBP2.Thus, we were able to predict both SBP2 and SBP2-like selenoproteins by using different queries.
The identification of these two proteins was possible thanks to performing multiple sequence alignments between the three different predicted proteins for the two scaffolds that we found. In both we could see a common pattern in which we can only find a complete alignment in two regions. These two regions are very conserved in both alignments showing almost the same length and separation in both alignments. Click here to see the multiple sequence alignment among the different predicted proteins in the first scaffold. Click here to see the multiple sequence alignment among the different predicted proteins predicted on the second scaffold. Our hipotesis is that, as it is already known, there was a gene duplication on SBP2 before the divergence of the human, mouse, horse and rhinocero lineages. Then, on the human lineage, mutations were accumulated on one copy of the gene, keeping the two conserved regions that we have seen on the alignments free of them. We think that on horse and mouse the mutations were accumulated on the other copy of the gene, also keeping these two regions conserved. Finally, this hipotesis makes sense if we supose that the C.simum did not accumulate mutations in both genes. That's how we explain that we can predict the whole conserved protein with human, mouse and horse.
We can also study the homology of these two proteins making multiple seguence alignments among several mammals.Click here to see the multiple sequence alignment among the SBP2 predicted protein and other mammals'.
SBP2 plays a main role in selenoprotein synthesis because it binds to the SECIS element, and interacts with both the specific elongation factor and the ribosome at the 60S subunit. Thus will allow the recruitment of the eEFsec-selenocysteinetRNAsec to the sequence. It is formed by two different domains: the N-terminal part (which seems to be dispensable) and the C-terminal.
Secp43
The protein SECP43 is located in the scaffold gi|398923877|gb|JH767739.1 between positions “22192781” and “22207524” on the forward strand. The predicted gene for Mouse (the selected query) query contains 6 introns and 7 exons.
The horse protein has 6 exons and 5 introns. The human one has 9 exons and 8 introns.
These differences can be explained by the lack of conservation of certain domains among the three proteins that have been used as query for this prediction. It also could be explain by a wrong annotation of some of the queries. In this analysis the protein selected was the mouse one. Our program predicted three different proteins,and due this limitation we had used other tools to determinate the best query to use.
Starting by the tcoffe analysis, the alignment with human was not enough good compared to the other two, this idea, and the huge difference in exons, lead us to discard the Human query. Click here to see the multiple sequence alignment among the different predicted proteins.
Then we arrive to a more difficult decision between mouse and horse. Due the phylogenical distance the selected query will be the horse one, but as we use other tools of analysis the conclusion that we will reach is diferent. The advantatge of our system is that we target the protein using 4 different systems, and this refinement protects us against problems as the one seen in this protein. In this case Seblastian did not present any result because Secp43 do not have a selenocystein. So we need another tool to define the best protein, and this tool is Selenoprofiles. Selenoprofiles predicts a protein homologous to the one predicted by mouse, it also confirms the lack of selenocystein.
With all this information we will be able suggest that the protein present in the C. simum is the one predicted by the mouse.
The Secp43 found in C simum also shows high identity with the majority of mammalian annotated Secp43. Click here to see the multiple sequence alignment among the predicted protein and other mammals.
SECp43 is a selenoprotein that shown to bind to selenocysteyl-tRNA so it is related to the selenoprotein biosynthesis. Studies have been demonstrated that SECp43 forms a complex with Sec tRNA and SLA (Soluble Liver Antigen). Primarily, SECp43 is located in the nucleus, whereas SLA is in the cytoplasm. Co-transfection of both proteins resulted in the nuclear translocation of SLA suggesting that SECp43 probably promote shuttling of complex SLA – Sec tRNA between different cellular compartiments. Is also described the role of SECp43 in regulation of selenoprotein expression by affecting the synthesis of Um34 on tRNA and the intracellular location of SLA.2. This is a evident example of the importance of selenoproteins, it is not “cheap” to maintain this number of proteins and machinery (as SECP43),and if they importance were not relevant selective evolution will erase them.
| Protein | Selenocystein | Exonerate | Genewise | T-Coffee | SECIS | Seblastian | Selenoprofiles |
|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
SecS
The protein SecS is located in the scaffold gi|398922744|gb|JH767763.1 between positions 20434050 and 20465046 on the reverse strand. The predicted gene from Homo sapiens query contains 10 introns and 11 exons.
We have found different proteins using human, mouse and horse sequences as model. Furthermore, the prediction from Selenoprofiles, showed also the same protein and structure. Selenorpofiles also predicted SecS in the same region of the genome and with the same structure than the one obtained from our queries. A Secis element was predicted by Seblastian. Nevertheless, Genewise and Seblastian didn't show a proper prediction for SecS. Even thought the predicted structure for SecS was the same and the predicted proteins were almost identical, some differences arised in their sequences in particular regions. They can be explained by the lack of conservation of certain domains among the three proteins that have been used as query for this prediction. We analyzed those differences through a multiple sequence analysis, it shows that SecS predictions are almost identical.Click here to see the multiple sequence alignment among the different predicted proteins.
The SecS found in Ceratotherium simum also shows high identity with the majority of mammalian annotated SelH. Click here to see the multiple sequence alignment among the predicted protein and other mammals'. No pseudogenes nor unassigned hits nor duplications have been predicted.