
Abstract
Selenoproteins are polypeptides that mediate the biological effects of Selenium, an essential micronutrient, due to the presence of this micronutrient in selenocysteine. These residues are selenium-containing amino acids found at least once in the chains of selenoprotein.
Some of these proteins are discarded in genome databases because this residue lacks a conventional codon and is defined by UGA, which is generally regarded as a stop codon. Furthermore, a secondary mRNA structure that allows the insertion of a selenocysteine instead of a stop codon is required for the recognition and responsibility of alerting the ribosomes that the UGA codon should not be interpreted as a STOP.
The goal of our research is to use a homology-based in silico search to predict the selenoproteins of Nanger dama, a gazelle species that lives in Africa. We analyzed the genome of this mammal with the selenoprotein annotations of Bos taurus and Homo sapiens that we found on SelenoDB.2, in order to determine the properties of the Nanger dama's selenoproteome. Different bioinformatic tools were required for the prediction, including tblastn, Exonerate, T coffee, Seblastian, and SECISearch3. We have also created a semiautomated tool to help speed up the procedure.
Our results show a conservation between Nanger dama and our queries, Homo sapiens' and Bos taurus' selenoproteome. We have found 21 selenoproteins, 10 Cys-containing homologous proteins and 4 machinery proteins. However, 5 selenoproteins could not be predicted.
This study contributes to the identification of selenoproteins in newly sequenced species. This research aids in the discovery of selenoproteins in newly sequenced species.
Back to top of page
Description
 Nanger dama is the largest species of gazelle that lives in Africa, in the Sahara desert and the Sahel. Due to its biological and human threats, it has become a critically endangered species and natural populations of this species only remain in Chad, Mali and Niger.
The dama gazelle is a medium-sized antelope, thin and stylized, with a considerably long neck and also long legs. These incredibly long legs enables them to adapt to the hot desert environment. The horns are present in both sexes, although larger and thicker in males, and are not very long. The neck and back are reddish brown, while the head, lower body and tail are white[4,5].
It is between 90 and 120 cm (35 and 47 in) tall at the shoulder, weighs between 35 and 75 kg (77 and 165 lb), and has a lifespan up to 12 years in the wild or 18 in captivity [5].
Nanger dama is the largest species of gazelle that lives in Africa, in the Sahara desert and the Sahel. Due to its biological and human threats, it has become a critically endangered species and natural populations of this species only remain in Chad, Mali and Niger.
The dama gazelle is a medium-sized antelope, thin and stylized, with a considerably long neck and also long legs. These incredibly long legs enables them to adapt to the hot desert environment. The horns are present in both sexes, although larger and thicker in males, and are not very long. The neck and back are reddish brown, while the head, lower body and tail are white[4,5].
It is between 90 and 120 cm (35 and 47 in) tall at the shoulder, weighs between 35 and 75 kg (77 and 165 lb), and has a lifespan up to 12 years in the wild or 18 in captivity [5].
Taxonomy
The dama gazelle was described as Nanger dama by Peter Simon Pallas in his 1766 work Miscellania Zoologica [2]. Lady gazelles, along with Grant gazelles and Soemmerring gazelles, give their name to the genus Nanger, within the subfamily Antilopini included in the family Bovidae. At a higher taxonomic level, they are found within the order Artiodactyls, an order belonging to the group of mammals, within the chordates of the Animal Kingdom [5].
Subespecies
The dama gazelle is generally divided into three subspecies based on the colour of the animals back, flanks and haunches[5]:
| N.dama dama |
| N.dama mhorr |
| N.dama ruficollis |
Alimentation
Their feeding is based on a herbivorous diet: eat grass, seeds and leaves from shrubs and trees such as acacias, which it accesses by rising on its hind legs. As an adaptation to the extremely dry environment in which it lives, it is able to spend long periods without drinking water [4, 5].
Behaviour
Unlike many other desert mammals, the dama gazelle is a diurnal species, meaning it is active during the day. Always on the alert, the dama gazelle uses a behavior called pronking to warn herd members of danger. Pronking involves the animal hopping up and down with all four of its legs stiff, so that its limbs all leave and touch the ground at the same time. Males also establish territories, and during breeding season, they actively exclude other mature males. They mark their territories with urine and dung piles and secretions from glands near their eyes [4, 5].
Reproduction
Gestation lasts about six months and usually a single offspring is born in each part. In the early days, the young stand still on the ground to go unnoticed and the mother, if she detects predators in the vicinity, runs and moves strikingly in another direction to move them away from their position[4].
Conservation status
The numbers of this species in the wild have fallen by 80% over the last decade. The IUCN now lists it as critically endangered with a wild population of less than 500 (the most recent review suggests c. 300). It occurs in poor countries and little action is taken to protect the species. The national parks are not well guarded, and poaching still occurs[4,16,5,14].
| N.dama dama | only kept in captivity at Al Ain Zoo in the United Arab Emirates, and is very rare in the wild. |
| N.dama mhorr | is extinct in the wild but present in captive breeding programs in Europe, North America, North Africa and the Middle East. |
| N.dama ruficollis | is present in captive breeding programs in Europe, North America and the Middle East, and very rare in the wild |
What has led to this situation?
Human threats: habitat destruction has led to the destruction of the trees on which this gazelle feeds so it cannot eat. Another potential threat is tourism: tourists want to take pictures of this endangered species, and in doing so, may be perceived as a threat, especially during the hot season, so gazelles will run away from perceived danger, and in the hot season may overheat and die of stress[5].
Biological threats: The dama gazelle does not need a lot of water, but it needs more than other desert animals so, during the drought season it perishes from a lack of water. The environment has become ill-suited for it. Habitat pressure from pastoral activity is another reason for decline, as are introduced diseases from livestock[5].
Back to top of pageSelenium
Selenium is an essential micronutrient for humans and other organisms. It supports various important cellular and organismal functions regarding homeostasis. Its deficiency leads to pathological conditions (heart disease, neuromuscular disorders, cancer, male infertility and inflammation), while an excess could cause toxicity. Its biological effects are mediated by selenoproteins (selenium-containing proteins), present in all the three domains of life. At least, all these selenoproteins contain one selenocysteine (a selenium-containing aminoacid)[9,11].
Selenocysteine
Selenocysteine (Sec) is the 21st proteinogenic amino acid discovered by biochemist Thressa Stadtman at the National Institutes of Health. It is an analogue of the more common cysteine with selenium instead of sulfur. Sec is present in several enzymes such as glutathione peroxidases, thioredoxin reductases and some hydrogenases, among others. Sec is encoded by the UGA codon, which has a translational stop function 99, 9% of the time and the other 1% works by inserting selenocysteine. The signal that directs the cell to translate UGA codons as selenocysteine instead of a stop codon is the SECIS element[9,11].
Selenoprotein biosynthesis
Selenoproteins are mostly redox enzymes with antioxidant properties found in all majors domains of life, even in viruses. Its biosynthesis, either in eukaryotes and archaea, has been unknown for many years. Interestingly, Sec is unique among other aminoacids as it is the only known aminoacid in eukaryotes whose biosynthesis occurs on its own tRNA: Sec tRNA. This molecule has unique features that distinguish it from those of standard tRNAs in several aspects, most notably in the fact that it is the longest tRNAs found in eukaryotes (90-93 nucleotides), archaea, and bacteria (100 nucleotides). Also, it presents an incredibly long variable arm and a long acceptor stem and D-stem[9]. Biosynthesis steps:
The incorporation of Sec into proteins is regulated by UGA codons, which usually works by inserting translation stop codons. Nevertheless, Sec is introduced into selenoproteins by a complex mechanism that requires trans-acting proteins factors, SECIS elements and Sec-tRNA[9]. Evolution/phylogeny Identification of selenoproteins has been difficult to achieve due to the dual function of the UGA codon, which leads to a misannotation. Since the development of some bioinformatic approaches such as Seblastian, identification of selenoproteins is possible.
Selenoproteins are mostly redox enzymes with antioxidant protection capacity, are found in all major domains of life, even in viruses.
Although selenoproteins are widespread in all three domains of life, the selenoproteome differs widely between organisms: according to recent research, aquatic organisms have larger selenoproteomes than terrestrial organisms, and mammalian selenoproteins have a tendency to employ less selenoproteins. Also, the selenoproteome is well-characterized in mice and humans (there are 24 and 25 genes encoding selenoproteins, respectively), nevertheless, other Eukarya organisms (plant and yeast) do not have selenoproteins as they lost the machinery necessary for its biosynthesis.
Therefore, in evolution, some selenoproteins have been lost in some species by an independent evolutionary phenomena. For example, Drosophila Willistoni has lost the machinery needed to synthesize selenocysteine. Also, in fungi, which at first were thought to be deficients in selenocysteine, they have found some species of fungi that some do have selenocysteine and some have lost its ability to synthesize them. In contrast, other selenoproteins are highly conserved in eukaryotic and prokaryotic genomes such as SPS (Selenophosphate synthetases), which is needed for the synthesis of selenoproteins[9,11].
The goal of this research is to identify, characterize, predict and annotate selenoproteins and cysteine-containing homologs or selenium machinery proteins in the genome of Nanger dama. A homology-based study is required to achieve this goal. Therefore, we have compared Nanger dama's genome with the genome of Bos taurus, a well-annotated species which is phylogenetically close to Nanger dama. For some proteins, we found that the human genome was more suitable as a reference genome as Bos taurus's selenoproteins were not accurately annotated.
The path that will be taken to obtain the selenoproteome of Nanger dama is illustrated in the figure below (Figure 1). Figure 1. Pipeline followed for the protein prediction analysis. Nanger dama genome acquisition First and foremost, we obtained all the programs and the Nanger dama genome required for the analysis from a public database (provided by the teachers of Bioinformatics), which can be reached by typing the following in the unix file browser: /mnt/NFS_UPF/soft/genomes/2021/Nanger_dama/genome.fa Nanger dama's genome index was also provided to us and can be found in the path below: /mnt/NFS_UPF/soft/genomes/2021/Nanger_dama/genome.index Query acquisition A highly important step was considering which organism to use as a reference genome to search for conserved selenoproteins and machinery proteins in the genome of Nanger dama. We decided to use the cow (Bos taurus) as a reference genome as it is a mammal which is closely related to our organism, they both belong to the Bovidae family. Furthermore, it is also a well-annotated and well-characterised species which can be accessed in SelenoDB 2.0 database.
However, in some cases the Bos taurus database was partially incomplete or the proteins were not accurately annotated and therefore in those cases we decided to use Homo sapiens as the reference genome (query) in order to obtain the whole annotated protein. Often, the annotated Bos taurus' selenoprotein did not begin with a methionine or it contained other characters. Furthermore, in other cases where we obtained bad alignments in t-coffee, prediction of only one part of the protein or a low t-coffee score, we also attempted to use Homo sapiens as the query.
We obtained all the FASTA sequences in SelenoDB 2.0 database and used them as queries to compare with Nanger dama's genome. We created a fasta file for each protein called $p.raw.fa , where "$p" was the name of the protein analysed. Each file contained the amino acid sequence for each protein. This step was useful in order to then automatize the analysis process for each file. Automatization In order to streamline the analysis of the different proteins, we created a Perl program script that could analyse the potential selenoproteins and machinery proteins and carry out the pipeline shown in Figure 1 one by one. By doing this, we were able to automate all of the steps required for the analysis, except for the following ones which were performed manually: After that, the following steps were carried out automatically, and we eventually obtained the T-Coffee alignment for each protein. Please click here to download our program. Preprocessing First of all, the program changed all the U (which represent selenocysteine) to X. This is essential for the TBLASTN to read the entire sequence without error. Moreover, as some annotated Bos taurus proteins contained #, @ and % symbols in the middle or the end of the sequence, we removed them to clean the sequences.
The following command line is used to perform these actions: sed 's/U/X/g' $dir/$p.raw.fa | sed 's/#//g' | sed 's/@//g' | sed 's/%//g' > $directory/$p.fa BLAST We used BLAST (Basic Local Alignment Tool) to search for potential Nanger dama genomic regions, where the previously identified queries could be found. It should be taken into account that, as BLAST uses a heuristic algorithm, it cannot guarantee that the perfect solution is found because it can miss real hits with little similarity.
In our case, we used TBLASTN in order to compare the protein query sequences to the Nanger dama nucleotide sequence. The search yielded potential alignments or hits in the Nanger dama genome. In our program, only hits with an e-value equal to or less than 0.001 were considered, as we wanted to single out the most significant hits.
The following command was used to run the program: tblastn -query $directory/$p.fa -db /mnt/NFS_UPF/soft/genomes/2021/Nanger_dama/genome.fa -out $directory/$p.tblastn -outfmt 7 -evalue 0.001 Where $p.fa is the query of the selenoprotein of interest, and $p.tblastn is the output file containing the significant alignments for the query in the Nanger dama genome.
Then, a summary of the TBLASTN results was printed, and the selection of the scaffold was made manually. We followed the following criteria: We chose those scaffolds with the lowest E-values, and a high % identity (always more than 70% identity). In cases where we detected more than one scaffold with both characteristics or similar values, we conducted the alignment process for each scaffold, in order to identify potential duplications or scaffold overlappings.
FASTAFETCH Once we obtained the hit, we had to extract the genomic region of interest. As the genome had already been indexed, the Fastafetch command was run directly, allowing us to extract the scaffold in which we could find the selected hit.
The following command was used to run this program: fastafetch /mnt/NFS_UPF/soft/genomes/2021/Nanger_dama/genome.fa /mnt/NFS_UPF/soft/genomes/2021/Nanger_dama/genome.index $s > $directory/$p.$s.fastafetch.fa Where $s is the selected scaffold and $p.$s.fastafetch.fa is the nucleotide sequence in the Nanger dama genome that is more likely to contain selenoproteins or selenium machinery proteins. FASTASUBSEQ After obtaining the region of interest, this had to be further delimited within the chosen scaffold, in order to achieve shorter sequences of the fragment that could contain the selenoprotein-coding gene. Therefore, the program asked us for the first and last nucleotides of the selected hit and we entered them manually.
To do so, we took the positions of the TBLASTN hit and we expanded the downstream and upstream margins of the alignment to ensure that we could find the whole selenoprotein in the genome of Nanger dama and that the SECIS element of the gene was also included (50000bp in 5' and 50000bp in 3').
The range of the expansion was 50000bp nucleotides in 5 prime. However, if the outcome of such an operation was zero or a negative value, the program assigned the position one as the starting point by default.
$start = $start - 50000; The range of expansion was also 50000bp nucleotides in 3 prime extreme. However, we need to take into account that this elongated sequence cannot be longer than the scaffold length. Therefore we calculated the length of the scaffold by multiplying the number of nucleotides in one row by the number of lines minus one (heather) in the fastafetch file. The program ensured that the expansion in 3 prime did not exceed the length of the scaffold. Therefore, if the last position was longer than the scaffold length, the last nucleotide position was set to the scaffold's last position. Finally, the fastasubseq length variable was obtained by subtracting the last nucleotide position minus the first nucleotide position.
my $length = $final - $start;
Once the start and length position were defined, we were able to obtain the region of interest using the following command line:
fastasubseq $directory/$p.$s.fastafetch.fa $start $length > $directory/$p.$s.subseq
EXONERATE Exonerate was used to predict the potential exons found in the previous sequence. An exhaustive mode (--exhaustive yes) was applied to achieve more accurate results. Finally, we concatenated all the exons of the file using egrep.
These are the commands used: exonerate -m p2g --showtargetgff --exhaustive yes -q $directory/$p.fa -t $directory/$p.$s.subseq | egrep -w exon > $directory/$p.$s.exonerate.gff FASTASEQFROMGFF Following that, we used Fastaseqfromgff to extract the predicted protein's exons. This program creates a new file with all the exons attached (cDNA). fastaseqfromGFF.pl $directory/$p.$s.subseq $directory/$p.$s.exonerate.gff > $directory/$p.$s.pred.nuc FASTA TRANSLATE We used this program in order to obtain the amino acid sequence based on the exon sequence predicted with Exonerate. We used the command function -F 1, to consider only the first open reading frame (ORF).
fastatranslate -F 1 $directory/$p.$s.pred.nuc > $directory/$p.$s.pred.fa Where $p.$s.pred.fa is the amino acid sequence of the potential predicted selenoprotein. Changing * to X When Fasta Translate finds a TGA, that codes for a stop or a selenocysteine (if SECIS elements are present), it will translate it as a *. This is a problem when T-Coffee is executed, because it can generate a wrong alignment. To resolve this, we substituted * for X, which means, any amino acid. sed 's/*/X/g' $directory/$p.$s.pred.fa > $directory/$p.$s.predx.fa T-COFFEE Finally, we used the t-coffee program with the following command line to perform a global alignment between the query protein (from Bos taurus or Homo sapiens) and the predicted protein sequence (from Nanger dama). t_coffee $directory/$p.fa $directory/$p.$s.predx.fa > $directory/$p.$s.tcoffee The result of this comparison will be the alignment, which indicates amino acids that are the conserved in both proteins (*), amino acids that have changed but are coherent in terms of structure (:), amino acids that are non-coherent (.), and gaps ( ). Each T-Coffee alignment generates an alignment score which indicates the total consistency value of the alignment. SEBLASTIAN and SECIS SEARCH In order to predict the SECIS elements found in our predicted proteins we used Seblastian. Seblastian is a tool which was developed for selenoprotein gene prediction and analysis, which combines the improved SECIS prediction-based approach for identification of selenoproteins (SECISearch 3) with the SECIS-independent method that relies on Sec/Cys homologs. To search for the SECIS we used the output file obtained from the fastasubseq step. SECIS which were found in 5'UTR or on the complementary strand of our protein were discarded. In cases where no SECIS elements were found, we used SECISearch3 in order to corroborate the findings.
Materials and methods
if ($start <= 0){
$start = 1;
}
The command used is:
This is the command:
This is the command used:
This is the command used:
The significance and interpretation of the findings will be discussed in the following sections.
PHYLOGENETIC ANALYSIS:
Once we obtained all the predicted proteins from Nanger dama, we performed a phylogenetic analysis between proteins of the same family using the phylogeny.fr tool . The aim of this analysis was to uncover the phylogeny of each protein and the relationship between those proteins of the same family and their query.
| Icon | Meaning |
 |
Human protein |
 |
Bos taurus protein |
 |
Existing document |
 |
Non-existing document |
We have gathered all our data in a data table:
| Proteins | Query | Residue | Scaffold | gene prediction | protein prediction | tblastn | Strand | tcoffee | Seblastian | SECIS | SECIS image |
| GPx1 | |
U | JAHTZZ010000006.1 | |
|
|
(+) | |
|
|
 |
| GPx2 | |
U | JAHTZZ0100000014.1 | |
|
|
(+) | |
|
|
 |
| GPx3 | |
U | JAHTZZ010000006.1 | |
|
|
(-) | |
|
|
 |
| GPx4 | |
U | JAHTZZ010000006.1 | |
|
|
(-) | |
|
|
 |
| GPx5 | |
Cys | JAHTZZ020000014.1 | |
|
|
(-) | |
|
|
 |
| GPx6 | |
U | JAHTZZ010000327.1 | |
|
|
(+) | |
|
|
 |
| GPx7 | |
Cys | JAHTZZ010000016.1 | |
|
|
(-) | |
|
|
|
| GPx8 | |
Cys | JAHTZZ010000013.1 | |
|
|
(+) | |
|
|
 |
| DI1 | |
U | JAHTZZ010000016.1 | |
|
|
(-) | |
|
 |
 |
| DI2 | |
U | JAHTZZ010000014.1 | |
|
|
(+) | |
|
|
 |
| DI3 | |
U | JAHTZZ010000001.1 | |
|
|
(+) | |
|
|
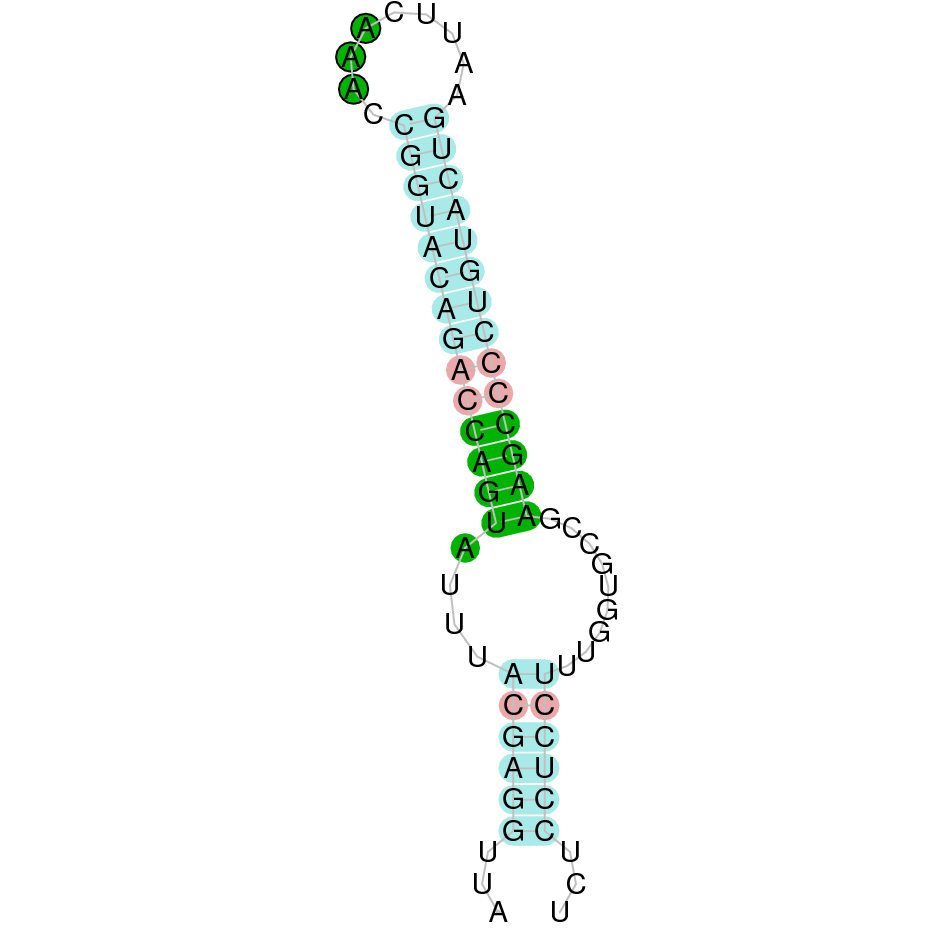
 |
| MsrA | |
Cys | JAHTZZ010000001.1 | |
|
|
(-) | |
|
|
|
| Sel15 | |
U | JAHTZZ010000016.1 | |
|
|
(+) | |
|
|
|
| SelH | |
Cys | JAHTZZ010000007.1 | |
|
|
(-) | |
|
|
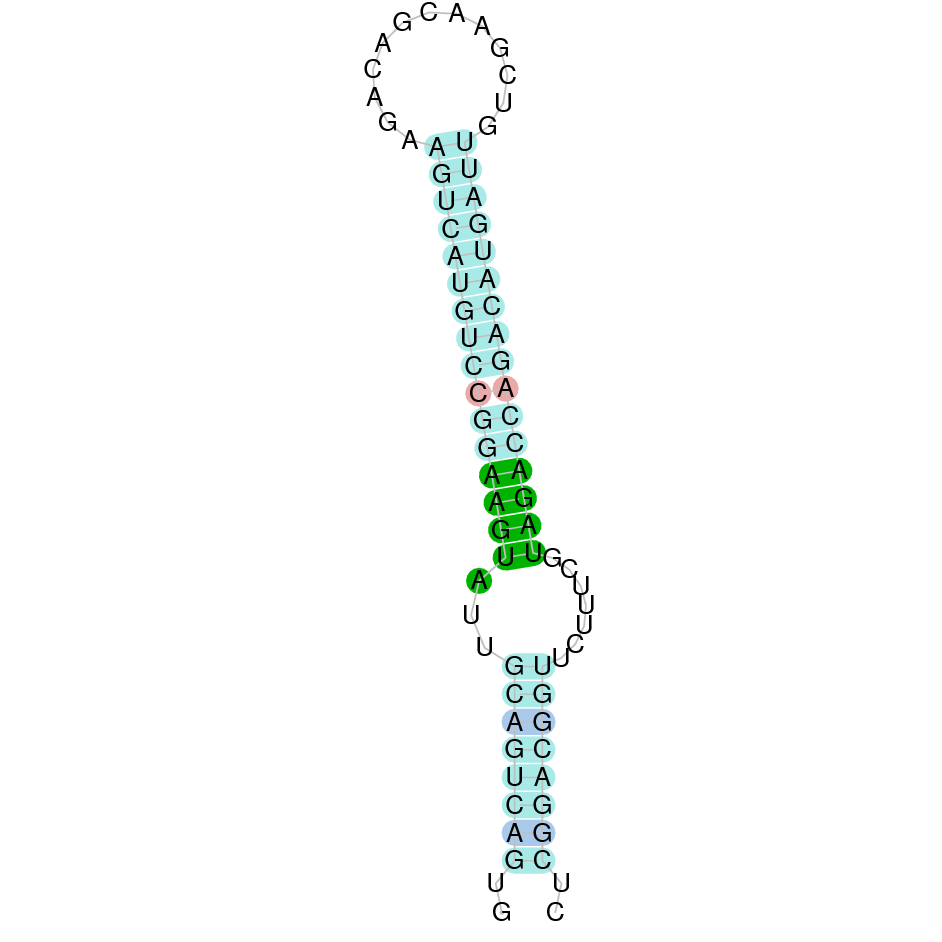
 |
| SelT | |
U | JAHTZZ010000447.1. | |
|
|
(+) | |
|
|
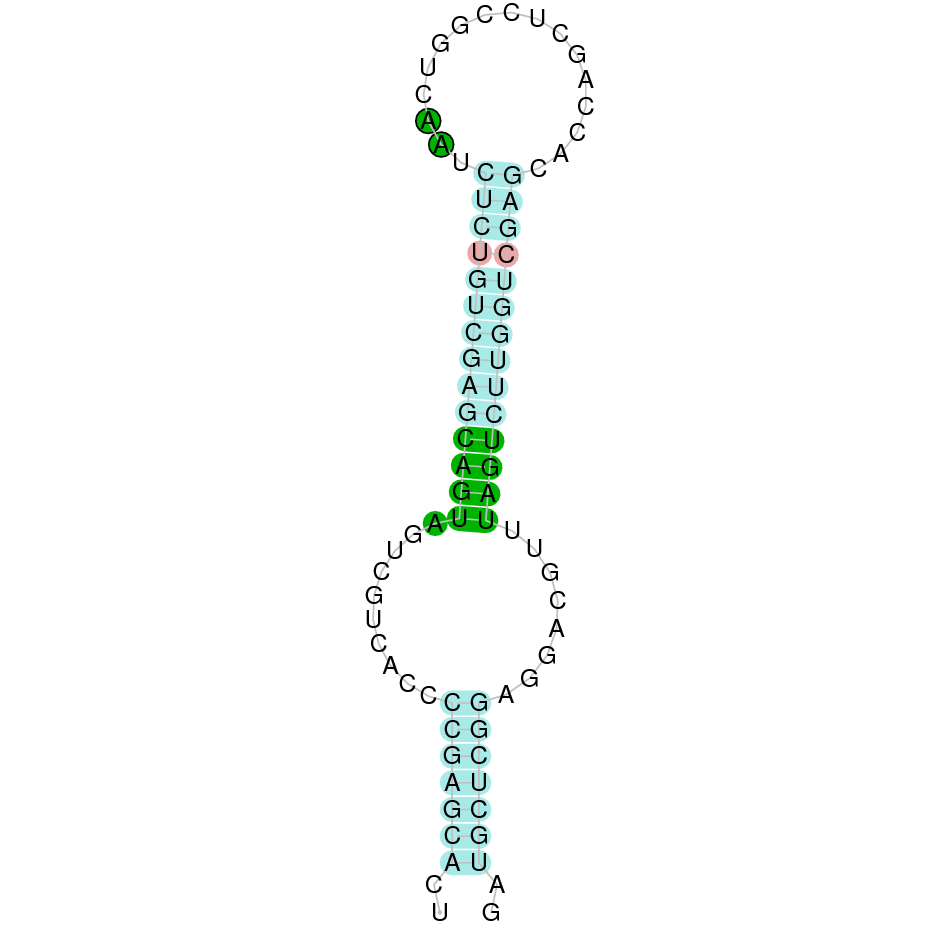
 |
| SelW1 | |
U | JAHTZZ010000011.1 | |
|
|
(+) | |
|
|
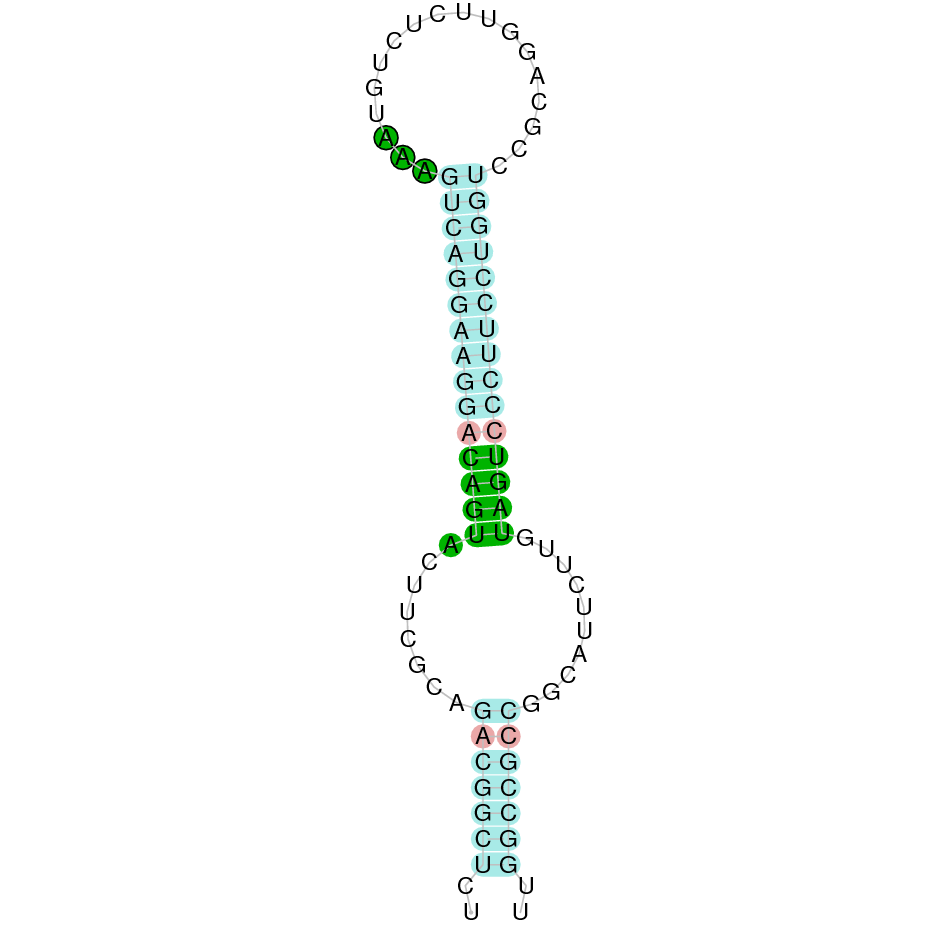 |
| SelW2 | |
U | JAHTZZ010000009.1 | |
|
|
(-) | |
|
|
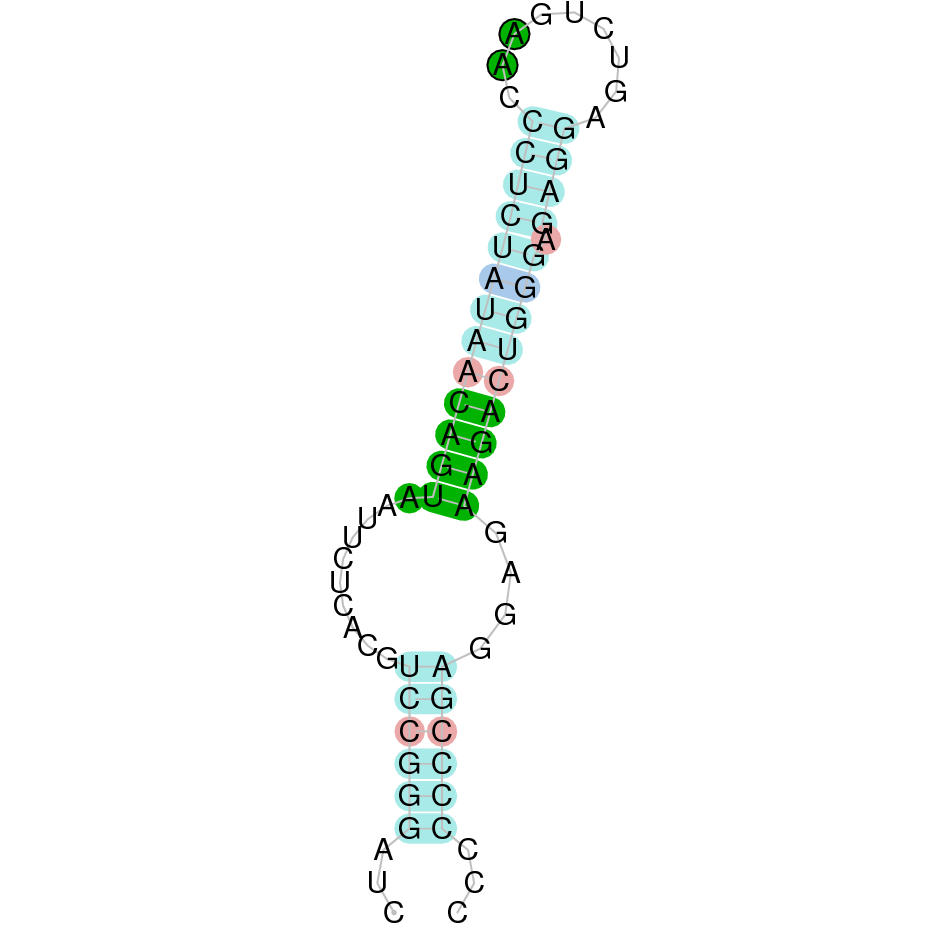 |
| SelV | |
U | JAHTZZ010000009.1 | |
|
|
(+) | |
|
|
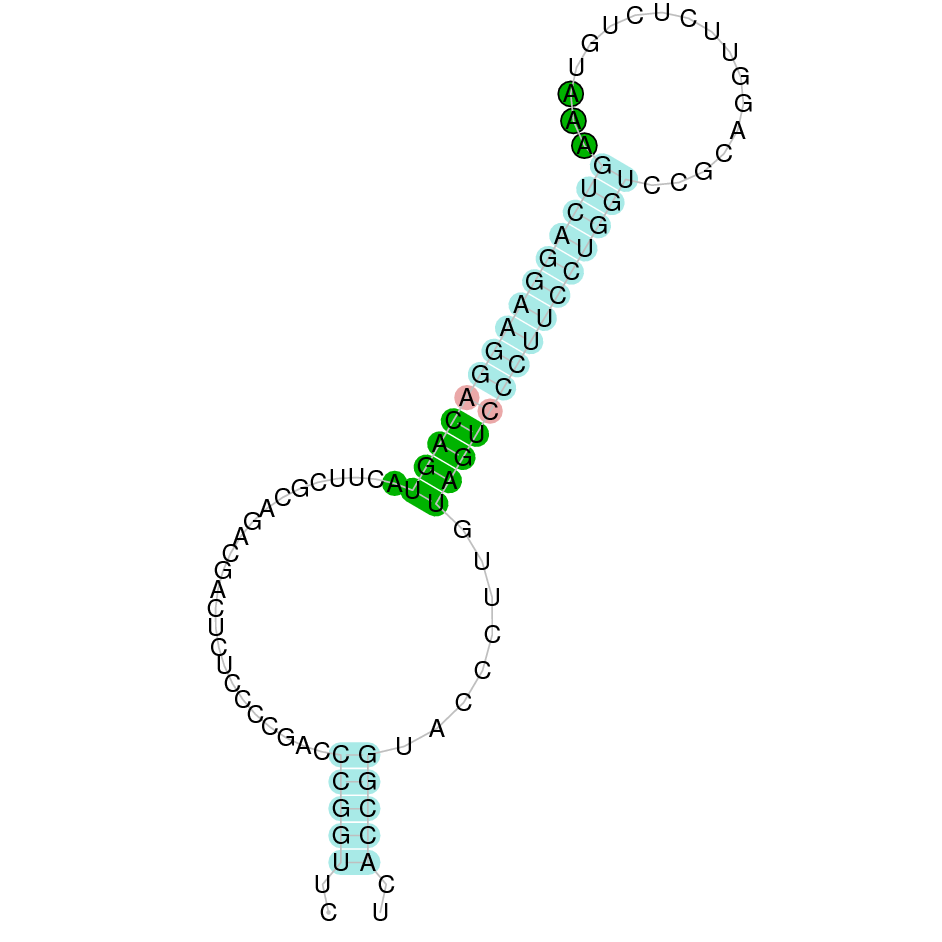 |
| SelI | |
U | JAHTZZ010000008.1 | |
|
|
(-) | |
|
|
 |
| SelK | |
U | JAHTZZ010000006.1 | |
|
|
(+) | |
|
|
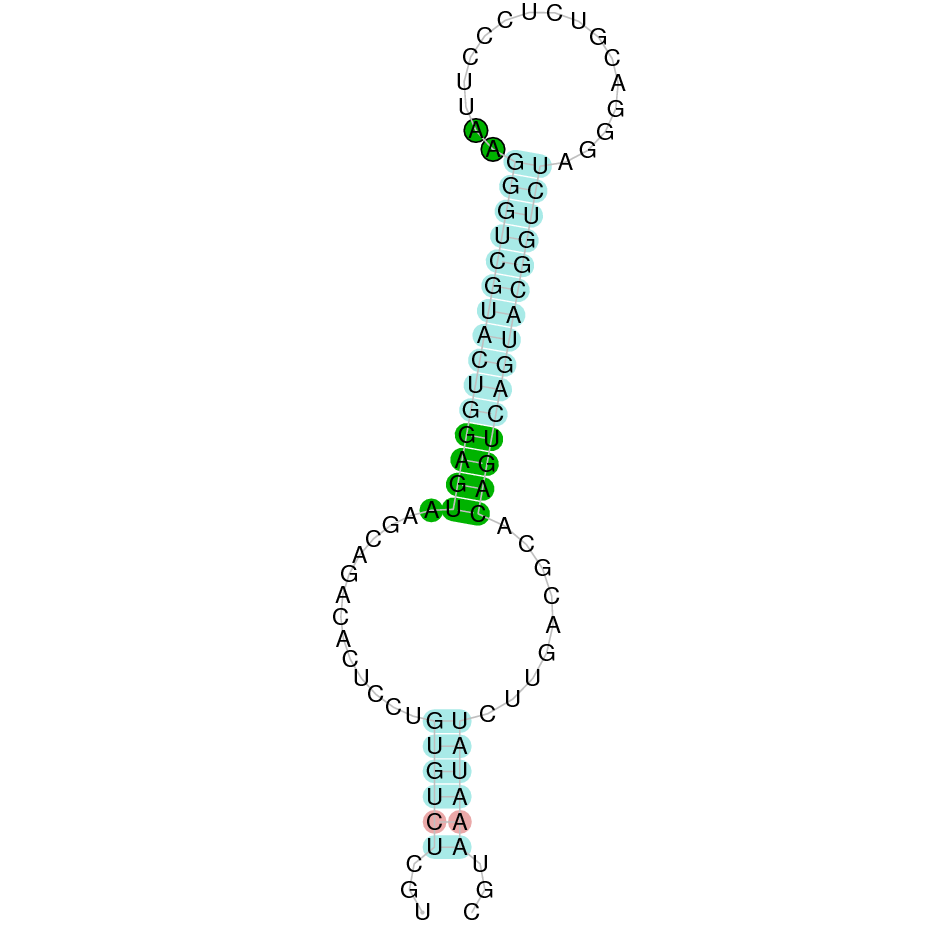 |
| SelM | |
U | JAHTZZ010000007.1 | |
|
|
(-) | |
|
|
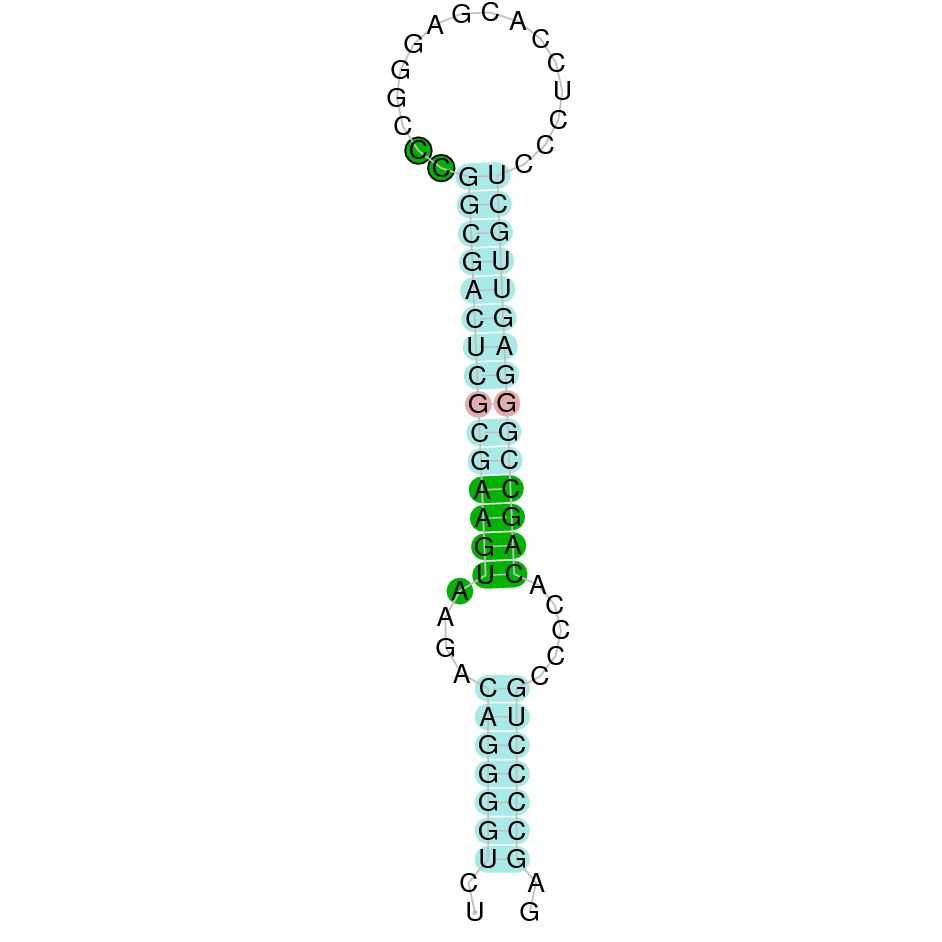 |
| SelN | |
U | JAHTZZ010000017.1 | |
|
|
(-) | |
|
|
 |
| Sel0 | |
U | JAHTZZ010000019.1 | |
|
|
(-) | |
|
|
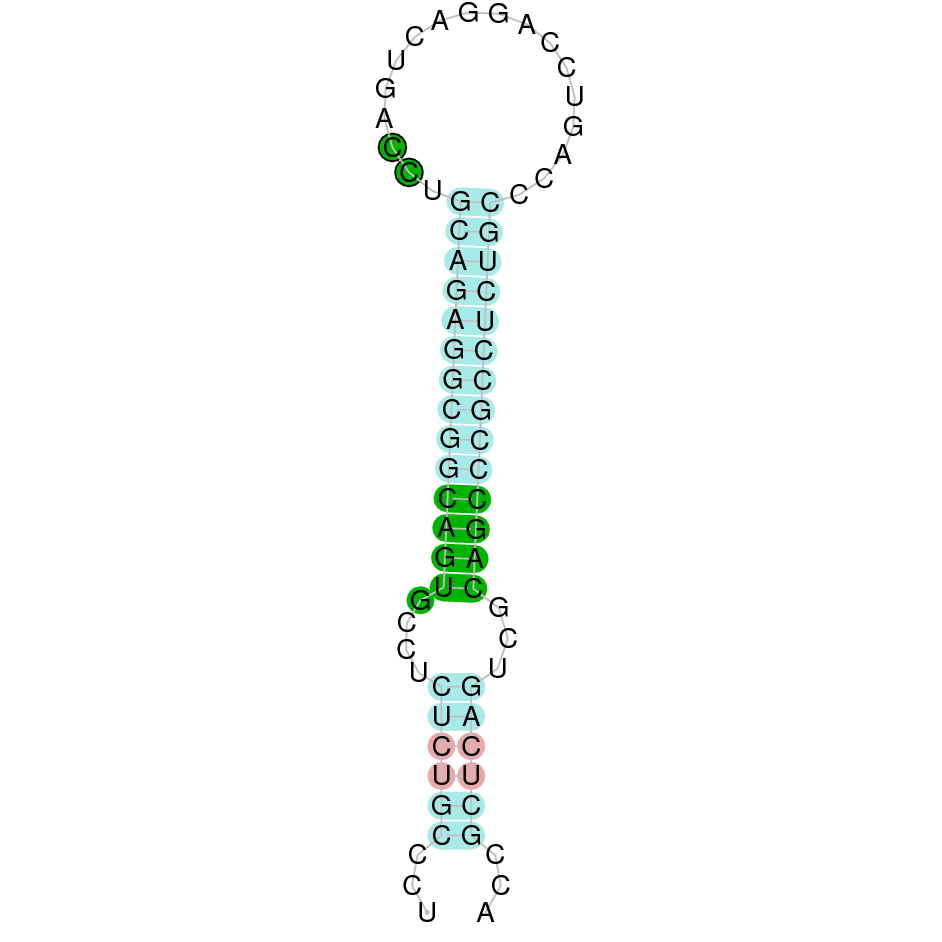 |
| SelP | |
U | JAHTZZ010000013.1 | |
|
|
(-) | |
|
|
 |
| SelR1 | |
U | JAHTZZ010000044.1 | |
|
|
(+) | |
|
|
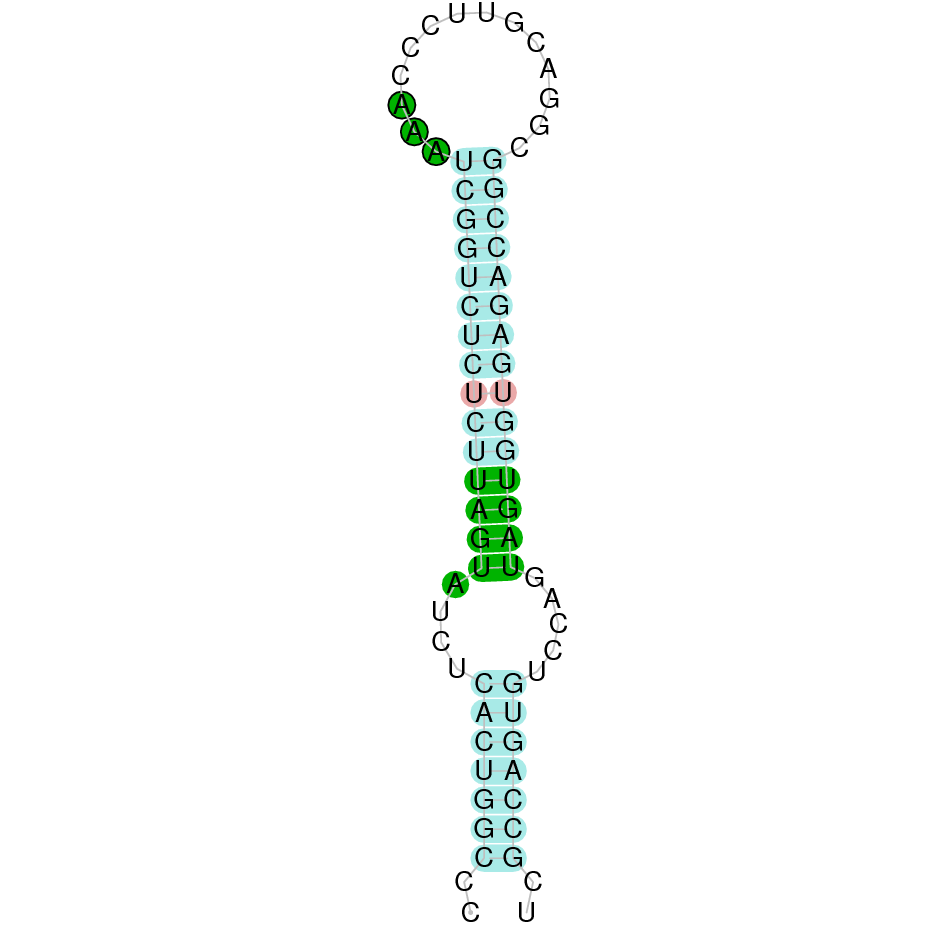 |
| SelR2 | |
Cys | JAHTZZ010000007.1 | |
|
|
(+) | |
|
|
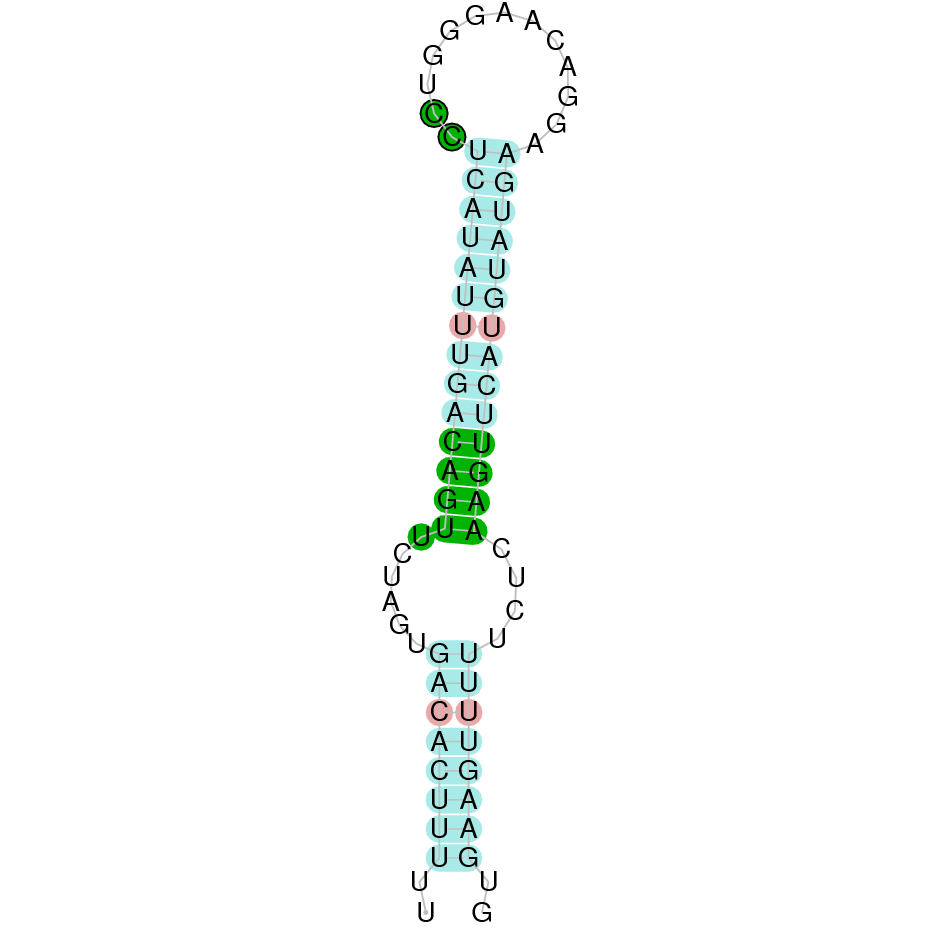 |
| SelR3 | |
Cys | JAHTZZ010000019.1 | |
|
|
(+) | |
|
|
|
| SelS | |
U | JAHTZZ010000001.1 | |
|
|
(+) | |
|
|
 |
| SelU1 | |
Cys | JAHTZZ010000010.1 | |
|
|
(+) | |
|
|
 |
| SelU2 | |
Cys | JAHTZZ010000001.1 | |
|
|
(-) | |
|
|
|
| SelU3 | |
Cys | JAHTZZ010000012.1 | |
|
|
(+) | |
|
|
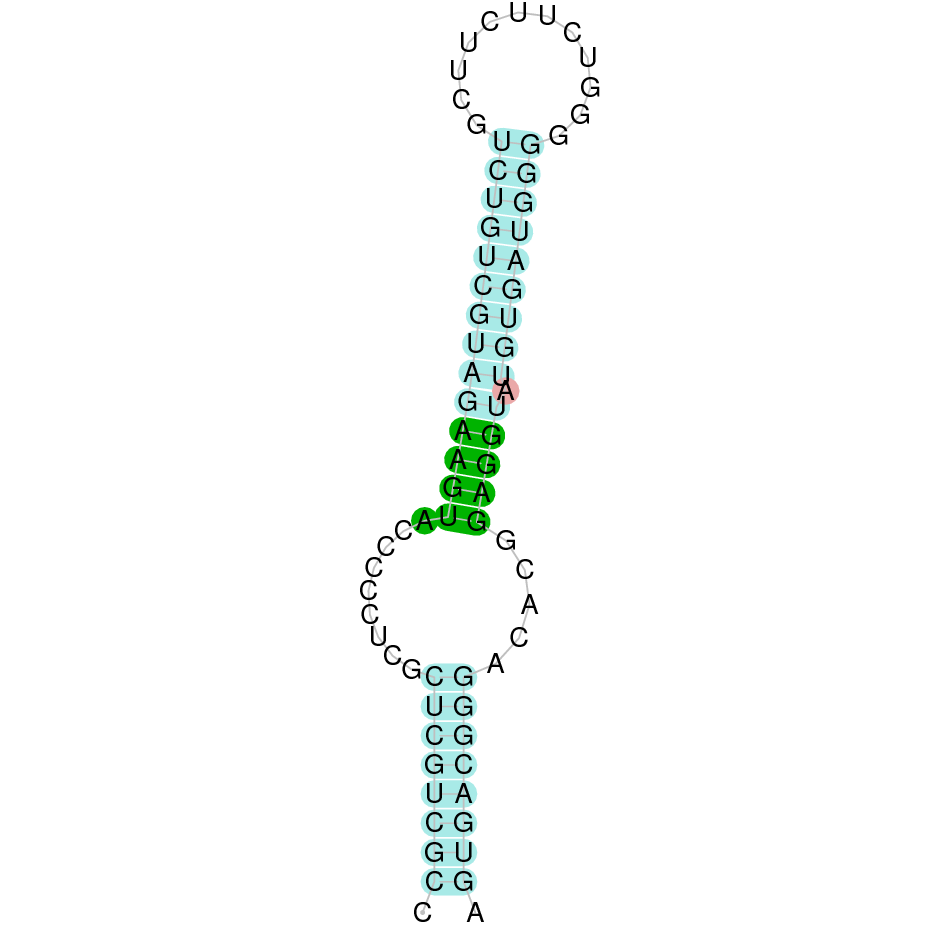 |
| TR1 | |
U | JAHTZZ010000019.1 | |
|
|
(-) | |
|
|
 |
| TR2 | |
- | JAHTZZ010003226.1 | |
|
|
(+) | |
|
|
 |
| TR3 | |
U | JAHTZZ010000006.1 | |
|
|
(+) | |
|
|
 |
| SPS1 | |
Cys | JAHTZZ010000015.1 | |
|
|
(-) | |
|
|
 |
| SPS2 | |
U | JAHTZZ010000015.1 | |
|
|
(-) | |
|
|
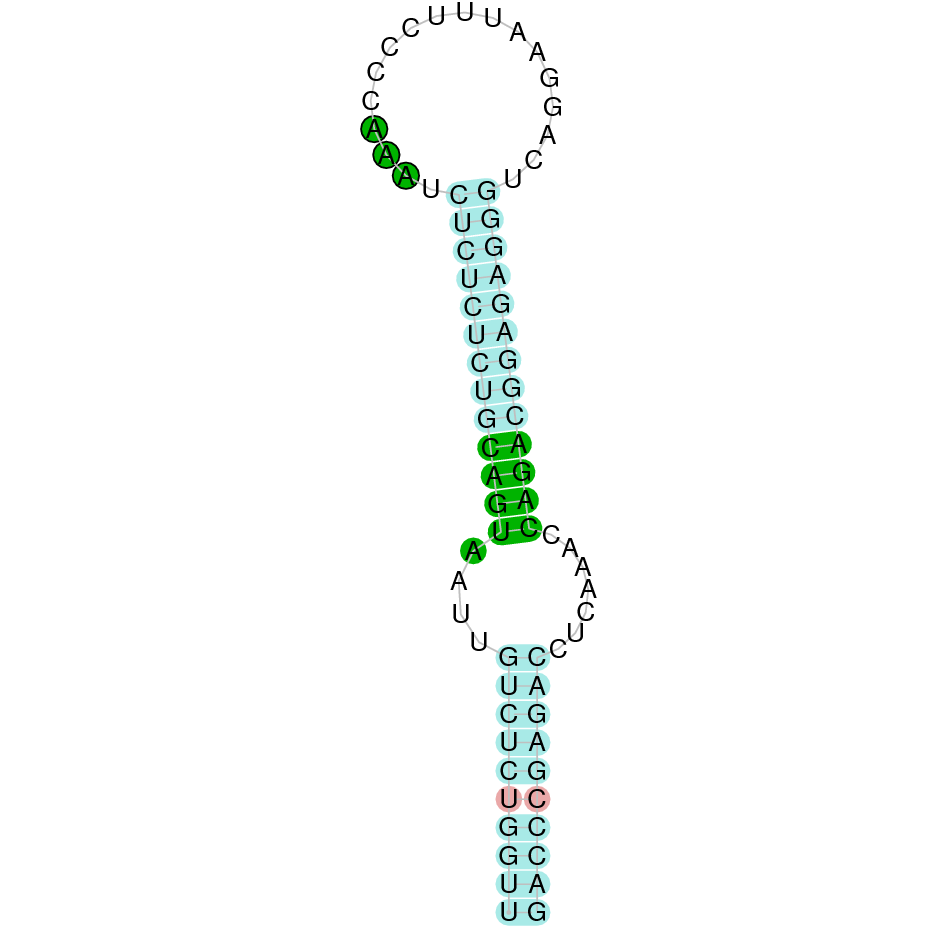 |
| PSTK | |
Cys | JAHTZZ010000003.1 | |
|
|
(-) | |
|
|
|
| SBP2 | |
- | JAHTZZ010000015.1 | |
|
|
(-) | |
|
|
|
| SECp43 | |
Cys | JAHTZZ010000017.1 | |
|
|
(-) | |
|
|
|
| SecS | |
Cys | JAHTZZ010000015.1 | |
|
|
(+) | |
|
|
 |
The aim of the project is to predict and annotate Nanger dama's selenoproteome. Therefore, a thorough computational analysis was carried out by comparing Nanger dama's genome and a reference genome, which were either Bos taurus' (phylogenetically close to Nanger dama) or Homo sapiens' (selenoproteome annotation quality is higher). All of the predicted protein results were carefully analyzed, with special emphasis on the T-Coffee output and SECIS elements prediction. The following criteria were used to determine whether a detected protein in the genome of Nanger Dama was a selenoprotein, a cysteine-containing homologue, or neither of them:
Here we present the discussion for each one of the predicted proteins (selenoprotein, machinery or non-predicted). For each protein family we designed a phylogenetic tree in order to closely observe and understand their evolutionary relationships.
Glutathione Peroxidase family (GPx)
The GPx family are widespread in all three domains of life and are involved in hydrogen peroxide signaling, detoxification of hydroperoxides, and maintaining cellular redox homeostasis [10]. In mammals, there are 8 GPx, being the GPx1 the most abundant and the first selenoprotein to be discovered in humans [9,8]. They can be classified in terms of the presence of Sec or Cys residue in their active site [9]:
- GPx1,2,3,4 and 6 contain a Sec residue in their active site
- GPx5,7 and 8 contain a Cys residue in their active site
Interestingly, in some mammals, Gpx6 homologs have not conserved the Selenocysteine aminoacid and have instead a cysteine in the active site [9].
In the phylogenetic tree of Glutathione Peroxidase family, we can observe that the predicted proteins GPx1 (predicted from Bos taurus), GPx2 (predicted from Bos taurus), GPx3 (predicted from Bos Taurus), GPx4 (predicted from Bos Taurus), GPx5 (predicted from Bos taurus), GPx6 (predicted from Homo sapiens), GPx7 (predicted from Bos taurus) and GPx8 (predicted from Homo sapiens) can be clustered together with their own query, suggesting that the prediction is correct.
GPx1
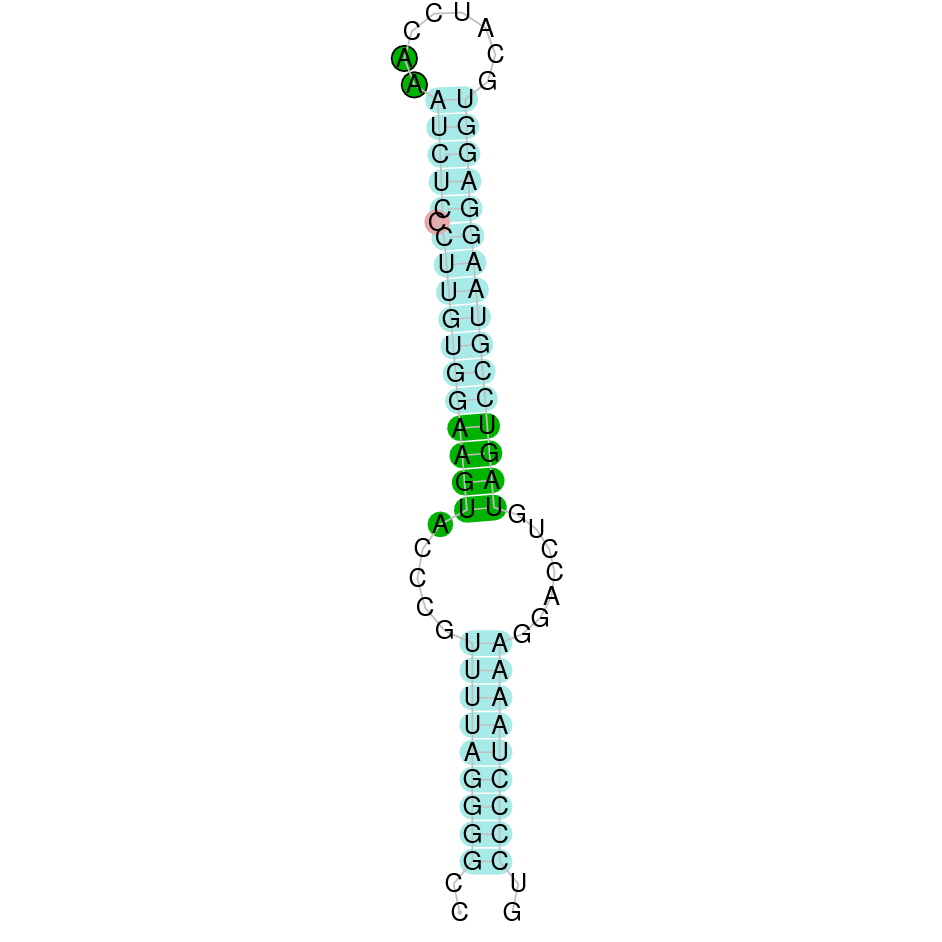
The protein GPx1 is found in the scaffold JAHTZZ010000006.1. We chose the hit with the lowest e-value (2.11e-73) and highest identity percentage between the query and the hit (99.153%). The protein is found between the nucleotide positions 49501 and 50353 on the positive strand (+). Furthermore, two exons were predicted in this protein. When T-Coffee was run, a nearly perfect alignment was obtained. T-Coffee aligns the Bos taurus protein with the predicted protein, revealing that they both contain the selenocysteine amino acid. Nevertheless, our predicted protein is missing the first methionine (which starts the protein), indicating that this region was incorrectly predicted. This can be a consequence of using Bos taurus as the query (its annotated protein starts with an A). The Seblastian predicted one selenoprotein and one secis element (grade A) in the positive strand in the protein's 3' sequence. Although the beginning of the protein could not be predicted correctly, the protein GPx1 in Nanger dama contains a selenocysteine and a Secis element, as suggested in the literature [9].
All of these indicators suggest that GPX1 from Nanger dama is a selenoprotein, an ortholog to the one found in Bos taurus.
GPx2
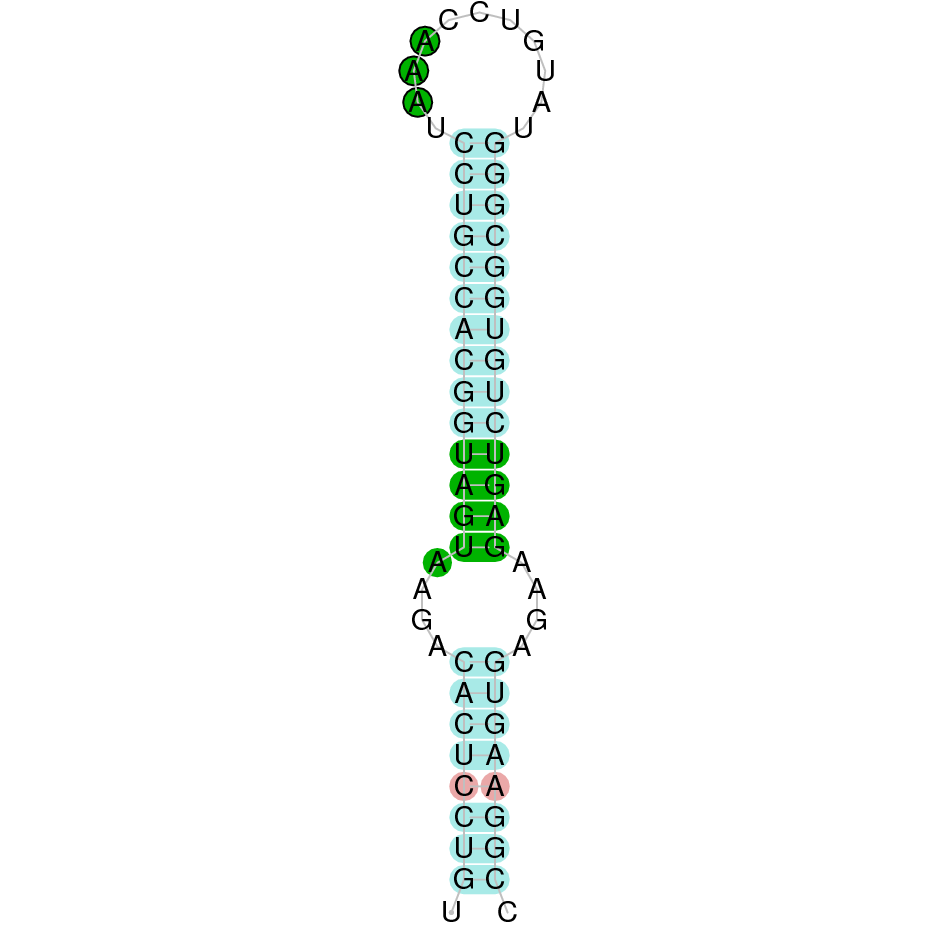
The protein GPx2 is located in the JAHTZZ0100000014.1 scaffold. We analysed this scaffold as it presented two hits with low e-values and high identity percentage. The first hit presented a 99,15% identity and an e-value significantly low of 4.41e-73. We uncovered that the protein goes from 47019 to 50622 and is located on the forward strand (+). Moreover, this protein was predicted to contain 2 exons, with no insertions or deletions. When performing the T-Coffee, we obtained an almost perfect alignment (score=1000) between the Bos taurus protein and the predicted protein, where all the residues except two were conserved. This alignment also revealed that the selenocysteine amino acid was conserved in Nanger dama's genome. The Seblastian predicted one selenoprotein and one SECIS element (grade A) in the positive strand in the protein's 3' sequence.
Therefore, all the evidence presented indicates that GPx2 from Nanger dama is an ortholog protein to the one in Bos taurus, which has a selenocysteine conserved and a SECIS element, as suggested in the literature [9]. This allows us to conclude that GPx2 is a selenoprotein which has been conserved during evolutionary events.
Gpx3
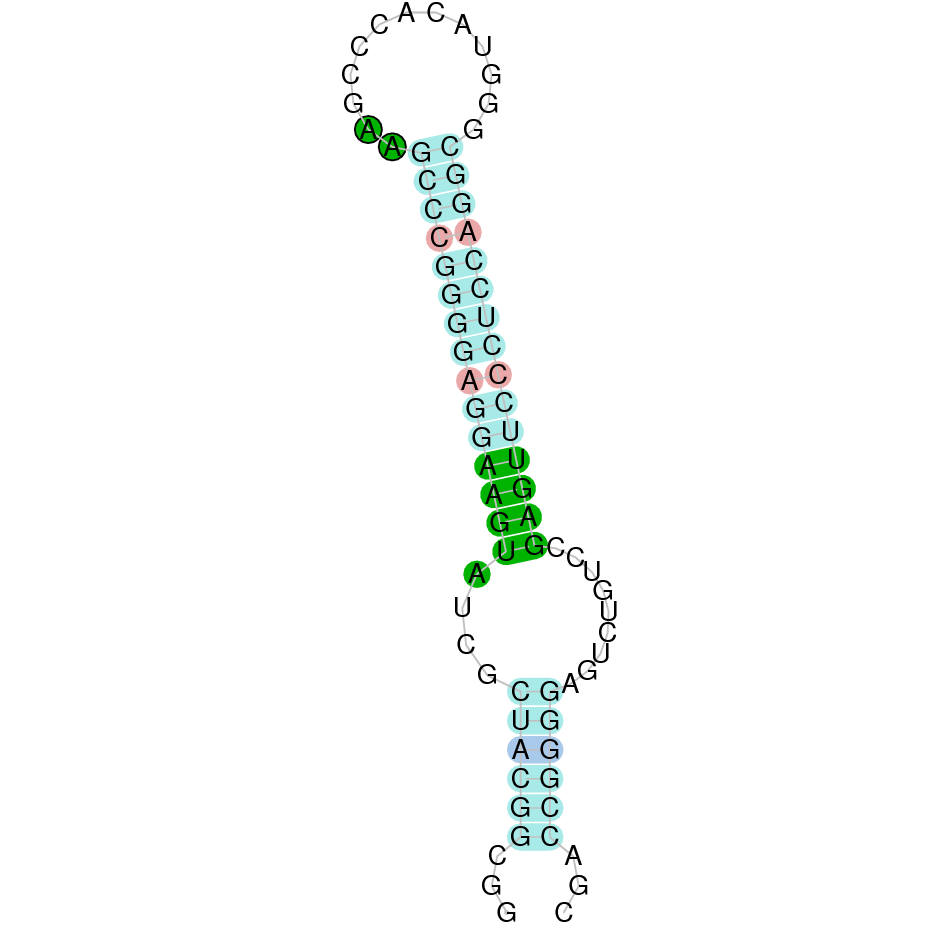
When we ran tblastn we found two scaffolds that had really similar e-values and identities in their hits. Therefore, we thought that one of them could be a duplication. On the one hand, the protein GPx3 is found in the scaffold JAHTZZ010000006.1. We chose a hit with a low e-value (3.78e-37) and high identity percentage between the query and the hit (80.233%). The protein is found between the nucleotide positions 50000 and 52638 on the reverse strand (-). Furthermore, four exons were predicted in this protein. When T-Coffee was run, a nearly perfect alignment was obtained. T-Coffee aligns the cow protein with the predicted protein, and reveals that they both contain the selenocysteine amino acid. Nevertheless, our predicted protein is missing the first methionine (which starts the protein), indicating that this region was incorrectly predicted. This can be a consequence of using Bos taurus as the query (its annotated protein starts with a L). The Seblastian predicted one selenoprotein and one SECIS element (grade A) in the protein's 3' sequence and in the same strand.
On the other hand, we also found protein SelT in the scaffold JAHTZZ010000327.1. We chose a hit with a low e-value (3.78e-37) and high identity percentage between the query and the hit (80.233%). The protein is found between the nucleotide positions 47619 and 50257, on the forward strand (+). Furthermore, four exons were also predicted in this protein. When T-Coffee was run, as happened evaluating the previous scaffold, a nearly perfect alignment was obtained. T-Coffee aligns the cow protein with the predicted protein, revealing that they both contain the selenocysteine amino acid. The Seblastian also predicted one selenoprotein and one secis element (grade A) in the protein's 3' sequence.
In the T-Coffee results we can observe that the two hits have the same number of misalignments, 3. Therefore, we consider that our protein is located in both scaffolds, one having the orthologous selenoprotein and the other being a paralogous which may have been duplicated in a recent duplication event.
Although the beginning of the protein could not be predicted correctly, the protein GPx3 in Nanger dama contains a selenocysteine and a SECIS element, as suggested in the literature [9]. All of these indicators suggest that GPx3 from Nanger dama is a selenoprotein, an ortholog protein to the one found in Bos taurus.
Gpx4
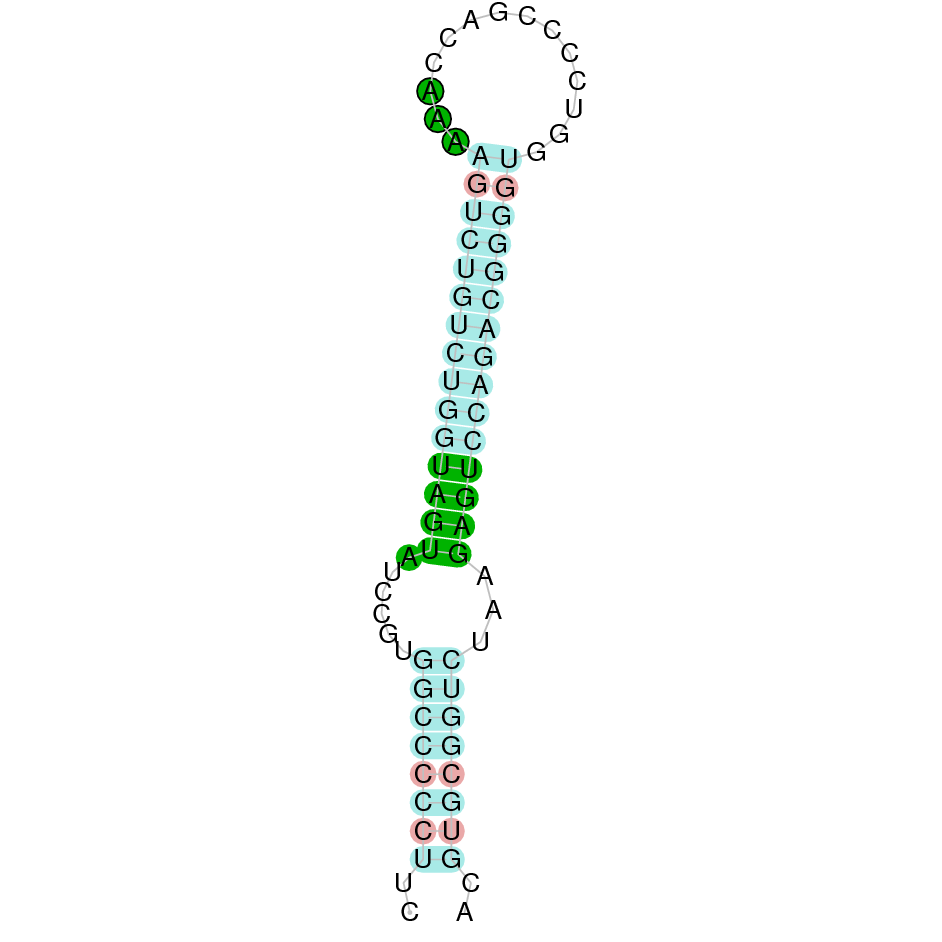
The GPx4 protein is located in the JAHTZZ010000006.1 scaffold. We chose this scaffold as it presented the best hits, with the lowest e-value (3.81e-53) and a percentage identity of 68.05%. We found out that the analysed protein goes from 49864 to 50431 in the reverse negative strand (-). Moreover, the protein contains three exons, with no insertions or deletions in either of them. The alignment obtained from the comparison of the two sequences showed that the protein was fully conserved in Nanger dama's genome (score=1000), as all the nucleotides of the sequence were aligned. Nevertheless, our predicted protein is missing the first methionine (which starts the protein), indicating that this region was incorrectly predicted. This can be a consequence of using Bos taurus as the query (its annotated protein begins with an R). In any case, the alignment revealed that the selenocysteine aminoacid was conserved in Nanger dama's genome. Furthermore, Seblastian predicted one selenoprotein and one secis element (grade A) in the protein's 3' sequence.
Although the beginning of the protein could not be predicted correctly, the protein GPx4 in Nanger dama contains a selenocysteine and a SECIS element, as suggested in the literature [1].
Therefore, all the evidence presented indicates that GPx4 from Nanger dama is an ortholog protein to the one in Bos taurus. This allows us to conclude that GPx4 is a selenoprotein which has been conserved and has conserved its selenocysteine during evolutionary events.
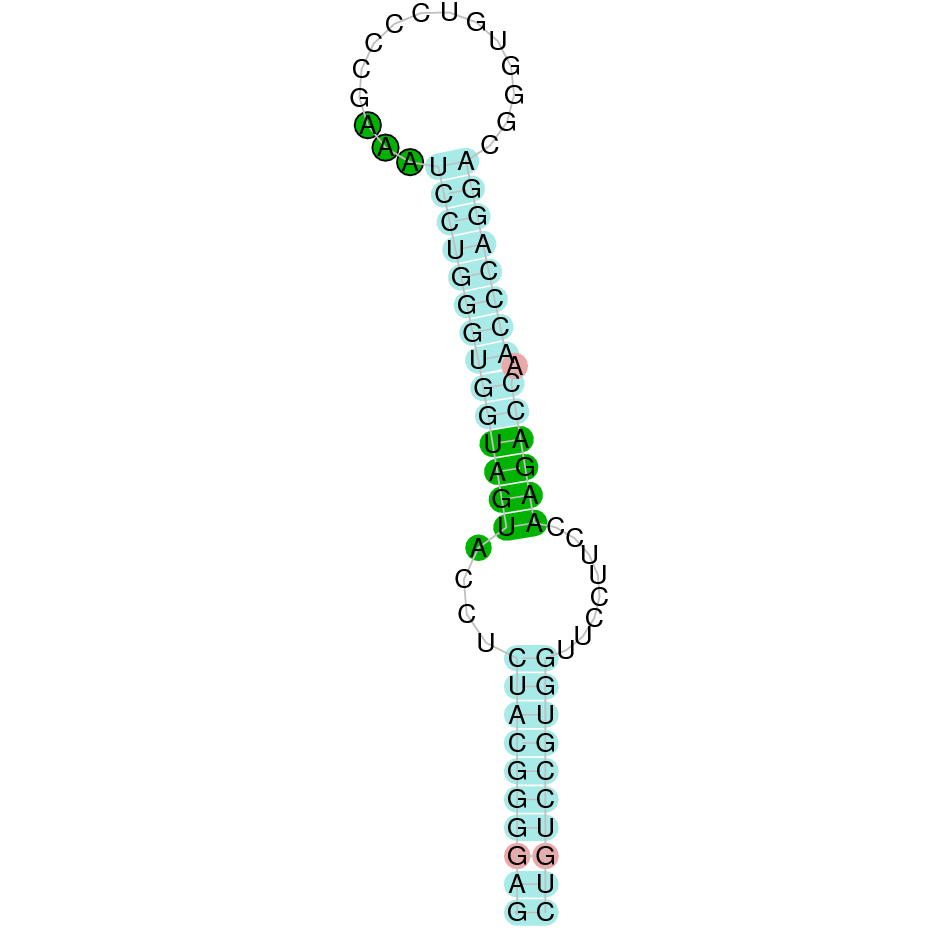
GPx5
The protein GPx5 is found in the scaffold JAHTZZ020000014.1. We chose the hit with the lowest e-value (3.31e-39) and highest identity percentage between the Bos taurus query and the hit (90.411%). The protein is found between the nucleotide positions from 76953 to 50000 on the reverse strand (-). Furthermore, ten exons were predicted in this protein. This can be due to an Exonerate error, which probably predicted a larger protein. Therefore, in T-Coffee, the first part of the predicted Nanger dama protein, could not align with Bos taurus protein. Furthermore, in these parts, we could observe some X which we suspected were standing for STOP codons, instead for selenocysteine. The last middle part of the predicted protein (which begins with a methionine), aligns perfectly with Bos taurus protein. We can observe that GPx5 does not contain any selenocysteine, but contains conserved cysteine residues, as suggested in the literature [1]. Regarding Seblastian analysis, it predicted a selenoprotein. We also predicted a SECIS, but in this case it was found in the positive strand (+) between the position 84100 and 84175. Therefore, based on the criteria we have established previously, we will discard this SECIS element, as it is found in the opposite strand of our predicted protein.
In conclusion, this suggests that Nanger dama's GPx5 is not a selenoprotein but a cysteine-containing homolog.
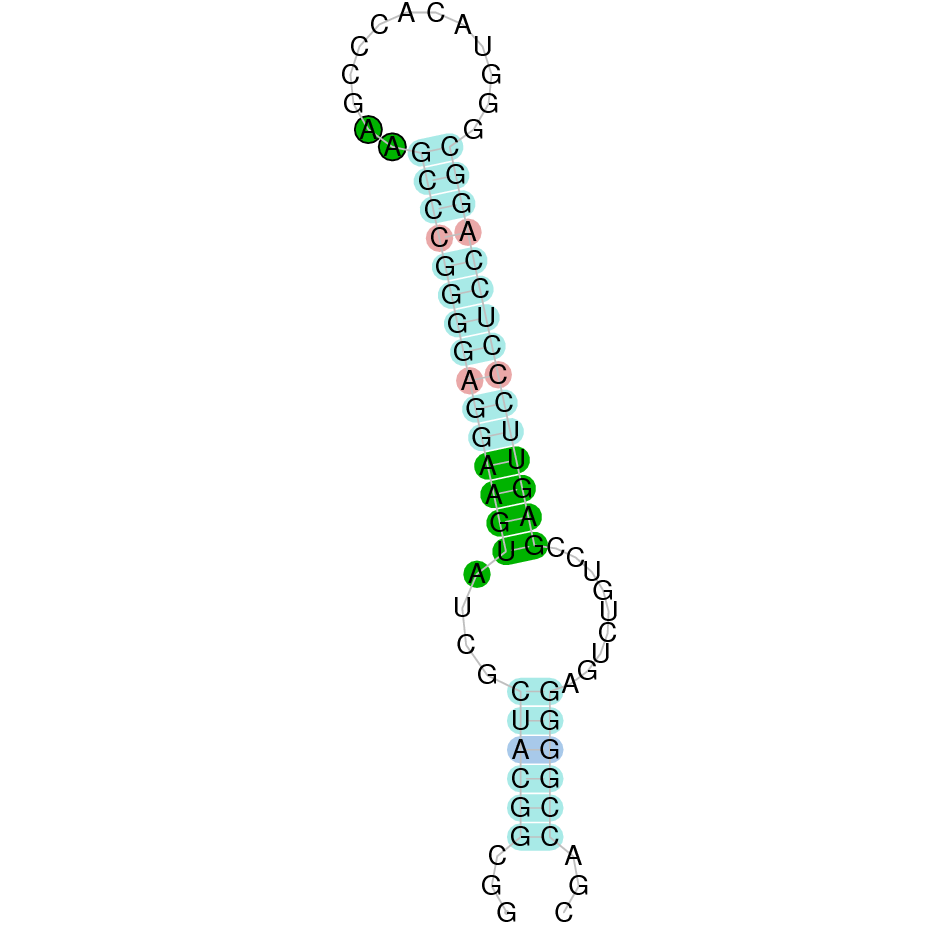
Gpx6
For the GPx6 protein, the analysis was performed with two different scaffolds (JAHTZZ010000014.1 and JAHTZZ010000327.1), the first alignment was not correct and seemed like the prediction was not done optimally. This led us to analyse the second scaffold, which was the second one with the best tblastn hit values. In both cases the reference query used was Homo sapiens, as it was well annotated and using Bos taurus' annotation we did not obtain an optimal alignment. Therefore, the protein GPx6 is located in the JAHTZZ010000327.1 scaffold, between the nucleotide positions from 44058 to 51272, specifically, in the forward positive strand (+). The best hit of this protein had an e-value of 1.64e-28 while a percent identity of 50%. The predicted protein presented five coding exons. The alignment obtained using T-Coffee showed that the protein was conserved, although it had some changes in amino acids and it also revealed that the selenocysteine was conserved in our subject's (Nanger dama) predicted protein, as suggested in the literature [9]. Seblastian predicted one selenoprotein and one secis element (grade A) in the positive strand (+) in the protein's 3' sequence.
Our results indicate that GPx6 is a selenoprotein present in Nanger dama's genome, which has conserved the Selenocysteine.
Gpx7
The protein GPx7 is located in the JAHTZZ010000016.1. This scaffold was chosen as it was the one which presented the best hit with the lowest e-value (2.50e-57) and the highest percent identity (97,9%). The predicted protein goes from 49713 to 51841 and is found in the reverse strand (-). The predicted protein contains two exons which go from position 49713 to position 49986 (no deletions or insertions) and the other which goes from position 51714 to position 51841 and presents one deletion. When performing the T-Coffee, we obtained a robust alignment (score=997) between the Bos taurus protein and the predicted protein in Nanger dama, where it looked like the protein had been conserved. This alignment revealed that the protein contained different cysteine amino acids in its sequence, which have all been conserved in our subject's genome, as suggested in the literature [1]. The sequence does not contain any selenocysteine amino acid which indicates that it is not classified as a selenoprotein. Furthermore, we could not find any protein using Seblastian, and no Secis element was found.
Taken as a whole, the protein GPx7 in Nanger dama lacks both a selenocysteine and a Secis element, but contains conserved cysteine amino acids. All of this suggests that GPx7 is a cys-containing homologue. However, to confirm these results it could be of interest aligning Nanger dama's GPx7 with Homo sapiens', as then we could see the whole protein and probably obtain more accurate results.
Gpx8
We decided to align the Nanger dama genome with Homo sapiens (a better well-annotated genome), as we realized that Bos taurus protein did not begin with a methionine and, as it had happened in other proteins from this family, our protein would not be fully predicted. The protein GPx8 is found in the scaffold JAHTZZ010000013.1. We chose the hit with the lowest e-value (1.27e-45) and a high identity percentage between the query and the hit (89.773%). The protein is found between the nucleotide positions 49192 and 53784 on the positive strand (+). Furthermore, three exons were predicted in this protein. When T-Coffee was run, a nearly perfect alignment was obtained. T-Coffee aligns the human protein with the totally predicted protein (as it starts with a methionine), revealing that they do not contain the selenocysteine amino acid, but a cysteine amino acid. The Seblastian did not predict any selenoproteins, but it did correctly predict one SECIS element (grade B) in the protein's 3' sequence. However, it predicted it in the reverse strand, between the positions 40799 and 40882. Therefore, based on the criteria we have established, we will also discard this SECIS element.
Taken all together, the protein GPx8 in Nanger dama does not contain a selenocysteine amino acid nor a Secis element. However, it contained conserved cysteines, as suggested in the literature [9]. All of these indicators suggest that GPx8 from Nanger dama is a cysteine homologous protein.
Thyroid Hormone Deionidases (DI)
They are involved in regulation of the thyroid hormone activity by reductive deodination and are found in simple eukaryotes, bacteria and mammals. Particularly, in mammals, this family consists of three paralogous proteins: DIO1,DIO2 and DIO3. On one hand, DIO1 and DIO3 catalyze the removal of iodine of T4, therefore, producing T3 in plasma (DIO1) or peripheral tissues (DIO3). On the other hand, DIO2 catalyzes this reaction in specific tissues [9].
In the phylogenetic tree of the Thyroid Hormone Deiodinases family, we can observe that the predicted proteins DI3, predicted in Bos taurus, can be clustered together with their own query, suggesting that the prediction is correct. However, DI1 and DI2 predicted proteins aren't classified with their own query.
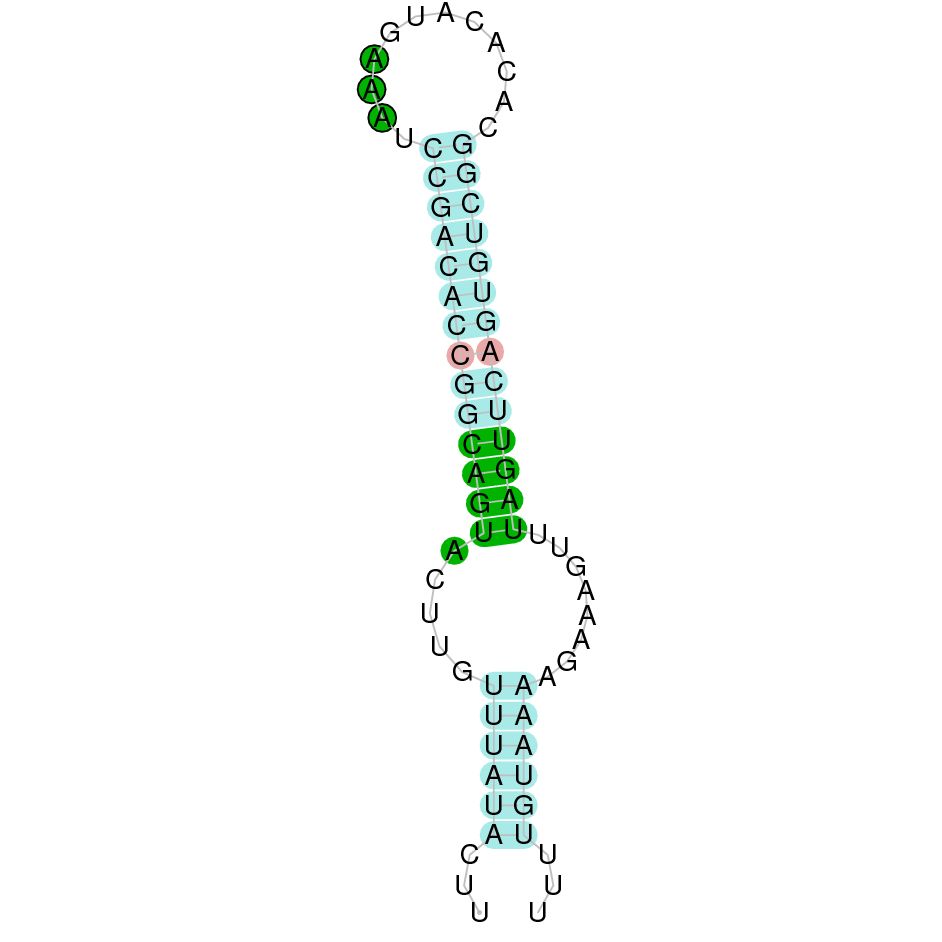
DI1
We aligned the DI1 protein from Bos taurus and we obtained three scaffolds with significant hits (JAHTZZ010000001.1, JAHTZZ010000014.1 and JAHTZZ010000016.1). First of all, we analysed JAHTZZ010000001.1 (we selected the hit with 44.792 % identity and e-value of 2.76e-37). However, in the T-Coffee results we did not observe a good alignment. The same happened for the following scaffold, JAHTZZ010000014.1, in which we selected a hit that presented 43.791% identity and 1.53e-26 of e-value. However, we finally selected a hit contained in the scaffold JAHTZZ010000016.1, as it has a percentage of identity (94.737%) and e-value (5.59e-68) more significant than the others. We obtained a good alignment with T-Coffee, with the protein starting with M and a score of 1000. The gene is found in the Nanger dama genome in the reverse strand (-) between the positions 31652 and 50341 and we predicted 4 exons. T-Coffee aligns the Bos taurus protein with the predicted protein, and both of them contain the selenocysteine amino acid. Seblastian predicted a selenoprotein, and one SECIS element (grade A) in the negative strand was correctly predicted in the protein's 3' sequence.
The protein DI1 in Nanger dama contains a selenocysteine and a SECIS element in the negative strand. All these signs would suggest that DI1 is a selenoprotein.
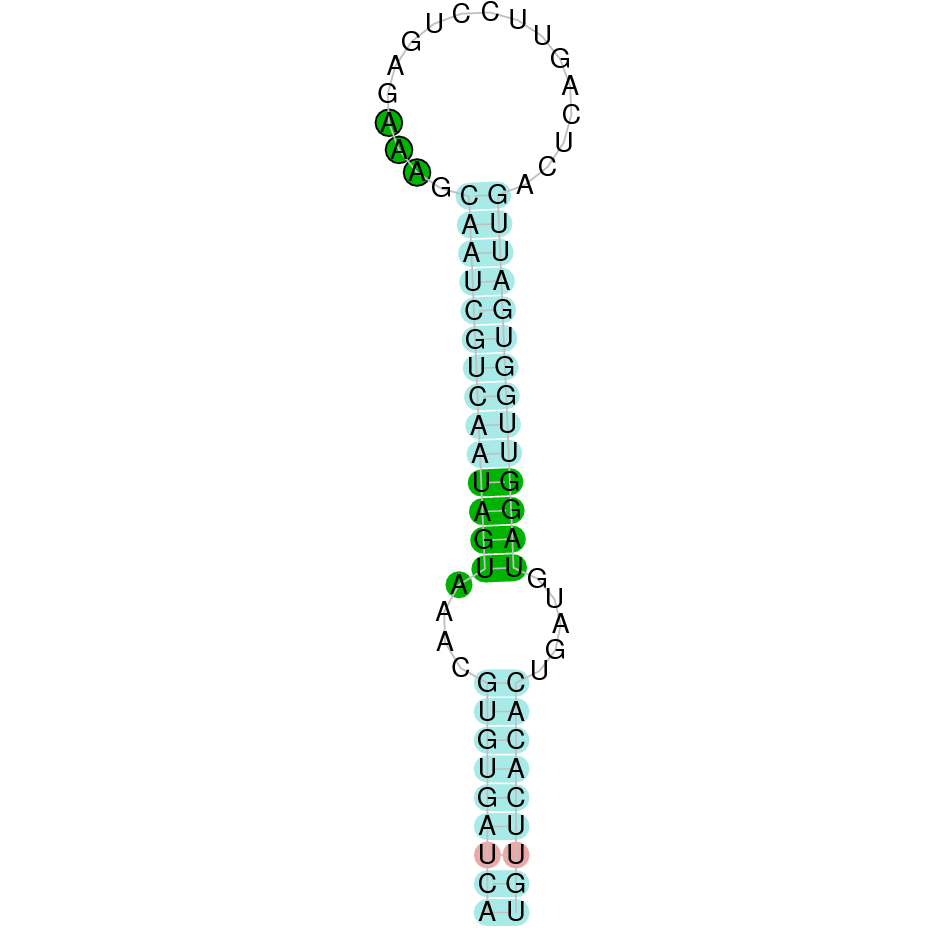
DI2
DI2 is a protein found in the scaffold JAHTZZ010000014.1 (it was chosen the hit with the lowest e-value: 7.47e-122). The identity percentage between the query and the hit is 96,4%. The protein is found between the nucleotide positions 41588 and 50581, specifically, in the positive strand (+). Furthermore, two exons were predicted in this protein. When running T-Coffee, a perfect alignment was visualized. T-Coffee aligns the Bos taurus protein (starting with a methionine) with the predicted protein, and both of them contain the selenocysteine amino acid. Although no protein was predicted using Seblastian, one secis element (grade A) in the positive strand was correctly predicted in the protein's 3' sequence in the positive strand.
We can conclude that the protein DI2 in Nanger Dama contains a selenocysteine which has been conserved and a Secis element. All these signs would suggest that DI2 is a selenoprotein.
DI3
DI3 is a protein found in the scaffold JAHTZZ010000001.1 (it was chosen the hit with the lowest e-value: 4.23e-149). The identity percentage between the query and the hit is 91.892. The protein is found between nucleotide positions 49203 and 50000 on the positive strand (+). Two exons were predicted for this protein. When running T-Coffee, a perfect alignment was visualized. T-Coffee aligns the Bos taurus protein with the predicted protein, and both of them contain the selenocysteine amino acid. However, the predicted protein does not begin with a methionine, indicating that the beginning of the protein has not been correctly predicted as a result of using Bos taurus as the protein query. With Seblastian, it was predicted one selenoprotein and one Secis element (grade A) in the positive strand of the protein's 3' sequence.
Therefore, the protein DI3 in Nanger dama contains a conserved selenocysteine and a Secis element. All these signs suggest that DI3 is a selenoprotein.
MsrA: methionine-S-sulfoxide reductase
This family consists of three proteins: MsrB1,2 and 3, being the MsrB1 the most abundant in mammals. MsrB2 and 3 contain a Cys residue in place of Sec in the active site of the enzyme. This family catalyses repair of the R enantiomer of oxidized methionine residues in proteins, so they have an essential role in protecting the cell from oxidative stress [2]. In relation to its localization, they can be found in the mitochondria, the nucleus or the cytosol, depending on the alternative splicing that takes place [4]. For this protein, we decided to choose a Homo sapiens query, as MsrA protein in Bos taurus did not begin with a methionine. When running tblastn we obtained 3 scaffolds, but only two of them presented both significant e-values and identity. Therefore, we first analysed the following scaffold JAHTZZ010000049.1 (we selected a hit with 59.500% identity and evalue of 1.17e-69), but we obtained a bad alignment in T-Coffee, with a lot of gaps. Therefore, we decided to analyse another scaffold JAHTZZ010000001.1, in which we selected another hit with a low e-value (5.26e-26) and a percentage identity of 92.727%. We found out that the predicted protein goes from 7084 to 67095 in the reverse negative strand (-). Moreover, Exonerate predicted that the protein contains 14 exons. However, the alignment obtained from the comparison of the two sequences showed a lot of gaps and suggested that the protein was not conserved in Nanger dama's genome. The alignment also revealed that the Selenocysteine amino acid was not conserved in Nanger dama's genome.
Seblastian did not predict any selenoproteins and no SECIS element was found. Therefore, we concluded that, in this situation, no homologous exists on the genome of Nanger dama. In this case, the MsrA protein could not be predicted in Nanger dama's genome, which may have been due to a prediction error.
Selenoprotein 15
They are thioredoxin-like fold proteins that reside on the ER and that form a distinct selenoprotein family. They are found in many mammalian tissues, nevertheless, they are specially expressed within the prostate, liver, kidney and testis. Also, Sel15 is involved in glycoproteins folding and has been thought to have a possible role in cancer etiology and regulation of redox homeostasis in the ER [1].
For this protein, we analysed two hits from two different scaffolds, as they had low e-values and high identities. The first hit, with an e-value of 1.87e-80 and identity of 90.741 was found in scaffold JAHTZZ010000009.1. The protein is found between the nucleotide positions 50000 and 50485 on the forward strand (+). When T-Coffee was run, a good alignment was obtained and we could observe that the selenocysteine was conserved in Nanger dama. Seblastian could not predict a selenoprotein, but we also could find a SECIS in the forward strand.
The second hit analysed was in the following scaffold JAHTZZ010000016.1 and had an e-value of 1.73-18 and the identity percentage was 97.674 percent. The protein is found between the nucleotide positions 9542 and 50128 on the forward strand (+). Five exons were predicted in this protein. When T-Coffee was run, it displayed a perfect alignment. T-Coffee aligns the Homo sapiens with the predicted protein, and it was discovered that the selenocysteine amino acid is conserved in both the Homo sapiens Sel15 protein and the predicted Sel15 protein in Nanger Dama. The predicted protein starts with methionine, which means that the beginning of the protein has been correctly predicted. Finally, in the tcoffee results we could observe less gaps and misalignments than in the previous analysed hit. Seblastian predicted the presence of a selenoprotein, while one SECIS element (grade A) in the forward strand was correctly predicted in the 3' sequence of the protein.
Taken all together, the protein Sel15 in Nanger dama contains a selenocysteine and a Secis element. All these signs would suggest that Sel15 is a selenoprotein.
Thioredoxin-like family
This family contains a thioredoxin-like fold and is characterized by the presence of a conserved Cys-x-x-Sec motif so, they proposed that this family were thiol-based oxidoreductases. In this family, they belong: Selenoprotein W (SelW), T (SelT), H (SelH) and V (SelV) [9,6].
In the phylogenetic tree of the Thioredoxin-like family, we can observe that the predicted proteins SelW1 and SelW2, predicted in Homo Sapiens, can be clustered together with their own query, suggesting that the prediction is correct. However, SelT and SelH predicted proteins aren't classified with their own query. Also, it should be noted that SelV has not been included in the phylogenetic tree as it could not be predicted.
SelH
This protein contains a Sec-residue within the Cys-x-x-Sec motif and it has a unique subcellular pattern: it has been found to localize specifically to the nucleoli [9]. Also, it has a DNA-binding domain and a glutathione peroxidase activity. Interestingly, some analysis suggest that there is a differential expression between embryonic and adult tissue, being higher during embryonic development and lower in adult tissues [11, 15]. In addition, it has been thought to transduce oxidant signals by modulation gene expression [17].
For this protein, we used SelH from Bos taurus as the query, because it started with a methionine. The SelH protein is located in the JAHTZZ010000007.1 scaffold. We chose this scaffold as it presented the best hit, with the lowest e-value (3.68e-43) and a percentage identity of 93.750%. We found out that the analysed protein goes from 50000 to 50365 in the reverse negative strand (-). Moreover, the protein contains only one exon. The alignment obtained from the comparison of the two sequences showed that the protein was conserved in Nanger dama's genome. However, the alignment also revealed that the selenocysteine amino acid was not conserved in Nanger dama's genome. However, cysteine amino acids are conserved in both Nanger dama and Bos taurus. Seblastian did not predict a selenoprotein, and a SECIS element was found in the negative strand (3' UTR).
Taken all together, the protein SelH does not conserve the selenocysteine amino acid but it does conserve a cysteine. Moreover, a selenoprotein was predicted and it contained a SECIS element. Our results suggest that SelH is a cysteine-containing homolog, which has lost a selenocysteine due to an evolutionary event.
SelT
SelT is also one of the first identified Sec-containing proteins and it is predominantly localized to the ER and Golgi [9]. It has been identified a higher expression of SelT during embryonic development [6]. It has been shown that higher levels of SelT are involved in ontogenesis and regenerative processes in neural, metabolic and endocrine tissues [9].
The protein SelT is found in the scaffold JAHTZZ010000447.1. We chose the hit with the lowest e-value (4.16e-20) and highest identity percentage between the query and the hit (100%). The protein is found between the nucleotide positions 29333 and 54270, on the forward strand. Furthermore, five exons were predicted in this protein. When T-Coffee was run, a nearly perfect alignment was obtained. T-Coffee aligns the cow protein with the predicted protein, revealing that they both contain the selenocysteine amino acid. Nevertheless, our predicted protein is missing the first methionine (which starts the protein), indicating that this region was incorrectly predicted. This can be a consequence of using Bos taurus as the query (its annotated protein starts with a L). The Seblastian did not predict any proteins, but it did correctly predict one secis element (grade A) in the protein's 3' sequence.
Although the beginning of the protein could not be predicted correctly, the protein SelT in Nanger dama contains a selenocysteine and a Secis element. All of these indicators suggest that SelT from Nanger dama is a selenoprotein as it conserves a selenocysteine and a SECIS element. It is an orthologous protein to the one found in Bos taurus.
Selenoprotein W family
Selenoprotein W (SelW) is one of the first selenoprotein families characterized and one of the most abundant selenoproteins in mammals. Its function is still unknown but it has been thought that it might play a role in a redox-related process [9,18]. Interestingly, SelW2 has generated an homolog of SelW2 in mammals, Rdx12, as a result of the Sec-to-Cys conversion. On the contrary, SelW1 takes part of the selenoproteins found in all the vertebrates [11].
SelW1
For this protein SelW1, we used Homo sapiens' SelW1 as a reference protein query as the predictions obtained using Bos taurus were not suitable.
Firstly, we analysed the JAHTZZ010000009.1 scaffold but the alignment obtained did not predict the protein and therefore carried the analysis with a second scaffold named JAHTZZ010000011.1. SelW1 is located in the JAHTZZ010000011.1 scaffold, specifically it goes from 49624 to 50251 in the forward positive strand (+). The best hit from this scaffold had an e-value of 4.08e-08 while it presented an percent identity of 44.928%. Exonerate predicted the presence of five exons in the predicted SelW1 protein. The alignment performed with T-Coffee looked robust (score=1000) with almost all the amino acids aligned. Specifically, the Selenocysteine (Sec) present in Homo sapiens' query was conserved in Nanger dama's SelW1 protein. Seblastian did predict a selenoprotein and a SECIS element was found in the positive strand (3'UTR).
Our results suggest that SelW1 is a selenoprotein present in Nanger dama's genome, as it has conserved its Selenocysteine (Sec) and presents a SECIS element.
SelW2
SelW2 protein is found in the JAHTZZ010000009.1 scaffold, and was predicted using Homo sapiens' sequence as the reference query. The hit analysed presented an e-value of 7.38e-21 and a percent identity of 63.415%. The protein is located from position 50000 to 50968 in the reverse negative strand (-). Exonerate predicted that the protein SelW2 in Nanger dama's genome contained four exons. The alignment obtained was good and indicated that the protein from our subject was conserved, conserving as well the cysteines present in the reference annotated protein. Seblastian did not predict any selenoproteins while it did find SECIS element (Grade B) in the protein's 3' sequence.
Taken all together, the protein SelW2 did contain various conserved cysteines and a SECIS element (grade B). All this evidence would suggest that SelW2 is a cysteine-containing homolog.
SelV
SelV is one of the least characterized selenoproteins. It recently evolved, most likely by duplication from SelW followed by the addition of N-terminal sequences, not present in SelW proteins. Its function is still unknown but it has been thought to be involved in some redox-related reactions [1,9].
In the case of the SelV protein, before starting the analysis we observed that the Bos taurus did not present the annotated protein. Therefore, we used the Homo sapiens' SelV protein as a reference. When performing tblastn, we only obtained one hit which belonged to the JAHTZZ010000009.1 scaffold. It had an e-value of 1.66e-07 and a percent identity of 48.333. However, the obtained alignment was very bad and did not predict the protein correctly. As the Bos taurus is phylogenetically closer to Nanger dama than Homo sapiens, we hypothesized that if SelV was not present in Bos taurus it made sense that it also could not be found in Nanger dama's genome as it may have been lost in an evolutionary event. Seblastian did not predict any selenoprotein, however, a SECIS element was found in the positive strand.
We can conclude that our results suggest that SelV may not be conserved in Nanger dama's genome and it could not be predicted.
SelI
The SelI protein is only found in vertebrates. It is a transmembrane protein with a CDP-alcohol phosphatidyltransferase domain that is also seen in the phosphotransferases for choline (CHPT1) and choline/ethanolamine (CEPT1), which both are involved in de novo synthesis of some phospholipids. Unlike these two enzymes, Sell contains a Sec residue [9,7].
For this protein, when we ran tblastn we started analysing the following scaffold JAHTZZ010000006.1. From this, we selected the best hit (which had a 77.739% identity and an e-value of 3.15e-122). However, when we obtained the results in T-Coffee a bad alignment was observed between the predicted protein of Nanger dama and Homo sapiens' SelI. Therefore, we decided to do the same process for another hit. We took one hit of the following scaffold, JAHTZZ010000008.1 , which had an e-value of 1.08e-26 and 84.507% identity. The protein is located between the nucleotide 46523 and 85237 in the reverse strand (-). T-Coffee aligns the Homo sapiens protein with the predicted protein, and it was discovered that the selenocysteine amino acid is conserved in both the Homo sapiens SelI protein and the predicted SelI protein in Nanger dama. Seblastian did predict a selenoprotein and a SECIS (grade A) in the negative strand in the protein's 3' sequence.
Our results suggest that SelI is a selenoprotein present in Nanger dama's genome, as it has conserved its Selenocysteine (Sec) and presents a SECIS element.
SelK
They belong to the type III category of transmembrane proteins and are found in the ER membrane. They have a single transmembrane domain in the NH2-terminal sequence, a glycine-rich section, and Sec residues in a specific place in the COOH-terminal end of the proteins. It is known they contain functional ER stress response elements and that situations that promote the accumulation of misfolded proteins in the ER up-regulate their production. For that, it has been thought that SelK could participate in binding misfolded proteins and targeting them to proteasome-dependent degradation [1].
For this protein, we analysed two hits from two different scaffolds, as they had a similar low e-values and high percent identity. The first hit, with an e-value of 1.97e-14 and identity of 84.444 was found in the scaffold JAHTZZ010000019.1. When T-Coffee was run, a bad alignment with gaps inside the protein sequence was obtained. Therefore, the second hit of the tblastn was analysed.
SelK is a protein found in the scaffold JAHTZZ010000006.1. The hit had an e-value of 7.51e-13 and the identity percentage was 91.176%. The protein is found between the nucleotide positions 46846 and 52353 on the forward strand (+). Four exons were predicted in this protein. When T-Coffee was run, it displayed a perfect alignment. T-Coffee aligns the Bos taurus with the predicted protein, and it was discovered that the selenocysteine amino acid is conserved in both the Bos taurus SelK protein and the predicted SelK protein in Nanger dama. The predicted protein starts with methionine, which means that the beginning of the protein has been correctly predicted.
Seblastian predicted one selenoprotein and one SECIS element (grade A) in the positive strand of the protein's 3' UTR sequence. Taken all together, the protein SelK in Nanger dama contains a selenocysteine and a Secis element, suggesting that SelK is a selenoprotein.
SelM
SelM is a distant homolog of Sep15, they share 31% sequence identity. They are thioredoxin-like fold proteins that reside on the ER. Sep15 is expressed mostly in the prostate, liver, kidney and tesis, whereas SelM is highly expressed in the brain. Also, it has been suggested to play a role as a neuroprotective protein, in fact, in humans, it has been linked to family early onset Alzheimer's disease and hepatocellular carcinoma [9].
The protein SelM is located in the scaffold JAHTZZ010000007.1 (it was chosen the hit with the lowest e-value: 1.19e-25). The percentage of identity between the query and the hit is 97.368%. The protein is located in the negative strand between the nucleotide positions 49952 and 52475. In this protein, five exons were predicted. When running tcoffee, a perfect alignment was visualized. Both the cow protein SelM and the predicted SelM protein in Nanger dama conserve the Selenocysteine. The predicted protein also starts with methionine, which means that the beginning of the protein has been correctly predicted. Seblastian predicted one selenoprotein and one SECIS element (grade A) in the negative strand of the protein's 3' sequence.
Taken all together, the protein SelM in Nanger dama contains a selenocysteine and a Secis element. All these signs would suggest that SelM is a selenoprotein.
SelN
SelN is an ER-resident transmembrane glycoprotein that is highly expressed during embryonic development and to a lesser extent in adult tissues including skeletal muscle. For that, mutations in the human SelN gene are associated with a group of early-onset muscle disorders [9].
This time we decided to use Homo sapiens as the query, because Bos taurus protein did not begin with a methionine. The SelN protein is located in the JAHTZZ010000017.1 scaffold. We chose the hit with a low e-value (8.07e-28) and a percentage identity of 89.552%. The predicted protein is located in the negative strand (-), between the nucleotide positions 46848 and 94575. Moreover, the protein contains 18 exons. The alignment obtained from the comparison of the two sequences showed that the protein was conserved in Nanger dama's genome, except for the first part of the protein that was unable to be predicted (we did not predict the first methionine). The human selenoprotein contained two selenocysteines, whereas the predicted protein contains one (the last) selenocysteine and one Glutamic acid (the first one, so it is not conserved). No protein was predicted using the Seblastian, but one secis element (grade A) in the negative strand was correctly predicted in the 3' sequence of the protein.
Taken all together, the protein SelN in Nanger dama contains one selenocysteine and a Secis element. All these signs would suggest that SelN is a selenoprotein.
SelO
SelO is one of the least characterized human selenoproteins. Its function and homologs remain human, nevertheless, human SelO has been found to contain a single Sec residue located in the antepenultimate position at the COOH-terminal end of the protein [9].
For this protein, we analysed different scaffolds and hits (from Homo sapiens) in order to see if we could optimize the protein prediction as the first results were not ideal. However, all the different scaffolds analysed presented bad alignments. We analysed the best hits of the following scaffolds: JAHTZZ010000019.1, JAHTZZ010001290.1, JAHTZZ010024308.1 and JAHTZZ010000007.1.
Here we show an example of the analysis using the scaffold JAHTZZ010000019.1 with Homo sapiens as a reference, as an example of the analysis carried out and showing the results. In this case we obtained a hit with an e-value of 1.49e-30 and a percent identity of 82.105%. The alignment obtained when using T-Coffee was very bad and did not predict any protein. However, Seblastian could predict a selenoprotein, which made us think that there may have been an error in our prediction of the protein. We could also find a SECIS element (grade A) in the reverse strand.
In this case, we could not predict the protein TR2 in Nanger dama.
SelP
SelP is a widely expressed secreted selenoprotein that accounts for nearly 50% of all the selenium in plasma. SelP homologs are mostly present in vertebrates, and the SelP protein family has just recently evolved. SelP is distinguished by his unique feature of having the presence of several Sec residues. Although its mRNA is expressed in many tissues, it is mostly produced in the liver. Two receptors, ApoER2 and megalin, have been implicated in the absorption of SelP in the brain and testis. Studies on the relationship between these receptors and SelP imply that SelP is involved in the transfer of Se to peripheral organs, including the brain and testis [9].
The SelP predicted protein is found in the JAHTZZ010000013.1 scaffold. We used Homo sapiens' SelP annotated protein as a reference query as it seemed it was well annotated and it began with a Methionine (M). Also, when using Bos taurus's SelP annotated protein we did not obtain optimal predictions. The hit presented the lowest e-value, with a value of 9.88e-27, and a high percent identity which was 62.992%. The protein is found between the nucleotide positions 50000 and 54857 on the reverse negative strand (-). Exonerate predicted a total of five exons found in SelP. The alignment obtained when running T-Coffee had a score of 988, and the whole protein was predicted. However, the alignment, mainly in the last part of the protein did not seem optimal. Out of the 10 Sec that the query protein contained, 4 were aligned and conserved and the others were either conserved in a position onwards (which could be due to an alignment error) or not conserved. With Seblastian, two selenoproteins have been identified and two SECIS elements both in the negative strand in the 3' sequence of the protein. One of the SECIS was of grade B (between 49321 and 49255) and the other grade A (between 49755 and 49684).
Given this information, SelP has been conserved in the Nanger dama's genome and conserves some of its Selenocysteine, while others have been lost. Therefore, we hypothesize that SelP is an ortholog selenoprotein found in Nanger dama's genome.
Methionine-R-sulfoxide reductase family
This family of selenoproteins are all involved in reducing methionine methionine (R)-sulfoxide back to methionine. Particularly, SelR1 has a role in regulating actin assembly and promoting filament repolymerization [22]. SelR2, on the other hand, decreases the intracellular reactive oxygen species, resulting in the preservation of mitochondrial integrity [19]. Finally, SelR3 contains in its sequence a signal peptide and a mitochondrial transit peptide [20].
In the phylogenetic tree of the Methionine R-sulfoxide reductase family, we can observe that the predicted protein SelR3 ,predicted in Bos taurus, can be clustered together with its own query, suggesting that the prediction is correct. However, SelR1 and SelR2 predicted proteins aren't classified with their own query.
SelR1
The SelR1 protein is located in the JAHTZZ010000044.1 scaffold. We used Bos taurus' SelR1 annotated protein as a reference query as it seemed it was well annotated and it began with a Methionine (M). We chose this scaffold as it presented the best hits, with the lowest e-value (5.18e-27) and a percent identity of 98.077%. We found out that the analysed protein goes from 48251 to 50594 in the forward positive strand (+). Moreover, the protein contains three exons, with no insertions or deletions in either of them. The alignment obtained from the comparison of the two sequences showed that the SelR1 protein was conserved in Nanger dama's genome (score=1000). The alignment also revealed that the Selenocysteine amino acid was conserved in Nanger dama's genome.
Seblastian predicted one selenoprotein and one SECIS element (grade A) in the positive strand in the protein's 3' sequence.The evidence presented indicates that SelR1 from Nanger dama is conserved and presents both a Selenocysteine and a SECIS element which suggests that it is an orthologous selenoprotein.
SelR2
The SelR2 protein in Nanger dama is found in the JAHTZZ010000007.1 scaffold. We used the Homo sapiens' SelR2 annotation as the one from Bos taurus did not seem to be well annotated and its sequence did not start with a Methionine (M). We analysed the scaffold mentioned as it presented the hit with the lowest e-value (2.24e-20) and highest percent identity (82.759). We uncovered that the protein goes from 27981 to 51281, and is located on the forward positive strand (+). Moreover, this protein was predicted to contain five exons, with no insertions or deletions. The alignment obtained when running T-Coffee presented a score of 1000 between the Bos taurus protein and the predicted protein, and it seemed like it had been conserved to some extent. The alignment showed that most of the Cysteines were conserved in Nanger dama's predicted protein. Seblastian did not predict any selenoprotein but does contain a Secis element in the reverse strand (in the other strand) between the position 87268 and 87198. So, based on the criteria we have established we will discard this SECIS element.
These results indicate that SelR2 may be a Cysteine-containing homolog, which has been conserved during evolutionary events.
SelR3
The SelR3 protein in Nanger dama is located in the JAHTZZ010000019.1 scaffold. The query used was Bos taurus' protein as it was well annotated and started with a Methionine (M). We analysed the JAHTZZ010000019.1 scaffold as it presented the hit with the lowest e-value (9.68e-15) and highest percent identity (100%). We uncovered that the protein goes from 46426 to 171047 and is located on the forward positive strand (+). Moreover, the protein contains six different exons predicted by exonerate. The alignment obtained when running T-Coffee (score= 991) did not seem robust as it had as the first part of the protein was not very conserved (not well aligned probably) while there was a part in the middle which was very conserved and preserved the cysteines. Seblastian did not find neither a protein in the analysed sequence nor a SECIS element. These results indicate that SelR3 may be a Cysteine-containing homolog, as it has preserved the cysteines.
SelS
They have a single transmembrane domain in the NH2-terminal sequence, a glycine-rich section, and Sec residues in a specific place in the COOH-terminal end of the proteins. Additionally, it presents a second coiled-coil domain in the cytosolic part of the protein. It is known they contain functional ER stress response elements and that situations that promote the accumulation of misfolded proteins in the ER up-regulate their production. For that, SelS has been thought to have a role in the degradation of misfolded endoplasmic reticulum luminal proteins [9,21]. The SelS protein in Nanger dama is found in the JAHTZZ010000001.1 scaffold. The query was used from the Bos taurus' selenoproteome annotation as it seemed to be well annotated. We analysed the scaffold mentioned as it presented the hit with the lowest e-value (6.39e-22) and highest percent identity (93.878). We uncovered that the protein goes from 49349 to 57322, and is located on the forward positive strand (+). Moreover, this protein was predicted to contain six different exons, with no insertions or deletions. The alignment obtained when running T-Coffee was almost perfectly aligned (except for one residue which presented a mutation) with a score of 1000. This suggested that the protein had been conserved in Nanger dama's genome. Importantly, the Selenocysteine amino acid was conserved in the alignment. Seblastian predicted one selenoprotein and one SECIS element (grade A) in the positive strand in the protein's 3' sequence. Our results suggest that SelS from Nanger dama is a conserved Selenocysteine protein, which conserves the SECIS element, and is therefore a SelS orthologous protein.
SelU family
In the phylogenetic tree of the SelU family we can see that all of them (SelU1, SelU2 and SelU3) aren't classified with their own query.
SelU1
SelU1 is a protein found in the scaffold JAHTZZ010000010.1 (it was chosen the hit with the lowest e-value: 6.84e-133). The protein is found between the nucleotide positions 50000 and 50689 on the forward strand. Only one exon was predicted for this protein. When running T-Coffee, a score of 1000 was obtained and a perfect alignment was visualized. However, our protein does not begin with a methionine, as a result of using Bos taurus as our query. It was discovered that both the cow protein SelU1 and the predicted protein in Nanger dama lack Selenocysteine and instead contain a cysteine. Although no protein was predicted using Seblastian, one SECIS element (grade B) in the negative strand was correctly predicted in the protein's 3'. So, based on the criteria we have established, we will discard this SECIS element. Taken as a whole, protein SelU1 in Nanger dama contains cysteine and a Secis element. All of these indicators point to SelU1 being a cysteine-containing homologous protein.
SelU2
SelU2 is a protein found in the scaffold JAHTZZ010000001.1. It was chosen the hit with a low e-value (7.08e-21) and high identity (100%). The protein is found between the nucleotide positions 39189 and 57652 on the reverse strand (-). Six exons were predicted in this protein. When the T-Coffee was run, a nearly perfect alignment was observed. However, our predicted protein did not begin with a methionine because of using Bos taurus as a query. It was discovered that both the cow protein SelU2 and the predicted protein in Nanger dama lacked a selenocysteine and instead contained conserved cysteines. There was no protein predicted using Seblastian, and no SECIS element was found in the predicted protein. All of these indicators suggest SelU2 is a cysteine-containing homologous (orthologous) protein, as it contains conserved cysteines and the sequence of the protein has been conserved.
SelU3
SelU3 is a protein found in the scaffold JAHTZZ010000012.1. It was chosen a hit with a low e-value (8,24e-37) and high identity (97.101%). The protein is found between the nucleotide positions 49741 and 52647 on the forward strand (+). Seven exons were predicted in this protein. When the T-Coffee was run, a nearly perfect alignment was observed. Furthermore, it was discovered that both the cow protein SelU2 and the predicted protein in Nanger dama lack Selenocysteine and instead contain a cysteine. There was no protein predicted using Seblastian, and 2 SECIS elements were found in the predicted protein. Both of them were SECIS elements of grade B located in the positive strand. However, one of them was found in the protein's 3' sequence and the other one in the 5'. All of these indicators suggest SelU3 is a cysteine-containing homologous protein.
Thioredoxine Reductase family
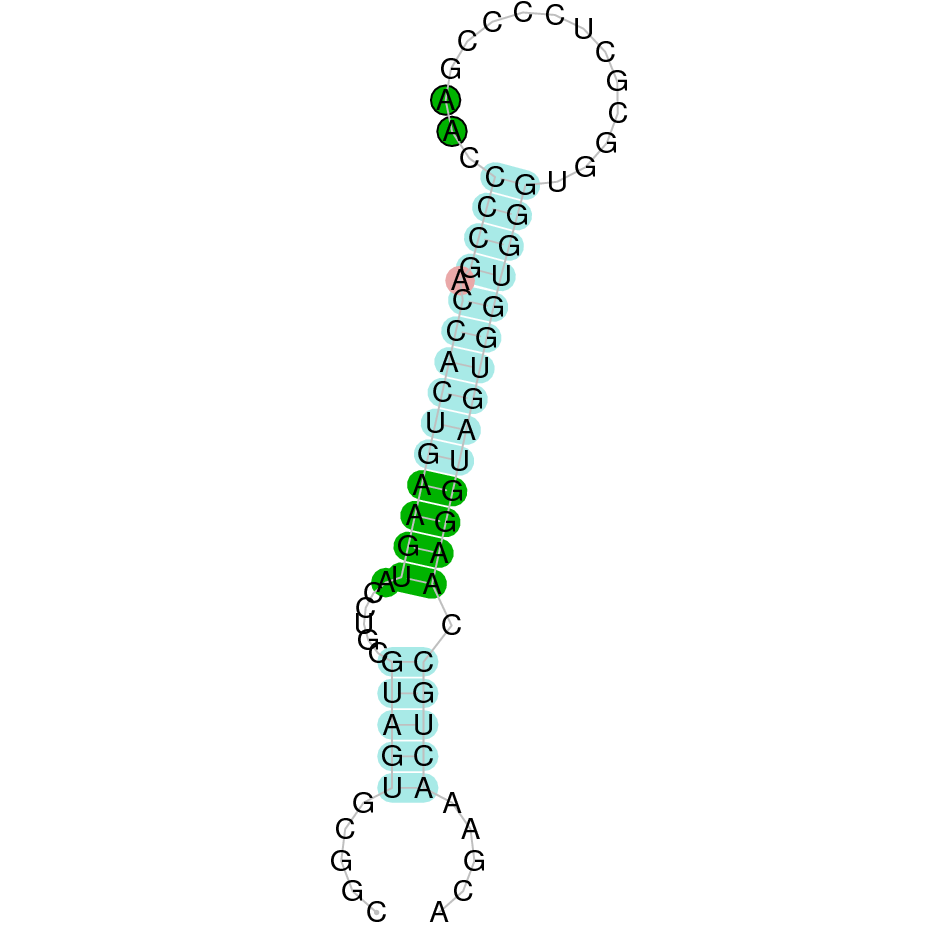
TR1
For this protein, we analysed different scaffolds and hits (from Homo sapiens) in order to see if we could optimize the protein prediction as the first results were not ideal. However, all the different scaffolds analysed presented bad alignments.
Finally, we decided to analyse the JAHTZZ010000019.1 scaffold taking the total length of the hits. This scaffold presented a good identity and a good e-value (the first hit had an identity of 94.521 and an e-value of 4.22e-34). The protein, which contains 19 exons, is found between the nucleotides 44672 and 120862 in the reverse strand (-). Finally, the T-Coffee showed a good alignment, except for the first part of the protein, which contained a lot of gaps. Nevertheless, we could find a selenocysteine which was conserved in both Homo sapiens and Nanger dama. Regarding Seblastian, it could predict a protein and found one secis grade A, also in the reverse strand.
Therefore, our results point out that the TR1 protein is conserved in Nanger dama along with the selenocysteine amino acids, and the SECIS element, which suggest that TR1 is a selenoprotein orthologous to the Homo sapiens' TR1.
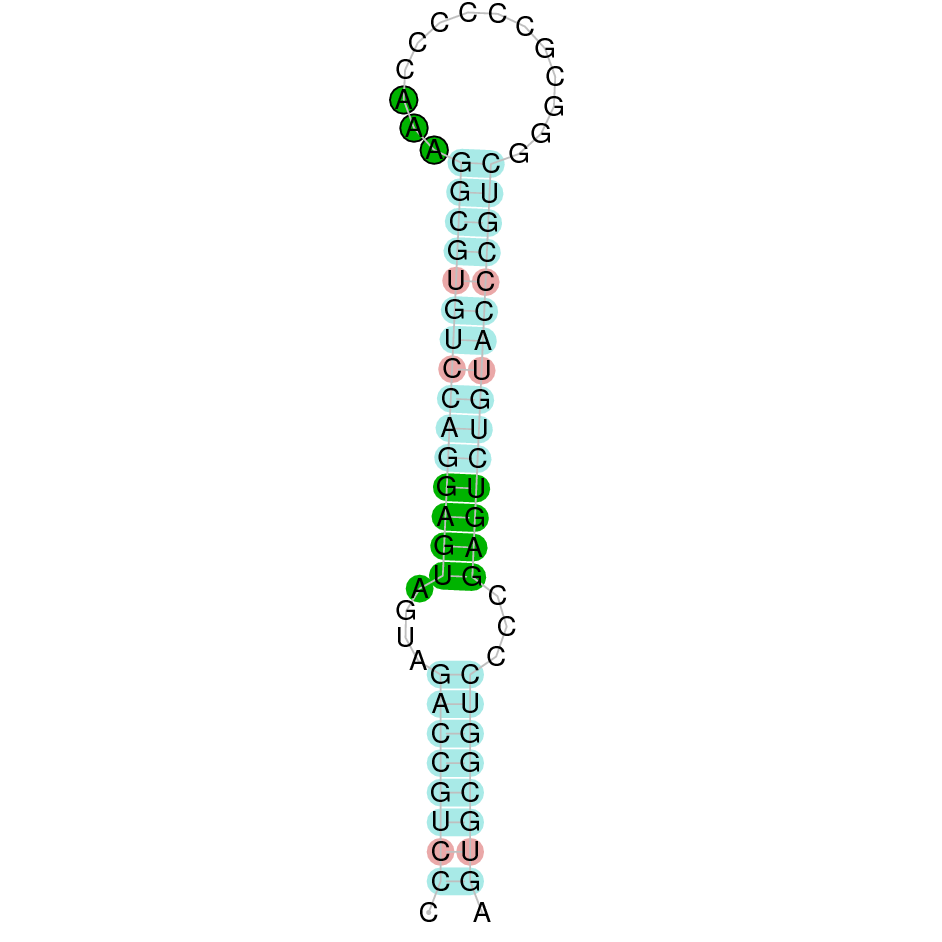
TR2
For this protein, we analysed different scaffolds and hits (from both Bos taurus and Homo sapiens) in order to see if we could optimize the protein prediction as the first results were not ideal. However, all the different scaffolds analysed presented bad alignments. When using Bos taurus as a reference, we analysed the JAHTZZ010003226.1 scaffold but with the alignment we did not obtain a good protein prediction. Therefore, we analysed various hits from different Homo sapiens scaffolds (JAHTZZ010003226.1, JAHTZZ010000007.1, JAHTZZ010000017.1, JAHTZZ010009059.1 and JAHTZZ010033675.1) but we encountered the same problem as when using the cow as the reference organism.
Here we show the analysis with the JAHTZZ010000007.1 scaffold using Homo sapiens as a reference, as an example of the analysis carried out and showing the results. In this case we obtained different hits, all present in the forward positive strand (+). The alignment obtained when using T-Coffee was very bad and did not predict any protein (score=731). Seblastian predicted one selenoprotein and a SECIS element (grade A) in the positive strand in the protein's 3' sequence between the position 60264 and 60332, which makes us think that there was an error in the prediction process.
In this case, the protein TR2 could not be predicted in Nanger dama.
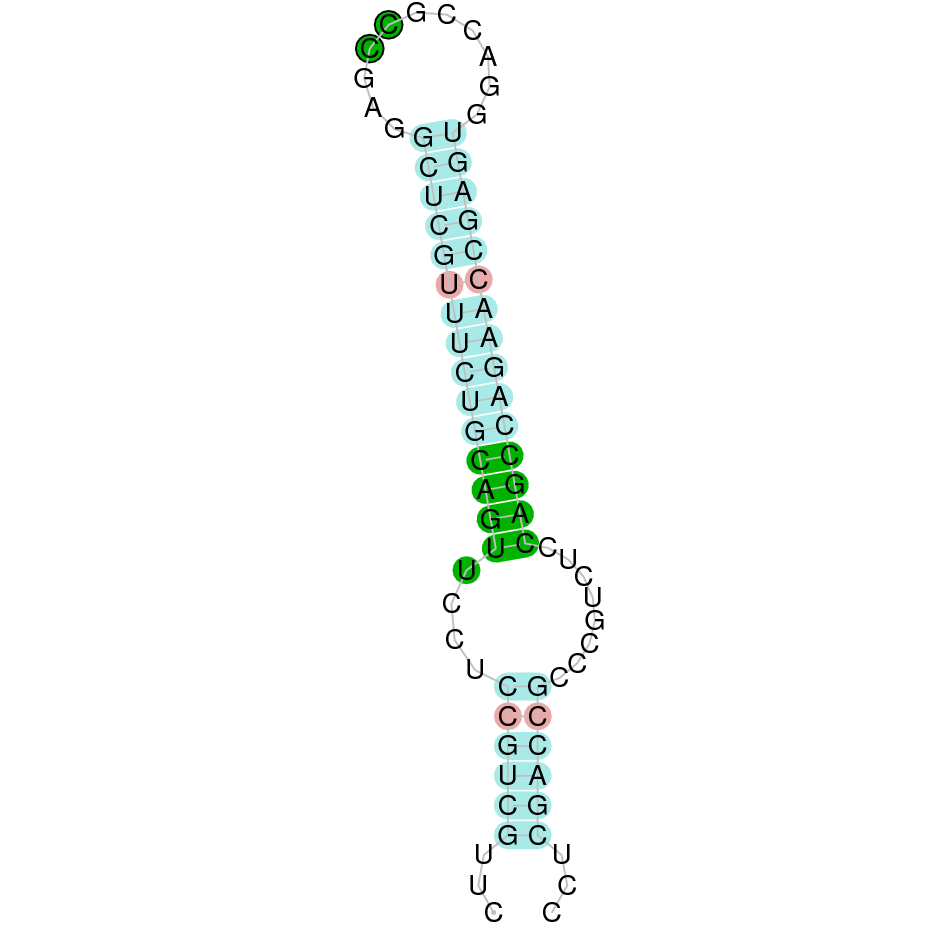
TR3
TR3 is a protein found in the scaffold JAHTZZ010000006.1. In this case we used Bos taurus as the reference annotation, as it was well-annotated. It was chosen a hit with a low e-value (2.55e-38) and high identity (81.373%). The protein is found between the nucleotide positions 39990 and 65616 on the positive strand (+). Fourteen exons were predicted in this protein. When T-Coffee was run, a nearly perfect alignment was observed. Furthermore, it was discovered that both the cow protein SelU2 and the predicted protein in Nanger dama presents a selenocysteine that is conserved.
Seblastian predicted one selenoprotein and one SECIS element (grade B) in the positive strand in the protein's 3' sequence. All of these indicators suggest TR3 is a selenoprotein.Selenophosphate synthetase family
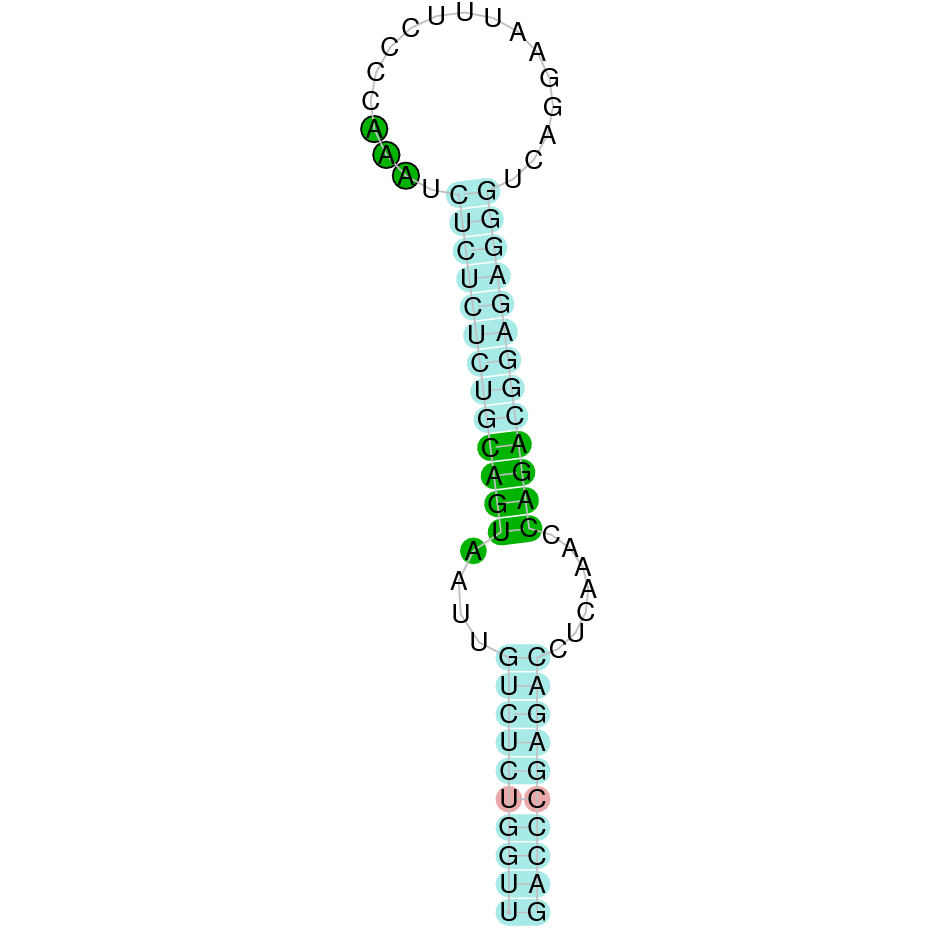
The function of the selenophosphate synthetase family in mammals is the same as that of the E. coli protein SelD. SPS1 and SPS2 are both selenophosphate synthetases, however only SPS2 can generate selenocysteines in vitro. SPS2 is thought to produce new selenocysteines, whereas SPS1 is thought to recycle selenocysteines [9].
SPS1
The SPS1 protein is found in the JAHTZZ010000015.1 scaffold. For this protein we used Homo sapiens' protein annotation as a query, as it was well-annotated and started the sequence with a Methionine (M). We analysed the mentioned scaffold as it presented two hits with very low e-values (5.67e-111 and 3.52e-27) and with high percent identity (62.544 and 86.885%). The protein is found between the nucleotide positions 50000 and 51199, on the reverse negative strand (-). Exonerate predicted a total of three exons found in the protein. The alignment obtained when running T-Coffee had a score of 994, and the whole protein was predicted. The obtained alignment was good and no selenocysteine was found. However, we observed some conserved cysteine residues. Seblastian predicted one selenoprotein and one SECIS element (grade A) in the negative strand in the protein's 3' sequence.
Therefore, we concluded that SPS1 is a machinery protein involved in selenocysteine synthesis.
SPS2
For this protein, different scaffolds were analysed in order to search for duplication events. The SPS2 Homo sapiens protein annotation was used as a query as it was well-annotated and started with a Methionine (M). The SPS2 protein is found in the JAHTZZ010000015.1 scaffold. We used Homo sapiens' protein as the reference query as it was well-annotated and started with a Methionine (M). The scaffold was analysed as it presented the best e-value, which was of 0.0 meaning that the hit was certain and a percent identity of 90.414. The protein is found from position 50000 to 51460 in the reverse negative strand (-) and contains one long exon. When running T-Coffee, the alignment obtained had a score of 996 and the protein seemed to be well-aligned and mainly conserved with some minor mutations. Importantly, the two Selenocysteines were conserved in Nanger dama's genome. Seblastian predicted one selenoprotein and one SECIS element (grade A) in the reverse strand in the protein's 3' sequence.
Therefore, our results point out that the SPS2 protein is conserved in Nanger dama along with the Selenocysteine amino acids which suggest that SPS2 is a selenoprotein orthologous to the Homo sapiens' SPS2.
PSTK
Specifically, phosphorylates seryl-tRNA(Sec) to O-phosphoseryl-tRNA(Sec), an activated intermediate for selenocysteine biosynthesis [12].
PSTK is a protein found in the scaffold JAHTZZ010000003.1. For this protein, we used the Bos taurus annotation as reference as it seemed well-annotated and started with a Methionine (M). The scaffold was analysed because it had the best hits with the lowest e-values and highest percent identity. The protein is found between the nucleotide positions 40191 and 52807 on the reverse negative strand (-). Six exons were predicted to be in the PSTK protein by Exonerate. When running T-Coffee, a score of 1000 was obtained and there was an almost perfect alignment of the protein, with just some changes which can be seen as selective pressure mutations. All the cysteines were aligned and conserved. Seblastian did not predict neither a protein nor a SECIS element.
Therefore, our results point out that the PSTK protein is conserved in Nanger dama along with the cysteine amino acids which suggest that it has been conserved as a machinery protein involved in the selenoproteome.
SBP2
In mammals, SECIS-Binding protein 2 is known to interact with the SECIS element, the ribosome and the eEFSec. It catalyzes the synthesis of the active Se donor selenophosphate that is necessary for Sec biosynthesis. Also, mutations in SBP2 are associated with abnormal thyroid function [9].
For the SBP2 protein, we analysed the two scaffolds (JAHTZZ010000001.1, JAHTZZ010000014.1) that presented hits using both Bos taurus and Homo sapiens as a reference. Both proteins seemed to be well-annotated and they started with a Methionine (M). Nevertheless, and even though we tried different approaches, none of the alignments obtained were good or conserved and there were parts of the protein which were not predicted right. Therefore, we show here one example of a scaffold analysed. We analysed the JAHTZZ010000001.1 scaffold using Bos taurus as the reference annotation. The hit was located on the reverse negative strand (-). Exonerate predicted forty-five exons in the protein. The alignment obtained with T-Coffee was very bad (score=676), with only a few regions aligning. Furthermore, Seblastian did not predict a selenoprotein nor a SECIS element.
In this case, the results obtained suggest that there was either an error with the prediction of the protein and with exonerate, or that the machinery protein SBP2 is not conserved in Nanger dama's genomes. The protein SBP2 could not be predicted in Nanger dama's genome.
SECp43
SECp43 or tRNA Sec1 associated protein 1 has a direct role in selenoprotein synthesis regulation through its involvement in methylation of tRNA[Ser]Sec . In zebrafish, Secp43 is not a selenoprotein, it is a cysteine homologue [23].
The SECp43 protein is found in the scaffold JAHTZZ010000017.1. For this protein, we used the Bos taurus annotation as reference as it seemed well-annotated, even though it did not start with a Methionine (M). The scaffold was analysed because it had the best hits with the lowest e-values (9.60e-20) and highest percent identity (100.000). The protein is found between the nucleotide positions 36648 and 59512 on the reverse negative strand (-). Eight exons were predicted to be in the SECp43 protein by Exonerate. When running T-Coffee, a score of 1000 was obtained and the query and our protein aligned perfectly, with just one amino acid change. The protein is therefore conserved and the five cysteines present were also conserved in Nanger dama's SECp43 protein. Seblastian did not predict neither a protein nor a SECIS element.
Therefore, our results point out that the SECp43 protein is conserved in Nanger dama along with the cysteine amino acids which suggest that it still serves as a machinery protein (encoded by its machinery gene).
SecS
The SecS protein is found in the JAHTZZ010000015.1 scaffold. For this protein we used Bos taurus' protein. We analysed the mentioned scaffold as it presented hits with very low e-values (2.21e-55) and with high percent identity (97.000%). The protein is found between the nucleotide positions 15944 and 50299, on the forward positive strand (+). Exonerate predicted a total of eleven exons found in the protein. The alignment obtained when running T-Coffee had a score of 1000, and the whole protein was predicted. The obtained alignment was good and no selenocysteine was found. However, we observed some conserved cysteine residues. Seblastian could not predict a selenoprotein and one SECIS element (grade B) in the positive strand of the protein's 3' sequence.
Therefore, the results obtained suggest that SecS is a machinery protein which plays an important role in the selenoproteome.
The goal of this article was to contribute to the genome annotation of Nanger dama by annotating the Selenoproteins found in the genome. Homo sapiens and Bos taurus Selenoproteins orthologous were searched in the Nanger dama genome to achieve our purpose. The human genome was chosen as the reference genome since it is one of the most well-annotated genomes, and Bos taurus was also chosen in some cases as it represents the most closely related one.
To accomplish this, a program was created. This program took either a human selenoprotein or a cow selenoprotein (the query), depending on what we selected, and checked for homology on the Nanger dama genome. This program showed us the different hits found and, as a result, various protein prediction alternatives. We had to introduce manually the chosen hit and after that the software ran the program T-Coffee. T-Coffee aligned the predicted protein with the query and displayed the alignment as well as its score. All this information is essential to determine whether the Nanger dama genome contains an homologous gene of the given human or cow selenoproteins. Moreover, it is essential to determine whether the selenoprotein is conserved or has been lost. Seblastian, which is a Selenoprotein Prediction Server, was also utilized to determine whether the predicted proteins included secis elements. This tool also examined if the given sequence had any selenoproteins that matched.
The following characterisation is based on a total of 40 selenoproteins examined:
Some peculiarities were discovered among these proteins:
GPx3 was predicted to be duplicated in the following scaffolds JAHTZZ010000006.1, JAHTZZ010000327.1. As a result, it was determined that Nanger dama's genome possessed a duplication.
Limitations and possible improvements
In our project there are also some limitations. It should be noted that in different cases the starting methionine codon was not correctly predicted at the start of each protein. This is for various reasons. First of all, it was assumed that the protein present in Nanger dama begins at the same location as the human or cow protein using a homology-based method. Not only this, but also in some cases the protein in Bos taurus did not start with a methionine, as it was not well annotated. Secondly, we should take into account that the existence of misanotations also in the Nanger dama's genome may also explain the finding of another amino acid where methionine was intended to be.
Another consideration of our project is that we only used exonerate to predict the exons of each protein. Exonerate is a program that searches for all exons in a sequence (from fastasubseq). As a result, in cases where the provided sequence is longer than the protein we are seeking for, we will find exons that are not from the protein. It should be noted that in our case, Exonerate was used to predict the gene and align it with the sequence of the selenoprotein that encodes, and also recognize and identify the exons. An alternative approach could have been using Genewise, which not only gives us the alignment but also the predicted protein and nucleotide sequence.
Regarding the automatization, we are aware that our program is not completely automated due to a lack of time (as we had to write the selenoprotein every time we wanted to analyse one of them). However, having this level of automation also allowed us to manually select the hit which we deemed optimal. Had we had more time, we would have tried to create a loop, in which the program would have run for every protein. The loop would go through vector elements in which we would have saved each selenoprotein. The loop would be performed as many times as the vector's position, implying each selenoprotein would be evaluated.
Moreover, not all of the hits returned by tblastn for all the selenoproteins examined were assessed. We only did it in those cases for which we encountered similar hits or really good e-values and identities. However, because of this, certain duplications (paralogous genes) may have been overlooked. Therefore, another element we could have implemented in our automatization program, is to evaluate each scaffold and each hit automatically, obtaining a thorough analysis of all the possible duplications in the genome. However, as in our case Nanger dama is a mammal, and mammals do not present as many duplications as fish, we considered it appropriate to analyse the orthologous proteins only and not those paralogous.
Finally, the presence of SECIS elements in the predicted proteins was checked using the tool Seblastian. Seblastian also scans the sequence for known selenoproteins, however only 21 of the 40 proteins are anticipated to be selenoproteins. As a result, the findings of this study imply that using a homology-approach to define selenoproteins is the best strategy.
Do not hesitate to contact us, we will be delighted to answer all of your questions! :)
| Ona Piqué | Clara Sala | Carla Brujas | Carla del Río |
 |
 |
 |
 |
| ona.pique.01@estudiant.upf.edu | clara.sala.01@estudiant.upf.edu | carla.brujas.01@estudiant.upf.edu | carla.delrio.01@estudiant.upf.edu |