
Abstract
21st amino acid selenocysteine (Sec) is the essential element of selenoproteins, a group of proteins that are found in all domains of life and play a key role in antioxidant reactions. However, its study is difficuted by the fact that Sec is encoded by UGA, a terminal codon. In order to distinguish between stop codons and Sec insertion codons, a specific translational machinery recognizes a stem-loop structure known as SECIS element at the mRNA 3'UTR region of these proteins.
The aim of this project was to characterize the selenoproteome of Pseudonaja textilis, one of the most venomous snakes in the world. By using an homology-based approach, the animal genome was compared to one of the best studied selenoproteome species, Homo sapiens. In particular, forty-one selenoproteins, including the required machinery proteins and Cys-homologues, were searched for carefully through the reptile genome and further analyzed with bioinformatic tools. Also, SECIS elements predictions were used to discuss the presence of selenoproteins in P.textilis.
In total, twenty Sec-containing selenoproteins were found in P.textilis’ genome, two of them being duplicated (SelT and SelU1). In addition, another duplication was observed in the Cys-containing homologue protein MrsA. Nevertheless, four selenoproteins were missing: GPx5, GPx6, SelU3 and SelV. Taken together, this analysis represents a first insight into the selenoproteome of this vertebrate.
Introduction
Selenium's role
Selenium is one of the nine essential elements in the animal kingdom. It plays a biological role in the synthesis of selenoproteins, being the main ingredient of the 21st amino acid selenocysteine (Sec, U). Selenium provides selenocysteine with both lower reduction potential and pKa than its analogue residue cysteine (Cys), which makes this particular amino acid more convenient to bring in for proteins involved in antioxidant reactions[1]. Hence, selenoprotein families are composed of proteins (often enzymes) involved in oxidoreductions, redox signaling, antioxidant defense and immune responses, amongst others[2].
Selenoprotein biosynthesis in eukaryotes
Selenocysteine (Sec) is not coded in the genetic code; instead, it is cotranslationally incorporated into selenoproteins. To do so, Sec synthesis involves the decoding of an UGA codon (which acts as a termination codon otherwise). To design the UGA codon as a Sec codon instead of a stop signal, specific Sec designation signals must enter into action. This also requires activation of the “Sec machinery”, a set of proteins that are in specific charge of selenoprotein synthesis (Fig 1)[3].
The main Sec designation signal is the SECIS element (Sec insertion sequence), a stem-loop structure sequence located in the 3’-untranslated region of every selenoprotein mRNA. This mRNA loop is recognized by the SECIS element binding protein 2 (SBP2). SBP2 binds the SECIS element and it also recruits and binds the eEFSec, an elongation factor for selenocystein tRNA. This links the tRNA to the SECIS element, allowing it to recognize the UGA codon and add selenocysteine to the amino acid chain[4,5].
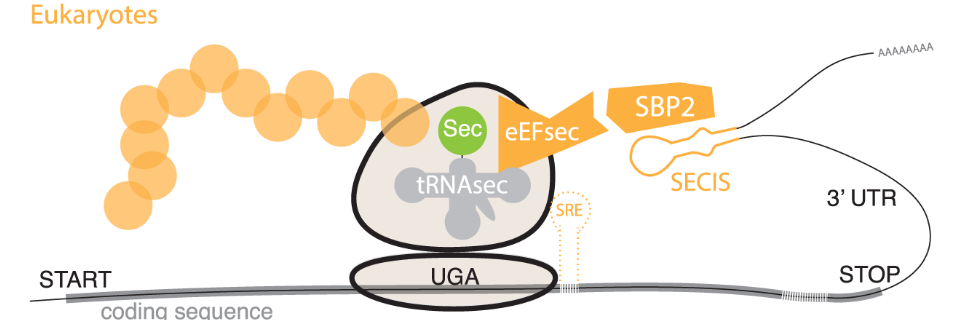
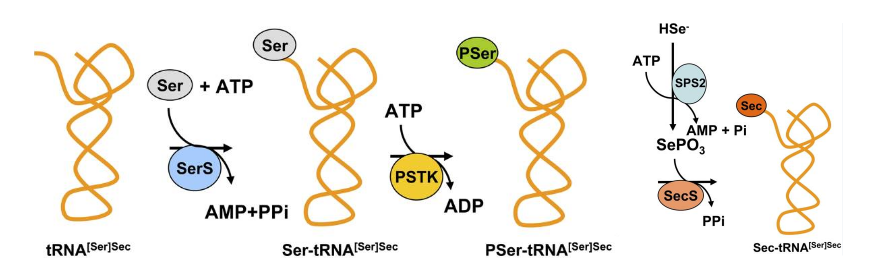
Furthermore, it is also important to highlight that unlike other amino acids, selenocysteine is synthesized on its own tRNA, which is known as Sec-tRNA[Ser]Sec and suffers a set of worth mentioning modifications before bringing selenium in (Fig 2).
This tRNA is initially aminoacylated with serine thanks to Seryl-tRNA synthetase (SerS). Then, it is phosphorylated to form O-phosphoseryl-tRNA[Ser]Sec by the action of O-phosphoseryl-tRNA[Ser]Sec kinase (PTSK). Lastly, Sec synthase (SecS) converts the tRNA into selenocysteyl-tRNA[Ser]Sec (Sec-tRNA[Ser]Sec), due to its ability to dephosphorylate the tRNA to further transfer a monoselenophosphate onto it.
Monoselenophosphate is hence an active selenium donor. The selenoprotein SPS2 (Selenophosphate Synthetase 2) is needed to generate monoselenophosphate from selenide and ATP. Interestingly, SPS2 is a selenoprotein itself, and thereby may also autoregulate its own production[4,5].
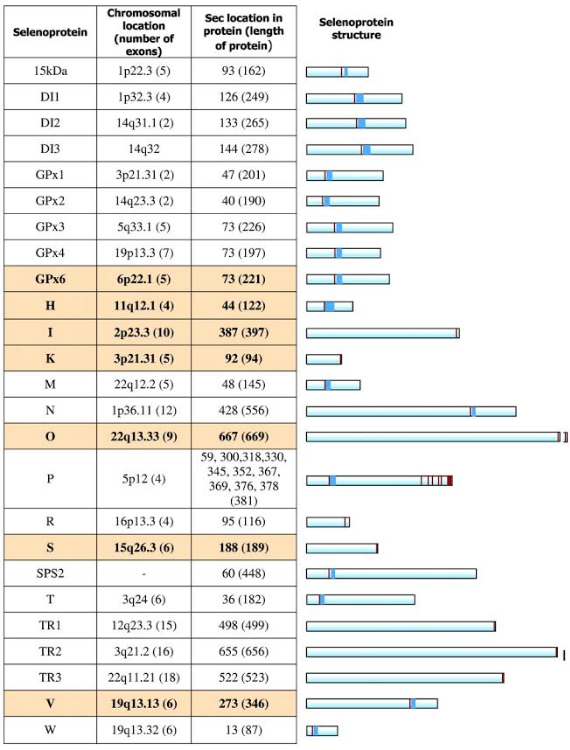
Human selenoproteome
The human selenoproteome consists of 25 known selenoprotein genes, with diverse patterns of distribution (from ubiquitous to tissue-specific) and subcellular localization (from exclusively certain organelles to plasma). These and other properties are essential information regarding the physiological roles for selenoproteins. A crucial step in understanding the effects of dietary Se on human health is determining the functions of these proteins. Many of them are broadly classified as antioxidant enzymes; however, it is becoming clear that their exact functions are quite diverse. In fact, deficiency of dietary Se status may affect aspects of human health such as immune responses, neurodegeneration, cardiovascular disease, and cancer[6].
Selenoproteins along evolution
Selenoproteins have been identified in all domains of life[8]. In eukaryotes, the size of selenoproteome varies significantly; some organisms such as vertebrates or plants have dozens of these proteins, while others such as higher plants or fungi have lost all of them [9].
Recent studies show that aquatic organisms possess the highest content of selenoproteins, whether they are animals (e.g., fish) or plants (e.g., algae), whereas terrestrial organisms show a trend towards reduced use of them [10]. It is hypothesized that the change to terrestrial habitats greatly diminished the availability of Se, and that selenoproteins were then more susceptible to oxidative damage[11]. As a result, many terrestrial organisms might have lost selenoproteins or replaced them with cysteine-containing homologues, which are generally far less effective in catalysis[9].
Together with some selenoprotein gene duplications, gene losses and replacement of Sec with Cys, a predicted ancestral vertebrate selenoproteome has been defined by 28 proteins[8].

About Pseudonaja textilis
The eastern brown snake (Pseudonaja textilis), native to Australasia, is the world’s second-most venomous land snake, and can reach a size of 2 m (6,6 ft) long. Its main prey is the introduced house mouse, although it bases its diet in other vertebrates too, especially small mammals. This oviparous species is variable in colour: generally adult’s upperparts range from pale to dark brown, and its underparts are pale cream-yellow, usually with orange, brown or dark grey blotches. However, juveniles can vary in markings, showing a uniform brown or having many black bands or a reticulated pattern. The darker markings fade with age. It has a diploid pattern of 38 chromosomes, which is unique within the genus Pseudonaja.
For further information about this reptile and references, visit our Viquipèdia entry (only available in Catalan)
Methods
The aim of this project was to find, identify and annotate all the Pseudonaja textilis selenoproteins, which have never been annotated before. By using an homology-based approach, we compared the Pseudonaja textilis genome with the Homo sapiens selenoproteome, since it is the closest related species whose selenoproteins are well annotated in the SelenoDB database.
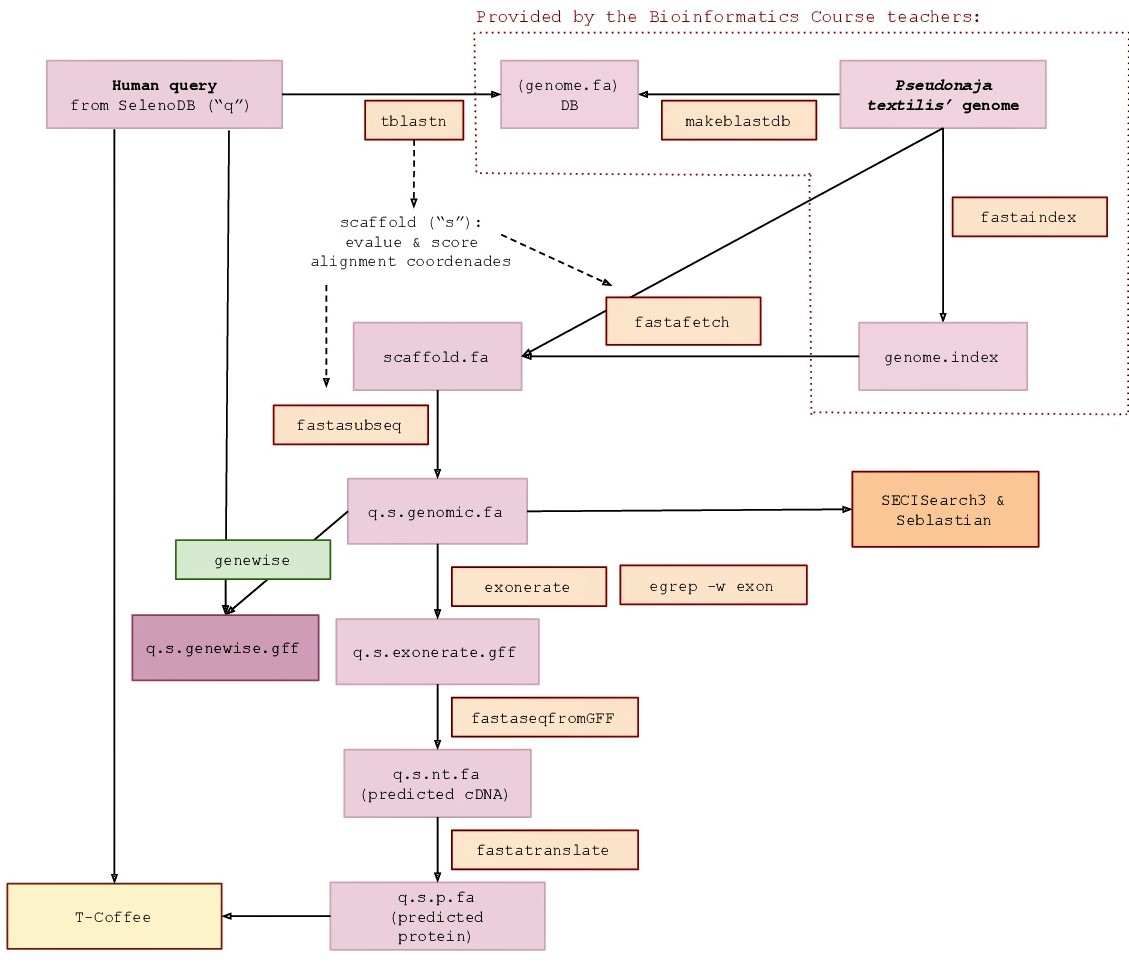
Queries acquisition
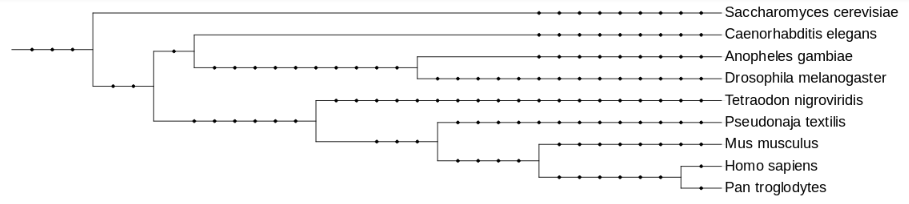
The protein queries needed to predict all the selenoproteins in Pseudonaja textilis' genome were extracted from Homo sapiens’ genome. The election of this species was for two reasons. First, because amongst the species from SelenoDB 1.0 (www1.selenodb.org), Homo sapiens, Pan troglodytes and Mus musculus are the ones with a highest evolutionary proximity to the species of this study, as it is shown in the phylogenetic tree (Fig 6). Second, because Homo sapiens is the best annotated species among the ones mentioned before.
Genome obtention
The Pseudonaja textilis genome was obtained from the following source:
/NFS_UPF/bioinfo/BI/genomes/2018/Pseudonaja_textilis/genome.fa
Manual annotation of selenoproteins
This procedure was followed by working with each of the human queries at the time by using the selected software. To do so, all the needed programs were exported through the commands:
export PATH=/mnt/NFS_UPF/bioinfo/BI/bin:$PATH
export PATH=/mnt/NFS_UPF/bioinfo/BI/soft/genewise/x86_64/bin:$PATH
export WISECONFIGDIR=/mnt/NFS_UPF/bioinfo/BI/soft/genewise/x86_64/wise2.2.0/wisecfg/
- Tblastn -
In order to locate the Pseudonaja textilis genomic region in which a given selenoprotein can potentially be found, the BLAST package tBLASTn (Basic Local Alignment Search Tool) was used. This program compares protein queries against translated nucleotide databases. To execute it, we used the following command:
tblastn -query selenoprotein.aa.fa -db /mnt/NFS_UPF/bioinfo/BI/genomes/2018/Pseudonaja_textilis/genome.fa -out alignment.blast
The output was a fasta file containing a sorted list of hits obtained from such comparison, each complemented with other important parameters such as the scaffold identification, the score and identity values, the length of the aligned sequences and the e-value. This information was used to determine whether a particular hit had enough statistic significance to be further analysed.
Special attention was paid to both the score and the e-value; the first one rates the alignment (the higher the better, preferably shouldn’t be lower than 100), the second one shows the probability that the query was found by chance in the nucleotidic sequence (the lower, the more significant the hit; the e-value cutoff was set at 0.01). It was also relevant to check for a high percentage of identity between both sequences. Once a hit was considered as significant, information regarding its position -start and end positions in the scaffold, and direction of the chain (direct or reverse)- was collected and taken into account in the further steps.
- Fasta fetch -
To extract the genomic region (scaffold) containing the significant hits we executed the fastafetch command. This necessarily runs by using an indexed genome, which we were provided with. The output file was a fasta file corresponding to each scaffold that contained a significant hit/s. The command executed was:
fastafetch /mnt/NFS_UPF/bioinfo/BI/genomes/2018/Pseudonaja_textilis/genome.fa
/mnt/NFS_UPF/bioinfo/BI/genomes/2018/Pseudonaja_textilis/genome.index “scaffold” > scaffold.fa
- Fasta subseq -
To further extract a more delimited region where the hits were located, we used the fasta subseq command. This requires the determination of the start position and length of the aligned sequence, which was calculated from the tblastn output (taking the lowest start position of the significant hits in the genomic sequence as the start position). To ensure that the sequence contained the complete gene, elongation of 50000 nucleotides 5’ upstream and 3’ downstream was implemented in the estimate. The output file was a fasta file containing just the genomic region aligned with the query and thus where the selenoprotein could be predicted. To do so, we run the following command:
fastasubseq scaffold.fa start length > selenoproteingenomic.fa
- Exonerate -
To predict the selenoprotein in the genomic sequence saved in the fasta subseq output, exonerate was used. What is more, only the exonic sequence (cDNA) was extracted in the output file by using the egrep command:
exonerate -m p2g --showtargetgff -q selenoprotein.aa.fa -t selenoproteingenomic.fa | egrep -w exon > selenoproteingenomic.exonerate.gff
- Genewise -
Genewise is another gene prediction software. It was also run to complement Exonerate outputs, thus generating new gene predictions with the aim to obtain the most informative results. The command used to run it was:
genewise -pep -pretty -cdna -gff selenoprotein.aa.fa selenoproteingenomic.fa > genewise_selenoproteingenomic.fa
- Fastaseq from GFF -
The fastaseq fromgff program was required to convert the exonerate output from a gff into a pl file. The command used was:
fastaseqfromGFF.pl selenoproteingenomic.fa selenoproteingenomic.exonerate.gff > predictedselenoprotein.nt.fa
- Fasta translate -
For the purpose of predicting the Pseudonaja textilis selenoprotein sequence, we executed the fasta translate command, which translates the cDNA sequence obtained in the fastaseq fromgff output into an aminoacid sequence. The command executed was:
fastatranslate -f predictedselenoprotein.nt.fa -F 1 > predictedselenoprotein.aa.fa
- T-Coffee -
Lastly, T-Coffee was used to compare the Pseudonaja textilis predicted selenoprotein sequence with the query initially used as a reference. The output file registered a global alignment of both sequences, together with additional information regarding inference of homology between them. We used the following command:
t_coffee selenoprotein.aa.fa predictedselenoprotein.aa.fa > t_coffeeselenoprotein.fa
- SECIS element prediction -
To confirm that the predicted sequence corresponded, indeed, to a selenoprotein, it was essential to identify SECIS elements in each genomic region. This was achieved by using the online tool Seblastian, which allows to find SECIS elements in a given sequence. Not only that, but it also performs a blastx analysis based on the upstream sequence of the found SECIS element against a selenoproteins database, so as to provide the corresponding selenoprotein.
Automation
A semiautomatic program was created to analyse and align the sequences of selenoproteins from the Pseudonaja textilis genome with the ones in the human genome (queries). Perl programming language was used. The result was a program able to run automatically all the steps explained previously in this section, except from the ones that required online tools. It also included several checkpoints and some clearly explicitated sections where the person who uses the program must specify certain data: the query to analyse, the scaffold chosen according to tblastn results, the length of the scaffold and the sense of the strain where the gene is located. Furthermore, this program provided the file ready to use in SECISearch3 and Seblastian, which included only the recognized characters A, T, C, G and N. This program enabled a faster and clearer way to analyse each selenoprotein query. The program can be downloaded clicking here.
Phylogeny.fr
In order to create a phylogenetic tree to analyse the similarities between the amino acid sequences obtained from a certain proteins’ family and their orthologous sequences in the human genome, our reference, data was introduced in the online tool phylogeny.fr. Its results allowed to better interpret the results of this study.
Results
In order to offer a complete and clear explanation of the results obtained during the analysis of Pseudonaja textilis' selenoproteome, a tabulated display of the results has been attached at the beginning of this section. The table contains the files that have been used in order to draft the conclusions of this project.
Below, an explanation of the results obtained from each selenoprotein is available, so as to complement the information from table.
Tabulated results
Figure 7. Table containing complete results of the process of annotation of Pseudonaja textilis' selenoproteins from the human genome. Green tick indicates the specific element (e.g. SECIS, seblastian output) was found on Pseudonaja textilis' genome; red cross indicates otherwise. Complete coded analysis has been attached to each column section of the table; hence, for proteins that have not been found on Pseudonaja textilis' genome only blast code is available. Further explanation on each selenoprotein is given below.
Glutathione peroxidases (GPx)
- GPx1 -
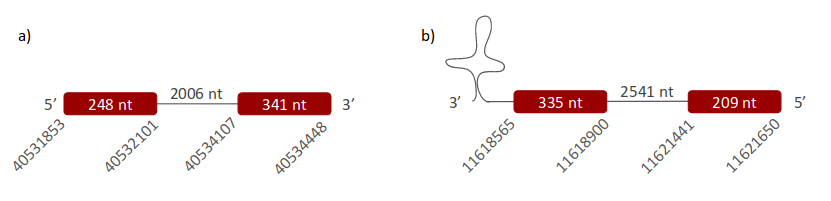
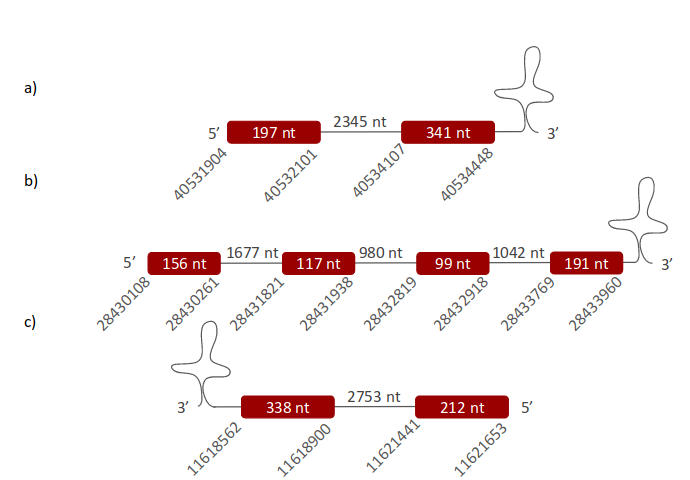
In Pseudonaja textilis’ genome GPx1 selenoprotein was located in two different scaffolds. The first one is ULFR01000004.1. It is located between positions 40531892 and 40534448 in the forward strand. One gene with two exons was found with the same scaffold positions coordinates (Fig 8a).Two SECIS candidates were predicted between positions 40553854-40553942 (+) strand and 40506937-40506990 (-) strand. No protein was predicted for this gene with the selenoprotein prediction server. The second scaffold, ULFR01000038.1, is between positions 11618565 and 11621647 in the reverse strand. One gene, with two exons, was found with the same initial point as the scaffold but the end point was located in 11621650 (Fig 8b). SECIS candidate was between positions 11618290-11618354 (-) strand. Protein prediction was GPx2.
- GPx2 -
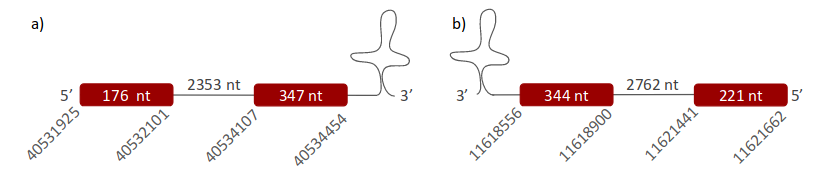
GPx2 was located in the same scaffolds as GPx1. The first one (ULFR01000004.1) was located between positions 40531871 and 40534454 in the forward strand. One gene with two exons was found with same scaffold position coordinates (Fig 9a). Two SECIS elements were predicted for this gene in positions 40553854-40553942 (+) strand and 40506937-40506990 (-) strand. No protein was found with the selenoprotein prediction server. The second scaffold (ULFR01000038.1) was found between positions 11618556 and 11621662 in the reverse strand. One gene with two exons was found with same scaffold positions coordinates (Fig 9b). Two SECIS candidates were located between positions 11618290-11618354(-) strand and 11585614-11585694 (-) strand. Protein prediction matched the protein analysed -GPx2-.
- GPx3 -
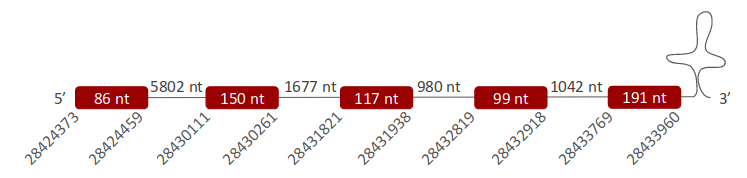
GPx3 was located in one specific scaffold, ULFR01000007.1, which is between positions 28430108 and 28433963 in the forward strand. One gene with five exons was found, its initial point being at 28424373 and end point being at 28433960 (+) strand (Fig 10). Three SECIS elements were predicted for this gene in positions 28429805-28429885 (+) strand, 28397088-28397160 (+) strand and 28458274-28458354 (+) strand. No protein was found with the selenoprotein prediction server.
- GPx4 -
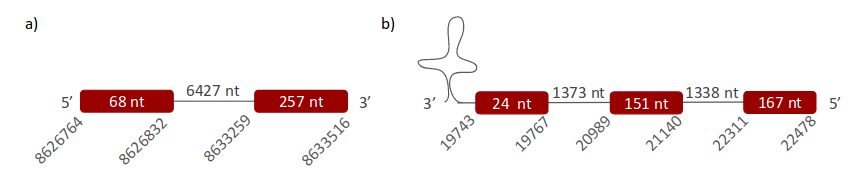
GPx4 was located in two different scaffolds. The first one, ULFR01000035.1, is located between positions 8633259 and 8633516 in the forward strand. One gene containing two exons was found in this scaffold; its initial point is 8626764 and the end point is 8633516 (Fig 11a). Neither SECIS elements nor proteins were predicted for this gene. The second scaffold, ULFR01000508.1, was found between positions 20991 and 22448 in the reverse strand. One gene with three exons was found between positions 19743 and 22478 (Fig 11b). One SECIS candidate was found, specifically between positions 16416 and 16491 (-) strand. Protein prediction matched the protein analysed -GPx4-.
- GPx5 -
GPx5 was located in three different scaffolds. The first one is ULFR01000004.1, located between positions 40531892 and 40534448 in the positive strand. One gene containing one exon was found; its initial and end point are 40534086-40534448 (Fig 12a). Two SECIS elements were predicted, specifically between positions 40553854-40553942 (+) strand and 40506937-40506990 (-) strand. No protein was predicted for this gene. The second scaffold, ULFR01000007.1, was located between positions 28430108 and 28433960 in the positive strand. One gene containing four exons was found between 28430105-28433960 (+) (Fig 12b). Three SECIS candidates were found in positions 28429805-28429885 (+) strand, 28397088-28397160 (+) strand and 28458274-28458354 (+) strand. No protein was predicted for this gene. The third scaffold is ULFR01000038.1 and it was located between positions 11618562 and 11621644 in the negative strand. One gene with two exons and with same end point as the scaffold has but initial point as 1618553. One SECIS element was predicted between positions 11618290-11618354 (-) strand. Protein predicted was GPx2.
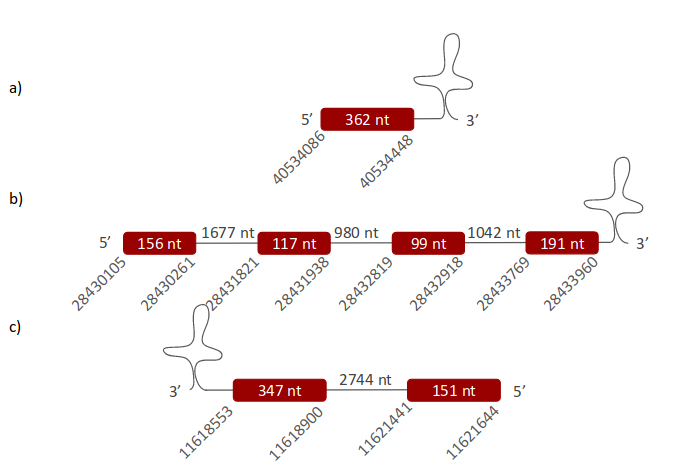
- GPx6 -
GPx6 was located in three different scaffolds. The first one is ULFR01000004.1 and it was found between positions 40531892 and 40534448 in the positive strand. One gene containing one exon was found and its initial and end point are 40531904-40534448 (Fig 13a). Two SECIS elements were predicted between positions 40553854-40553942 (+) strand and 40506937-40506990 (-) strand. No protein was predicted for this gene. The second scaffold, ULFR01000007.1, is between positions 28430108 and 28433960 in the positive strand. One gene containing four exons was found within the same position coordinates (Fig 13b). Three SECIS candidates were predicted, specifically between positions 28429805-28429885 (+) strand, 28397088-28397160 (+) strand and 28458274-28458354 (+) strand. No protein was predicted for this gene. The third scaffold is ULFR01000038.1 and it was found between positions 11618562 and 11621644 in the negative strand. One gene with two exons was found with initial point at 1618553 and same end point as its scaffold. One SECIS element was predicted, specifically between positions 11618290-11618354 (-) strand. The protein predicted from the gene was GPx2.
- GPx7 -
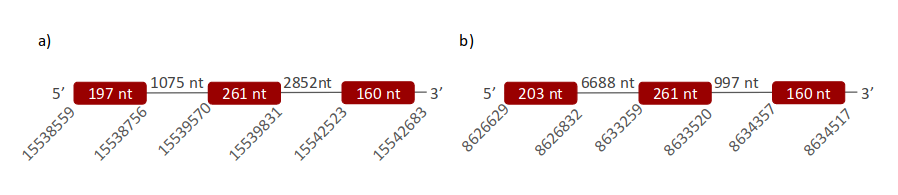
GPx7 was located in two different scaffolds. The first one is ULFR01000003.1 and is between positions 15539573 and 15542683 in the positive strand. One gene with three exons was found between position 15538685 and the end of the predicted scaffold (Fig 14a). Neither SECIS elements nor proteins were predicted for this gene. The second scaffold, ULFR01000035.1, is between positions 8626710 and 8634517 in the positive strand. One gene was found with three exons and its position is the same as the scaffold has (Fig 14b). Neither SECIS elements nor proteins were predicted for this gene with selenoprotein prediction server.
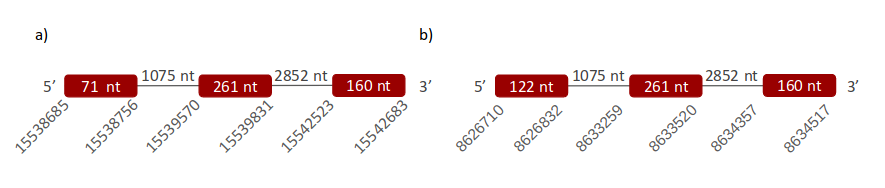
- GPx8 -
GPx8 was located in two different scaffolds. The first one is ULFR01000003.1. It was found between positions 15538559 and 15542683 in the positive strand. One gene containing three exons was found in the same coordinates as the scaffold (Fig 15a). Neither SECIS elements nor proteins were predicted for this gene. The second scaffold, ULFR01000035.1, was found between positions 8626710 and 8634517 in the positive strand. One gene with three exons was found with the same coordinates as the scaffold (Fig 15b). Neither SECIS elements nor proteins were predicted for this gene.
Iodothyronine deiodinases (DI)
- DI1 -
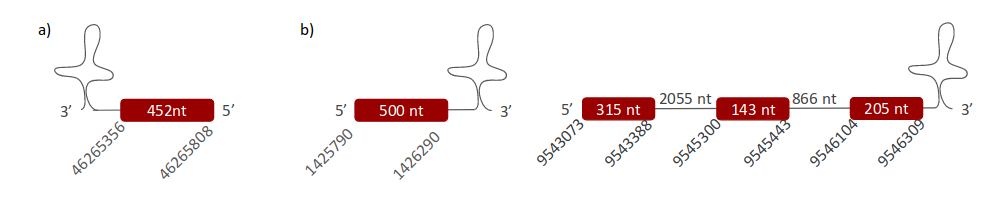
DI1 was located in three different scaffolds. The first one is ULFR01000002.1, and it was located between positions 46265356 and 46265934 in the negative strand. One gene containing one exon was found between the beginning of the scaffold and the genomic coordinate 46265808 (Fig 16a). One SECIS candidate was predicted, specifically between positions 46263880-46263957 (-) strand. The protein predicted was DI2. The second scaffold, ULFR01000011.1, was found between positions 1425748 and 1426290 in the positive strand. One gene containing one exon was found between coordinates 1425790-1426290 (Fig 16b). One SECIS candidate was predicted between positions 1426808-1426886 (+) strand. Protein prediction revealed DI3. The third scaffold is ULFR01000035.1 and it was located between coordinates 9543145-9546282. One gene containing three exons was found between positions 9543073-9546309. One SECIS element was predicted between positions 9547667-9547734 (+) strand. Protein predicted matched the protein analysed -DI1-.
- DI2 -
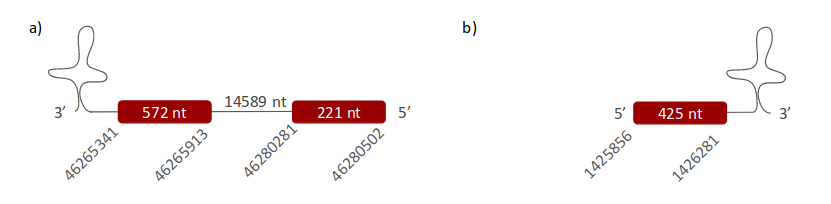
DI2 was located in two different scaffolds. The first one is ULFR01000002.1, and it was found between positions 46265341 and 46280502 in the negative strand. One gene containing two exons was found within the scaffold's coordinates (Fig 17a). One SECIS candidate was predicted between positions 46263880-46263957 (-) strand. Protein prediction matched the protein analysed -DI2-. The second scaffold, ULFR01000011.1, is between positions 1425727 and 1426281 in the positive strand. One gene containing one exon was found between positions 1425856-1426281 (Fig 17b). One SECIS candidate was predicted between positions 1426808-1426886 (+) strand. Protein prediction revealed DI3.
- DI3 -
DI3 was located in the same scaffolds as DI2. The first one is (ULFR01000002.1) was located between positions 46265904 and 46265356 in the negative strand. One gene containing one exon was found within 46265356-46265796 coordinates (Fig 18a). One SECIS candidate was predicted between positions 46263880-46263957 (-) strand. Protein predicted was DI2. The second scaffold, (ULFR01000011.1) is between positions 1425511 and 1426302 in the positive strand. One gene containing one exon was found between coordinates 1425472 - 1426296 (Fig 18b). One SECIS candidate was predicted between positions 1426808-1426886 (+) strand. Protein prediction was DI3.
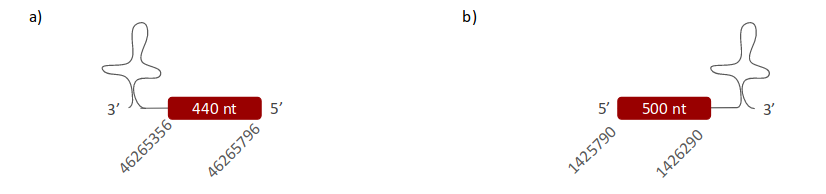
Selenoprotein 15
Sel15 was located in one scaffold, specifically in ULFR01000014.1, which is between positions 9557738 and 9557568 in the reverse strand. One gene comprising three exons was found between positions 9535428-9557738 (Fig 19). One SECIS element was predicted for this gene between positions 9534667-9534740 (-) strand. Protein predicted matched the protein analyzed -Sel15-.

Selenoprotein H
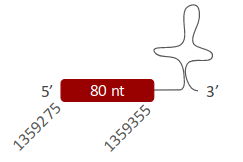
SelH was located in one scaffold (ULFR01000127.1) between positions 1354786 and 1359355 in the forward strand. One gene comprising one exon was found within coordinates 1359275 and 1359355 (Fig 20). One SECIS element was predicted for this gene between positions 1359931-1360019 (+) strand. Protein predicted matched the protein analyzed -SelH-.
Selenoprotein I
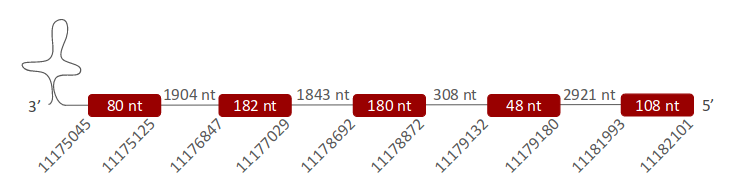
SelI was located in one scaffold (ULFR01000004.1), which was located between positions 11178662 and 11199140 in the reverse strand. One gene comprising five exons was located in coordinates 11175045 - 11182101 (Fig 21). One SECIS element was predicted for this gene in positions 1117399-11174072 (-) strand. Protein predicted was ethanolaminephosphotransferase 1.
Selenoprotein K
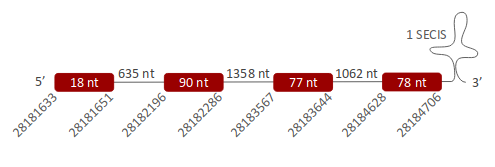
SelK was located in one scaffold (ULFR01000004.1), which was located between positions 28182195 and 28182338 in the forward strand. One gene comprising four exons was found between coordinates 28181633-28184706 (Fig 22). One SECIS element was predicted per this gene between positions 28185821-28185899 (+) strand. Protein predicted matched the protein analyzed -SelK-.
Selenoprotein M
SelM was located in one scaffold (ULFR01000207.1), which is between positions 70641 and 70769 in the forward strand. One gene comprising two exons was found between coordinatesand 69685-70766 (Fig 23). One SECIS element was predicted for this gene in positions 71473-71540 (+) strand. Protein predicted matched the protein analyzed -SelM-.

Selenoprotein N
SelN was located in one scaffold (ULFR01000020.1) which is between positions 7301308 and 7316151 in the reverse strand. One gene comprising eleven exons was found between the beginning of the scaffold and position 7316163 (Fig 24). Two SECIS elements were predicted per this gene in positions 7296454-7296526 (-) strand and 7318535-7318621 (-) strand. No proteins could be predicted per this gene.

Selenoprotein O
SelO was located in one scaffold (ULFR01000067.1), which was found between positions 3261929 and 3272837 in the reverse strand. One gene comprising ten exons was found between coordinates 3261430-3272855 (Fig 25). Two SECIS elements were predicted for this gene in positions 3261074-3261149 (-) strand. Protein predicted matches the protein analyzed -SelO-.

Selenoprotein P
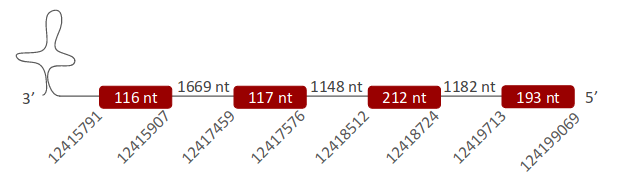
SelP was located in one scaffold (ULFR01000003.1), which was found between positions 12417456 and 12419906 in the reverse strand. One gene containing four exons was located between coordinates 12415791 and 12419906 (Fig 26). One SECIS element was predicted for this gene in positions 12414226-12414293 (-) strand. Protein predicted matches the protein analyzed -SelP-.
Selenoprotein R
- SelR1 -
SelR1 was located in one scaffold (ULFR01000003.1), which is between positions 275892 and 277049 in the reverse strand. One gene comprising two exons was found within the same coordinates as the scaffold (Fig 27). One SECIS element was predicted per this gene in positions 273115-273190 (-) strand. Protein predicted matches the protein analyzed -SerR1-.

- SelR2 -
SelR2 was located in scaffold (ULFR01000001.1>, which is between positions 38308522 and 38308415 in the reverse strand. One gene comprising one exon was found within coordinates 38308415 and 38308510 (Fig 28). Three SECIS elements were predicted for this gene in positions 38295757-38295834 (+) strand, 38259053-38259121 (+) strand and 38293634-38293713 (+) strand. No proteins were predicted for this gene.
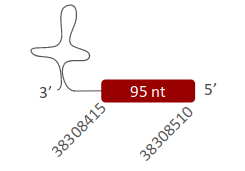
- SelR3 -
SelR3 was located in one scaffold (ULFR01000001.1), which is between positions 38308346 and 38328455 in the reverse strand. One gene comprising five exons was found between the initial point of the scaffold and position 38328467 (Fig 29). Three SECIS elements were predicted for this gene in positions 38295757-38295834 (+) strand, 38259053-38259121 (+) strand and 38293634-38293713 (+) strand. No protein was predicted for this gene.
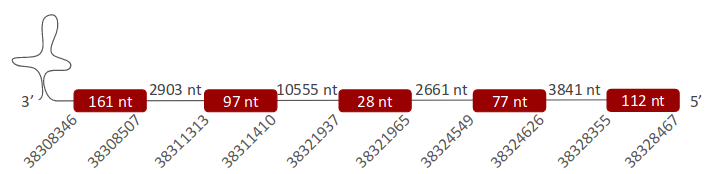
Selenoprotein S
SelS was located in one scaffold (ULFR01000044.1), which is between positions 7375323 and 7375246 in the reverse strand. One gene comprising five exons was located between positions 7370514 and 7376336 (Fig 30). Three SECIS elements were predicted for this gene in positions 7420367-7420446 (-) strand, 7402640-7402718 (+) strand and 7420055-7420132 (+) strand. No proteins were predicted for this gene.
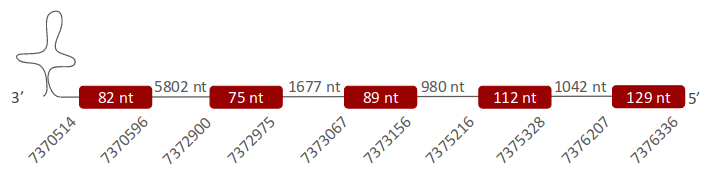
Selenoprotein T
SelT was found in two different scaffolds. The first one, ULFR01000017.1, was located between positions 19191158 and 19194423 in the positive strand. One gene comprising five exons was found between position 19184835 and the end of the scaffold (Fig 31a). One SECIS element was predicted for this gene in positions 19195016-19195099 (+) strand. Protein predicted matched the protein analyzed -SelT-. The second scaffold, ULFR01000041.1, was found between positions 1300452 and 1300697 in the positive strand. One gene comprising four exons was found between coordinates 1299765-1300697 (Fig 31b). One SECIS element was predicted for this gene in positions 1280847-1280918 (+) strand. No protein was predicted for this gene with Selenoprotein prediction server.

Selenoprotein U
- SelU1 -
SelU1 was located in two different scaffolds. The first one is ULFR01000071.1 and it was located between positions 4866533 and 4875802 in the reverse strand. One gene comprising five exons was found; its initial point corresponds to the beginning of the scaffold and the end point was located at coordinate 4878335 (Fig 32a). One SECIS element was predicted for this gene in positions 4866280-4866344 (-) strand. Protein predicted was redox-regulatory protein FAM213A. The second scaffold, ULFR01000072.1, was located between positions 3671 and 12941 in the forward strand. One gene containing five exons was found between coordinate 1138 and end point positioned at the end of the scaffold (Fig 32b). One SECIS element was predicted for this gene in positions 13130-13194 (+) strand. Protein predicted was the same as the protein predicted for the first scaffold -FAM213A-.

- SelU2 -
SelU2 was located in one scaffold (ULFR01000024.1), which was found between positions 11437471 and 11440572 in the forward strand. One gene containing five exons was located between the beginning of the scaffold and coordinate 11442929 (Fig 33). Neither SECIS elements nor proteins were predicted per this gene.

- SelU3 -
No data regarding selenoprotein SelU3 could be found in Pseudonaja textilis' genome when compared to Homo sapiens' genome using the homology-based methods mentioned.
SelV
No data regarding selenoprotein SelV could be found in Pseudonaja textilis' genome when compared to Homo sapiens' genome using the homology-based methods mentioned.
Selenoprotein W
- SelW1 -
SelW1 was found in one scaffold (ULFR01000078.1), which was located between positions 2133506 and 2133577 in the forward strand. One gene comprising three exons was found between coordinates 2132868-2134498 (Fig 34). One SECIS element was predicted for this gene in positions 2135271-2135359 (+) strand. Protein predicted matched the protein analyzed -SelW1-.
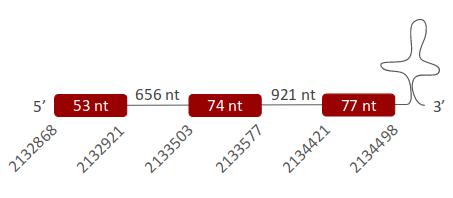
- SelW2 -
SelW2 was located in one scaffold (ULFR01000096.1), which was located between positions 1698998 and 1700770 in the forward strand. One gene comprising three exons was found between the same coordinates the scaffold has (Fig 35). One SECIS element was predicted for this gene in positions 1689371-1689442 (-) strand. No protein was predicted per this gene.

Methionine sulfoxide reductase A
MrsA was located in two different scaffolds. The first scaffold is ULFR01000020.1 and it is located between positions 4237109 and 4267287 in the forward strand. One gene comprising four exons was found between the beginning of the scaffold and coordinate 4249389 (Fig 36a). Neither SECIS nor protein were predicted for this gene. The second scaffold, ULFR01000081.1, is between positions 1606490 and 1726958 in the reverse strand. One gene comprising five exons was found between coordinates 1606490-1699071 (Fig 36b). Two SECIS were predicted for this gene in positions 1654525-1654615 (-) strand and 1597251-1597342 (+) strand. No protein was predicted.
Thioredoxin reductases (TR)
- TR1 -
TR1 was located in two different scaffolds. The first one is ULFR01000001.1 and it was located between positions 16006652 and 16020009 in the forward strand. One gene comprising thirteen exons was found between coordinates 16000451-16024075 (Fig 37a). One SECIS element was predicted for this gene in positions 16024303-16024379 (+) strand. Protein predicted was TR1. The second scaffold, ULFR01000004.1, was located between positions 21579488 and 21587480 in the reverse strand. One gene comprising eight exons was found between coordinates 21582186-21591247 (Fig 37b). Three SECIS elements were predicted for this gene in positions 21578116-21578189 (-) strand, 21590870-21590941 (-) strand and 21613549-21613628 (+) strand. No protein was predicted per this gene.
- TR2 -
TR2 was located in three different scaffolds. The first one (ULFR01000001.1) was found between positions 16006652 and 16020009 in the forward strand. One gene comprising seven exons was found between coordinates 16006652-16024075 (Fig 38a). One SECIS element was predicted for this gene in positions 16024303-16024379 (+) strand. Protein predicted was TR1 (as expected). The second scaffold, ULFR01000004.1, was located between positions 21579485 and 21588589 in the forward strand. One gene comprising five exons was found between the starting point of the scaffold and final coordinate 21587480 (Fig 38b). Three SECIS elements were predicted for this gene in positions 21578116-21578189 (-) strand, 21590870-21590941 (-) strand and 21613549-21613628 (+) strand. No protein was predicted for this gene. The third scaffold, ULFR01000085.1, is between positions 3091680 and 3111523 in the forward strand. One gene comprising eleven exons was found between coordinate 3089808 and the end point of the scaffold (Fig 38c). One SECIS element was predicted for this gene between positions 13113947-3114027 (+) strand. No protein was predicted for this gene.

- TR3 -
TR3 was located in two different scaffolds. The first one (ULFR01000001.1) was located between positions 16006652 and 16020009 in the forward strand. One gene comprising ten exons was found between coordinates 16000442-16019982 (Fig 39a). One SECIS element was predicted for this gene in positions 16024303-16024379 (+) strand. Protein predicted was TR1 (again, as expected). The second scaffold, ULFR01000004.1, was located between positions 21579488 and 21592078 in the reverse strand. One gene comprising fourteen exons was located between coordinates 21578407-21603562 (Fig 39b). Three SECIS elements were predicted for this gene in positions 21578116-21578189 (-) strand, 21590870-21590941 (-) strand and 21613549-21613628 (+) strand. No protein was predicted per this gene.
Machinery selenoproteins
- SECp43 -
SECp43 was located in one scaffold (ULFR01000020.1), which was located between positions 4009210 and 4020733 in the forward strand. One gene comprising nine exons was located between coordinate 4007392 and the final coordinate of the scaffold (Fig 40). One SECIS element was predicted for this gene within positions 4013517-4013591 (-) strand. No protein was predicted for this gene.
- SECIS binding protein 2 (SBP2) -
SBP2 was located in one scaffold (ULFR01000024.1), which was located between positions 13856600 and 13875203 in the forward strand. One gene comprising eight exons was located between the initial coordinate of the scaffold and position 13877059 (Fig 41). Two SECIS elements were predicted for this gene in positions 13830923-13831001 (-) strand and 13842642-13842713 (+) strand. No protein was predicted for this gene.

- O-phosphoseryl-tRNA(Sec) kinase (PSTK) -
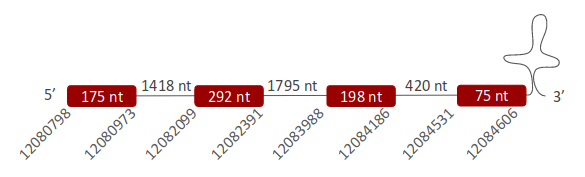
PSTK was located in one scaffold (ULFR01000026.1), which was located between positions 12080798 and 12086332 in the forward strand. One gene comprising four exons was found between the initial coordinate of the scaffold and coordinate 12084606 (Fig 42). One SECIS element was predicted for this gene in positions 12034916-12034991 (+) strand. No protein was predicted for this gene.
- Sec synthase (SecS) -
SecS was located in one scaffold (ULFR01000013.1), which was located between positions 13856600 and 13875203 in the forward strand. One gene comprising eight exons was located between the initial coordinate of the scaffold and coordinate 13877059 (Fig 43). Neither SECIS elements nor proteins were predicted per this gene.

- Selenophosphate synthetase 1 (SPS1) -
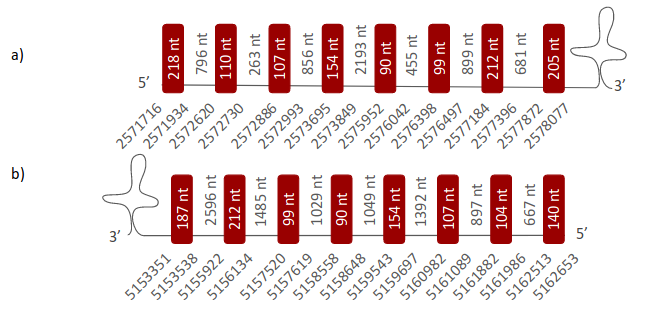
SPS1 was located in two different scaffolds. The first one is ULFR01000053.1 and it was located between positions 2571818 and 2578056 in the forward strand. One gene comprising eight exons was found between the initial coordinate of the scaffold and coordinate 2578050 (Fig 44a). One SECIS element was predicted per this gene in positions 2578428-2578502 (+) strand. Protein predicted was SPS2. The second scaffold, ULFR01000059.1, was located between positions 5153327 and 5162647 in the reverse strand. One gene containing eight exons was located between the scaffold coordinates (Fig 44b). One SECIS element was predicted for this gene in positions 5108853-5108928 (-) strand. No protein was predicted per this gene.

- Selenophosphate synthetase 2 (SPS2) -
SPS2 was located in two different scaffolds. The first one is ULFR01000053.1 and it was located between positions 2571809 and 2578056 in the forward strand. One gene comprising eight exons was found between coordinates 2571716-2578077 (Fig 45a). One SECIS element was predicted for this gene in positions 2578428-2578502 (+) strand. Protein predicted matched the protein analayzed -SPS2-. The second scaffold, ULFR01000059.1, was located between positions 5153351 and 5162629 in the reverse strand. One gene comprising eight exons was located between the initial coordinate of the scaffold and coordinate 5162653 (Fig 45b). One SECIS element was predicted for this gene in positions 5108853-5108928 (-) strand. No protein was predicted for this gene.
- Selenocysteine Eukaryotic elongation factor (eEFSec) -
eEFSec was located in one scaffold (ULFR01000004.1), which was located between positions 24154157 and 24327532 in the forward strand. One gene comprising eight exons was found between coordinate 24154130 and the final coordinate of the scaffold (Fig 46). Three SECIS elements were predicted for this gene in positions 24234423-24234510 (+) strand and 24195338-24195415 (-) strand and 24294823-24294903 (+) strand. No protein was predicted for this gene.

Discussion
Previous considerations
The aim of this project was to determine all selenoprotein genes (including machinery and cysteine-containing homologues) present in Pseudonaja textilis' genome. In order to determine these proteins, all Homo sapiens’ selenoprotein sequences were used to identify homologous proteins in the analysed species. All the results obtained for each selenoprotein were carefully analysed and discussed, paying special attention to the T-Coffee output and SECIS elements prediction.
The criteria for deciding whether a detected protein in Pseudonaja textilis' genome was a selenoprotein, a cysteine-containing homologue or neither of them was the following:
- Selenoprotein: at least one selenocysteine (Sec) was detected in the T-Coffee output and a SECIS element was located at the 3'UTR region of the gene.
- Cysteine-containing homologue: a cysteine (Cys) from Pseudonaja textilis’ genome was aligned with a Sec (or a Cys) from the Homo sapiens’ genome.
- Others: some proteins could have been lost, or replaced their Sec for another amino acid other than Cys. Hence, these proteins are not considered selenoproteins nor Cys-containing homologues.
Glutathione peroxidases
Glutathione peroxidases (GPxs) are the largest selenoprotein family, widespread in all three domains of life[12]. These eight proteins play a key role in protecting the organism from oxidative damage by catalyzing the reduction of harmful hydroperoxides with thiol cofactors[13]. Most GPxs (GPx1, GPx2, GPx3, GPx4, GPX6) contain a Sec residue at its active site[12, 13]. However, in some cases (GPx5, GPx7, GPx8) the Sec from the active site has been replaced by a Cys in some species[12, 13].
In order to study the results obtained from Pseudonaja textilis' genome analysis, a phylogenetic tree was constructed to compare the amino acid sequences of all possible found GPxs genes with the human GPxs queries (Fig 47).
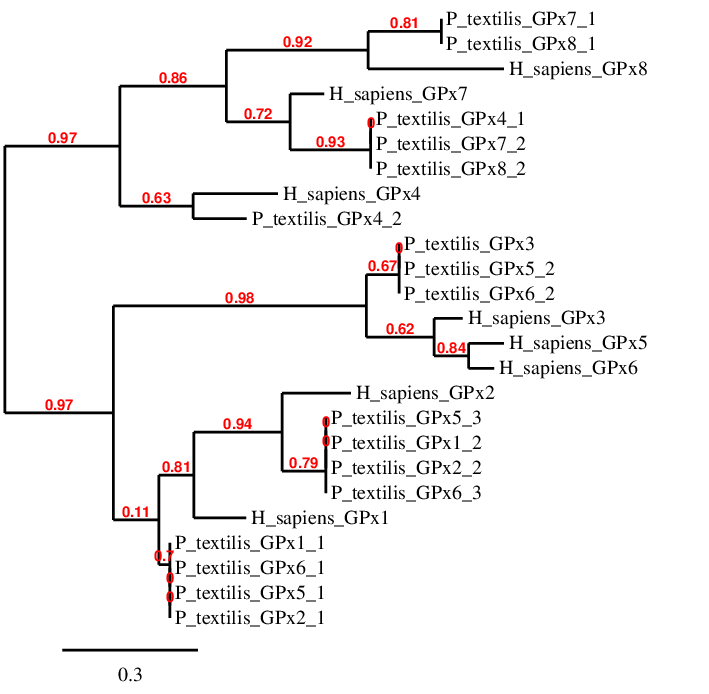
Next, each GPx is discussed individually in order to find out which of these family proteins are found in the Pseudonaja textilis' genome, and if so, where.
- GPx1 -
According to the tree, there are four scaffolds (GPx1_1, GPx2_1, GPx5_1 and GPx6_1) closely related to human GPx1. Amongst these sequences, the one with the best T-Coffee output is the GPx1_1, because it has the largest amino acid sequence and the best alignment score. The other scaffolds are located in the same position as GPx1_1; therefore, it was deduced that these predictions are not GPx1 duplications.
The alignment of GPx1_1 and the human query showed that Pseudonaja textilis’ predicted protein had a Sec in the same position as the human selenoprotein. However, the predicted GPx1 sequence started with Cys instead of Met, differing from the human query and the majority of proteins. This difference could be explained by mistakes during transcript annotation. Another possible explanation for this phenomenon could be that Pseudonaja textilis' selenoprotein has suffered a modification caused by evolution. About SECIS elements prediction, two candidates were found; one in each DNA strand. Knowing that the gene obtained from GPX1_1 is located in the forward strand, the SECIS element that was selected was the one that was in the same strand (3’ UTR region).
In conclusion, GPx1 has been found in the genome of Pseudonaja textilis', more precisely in the forward strand between positions 40531892-40534448, and it has two exons and one SECIS between positions 40553854-40553942; this was concluded although no proteins were predicted with Seblastian in this case.
- GPx2 -
GPx2 has been associated with four scaffolds (GPx1_2, GPx2_2, GPx5_3, GPx6_3). According to T-Coffee output, GPx2_2 has the best alignment with the human GPx2, because it has the complete sequence and the best alignment score. In this case, Pseudonaja textilis’ sequence starts with Met, as well as the human query. Both sequences have the Sec aligned as well. The other three possible gene predictions were located in the same genome positions as GPx2, hence these are not duplications.
These results indicate that GPx2 is found in Pseudonaja textilis, specifically between positions 11618556-11621662 in the reverse strand. Moreover, this gene was found to have two exons and one SECIS between 11585614-11585694. There were two SECIS prediction, the one chosen was located in 3’UTR region. Protein predicted matched these results.
- GPx3 -
GPx3 analysis was influenced by selenoprotein predictions of GPx5 and GPx6. These three human proteins are equally related to three Pseudonaja textilis’ scaffolds (GPx3, GPx5_2, GPx6_2). A selenoproteome evolution study has found that GPx5 and GPx6 are the most recently evolved GPxs; these selenoproteins appear to be the result of a tandem duplication of GPx3 at the root of placental mammals[14]. Therefore, GPx3 was found to be highly related to these scaffolds. The possibility that GPx3 also duplicated at some point of the evolutionary process of Pseudonaja textilis could be considered, but due to the lack of time faced during this analysis, GPx5 and GPx6 are not going to be taken into account since Pseudonaja textilis is a reptile. The scaffold GPx3 had the best alignment with the query because it was the largest one and had the highest score. Only nine amino acid gaps were found at the end of the sequence, probably because transcript was not annotated correctly. Moreover, this sequence starts with Met and contains a Sec aligned with the Sec from the human sequence. Refering to the SECIS, three SECIS were predicted for GPx3, but only one in the 3’UTR region.
It was concluded that GPx3 was located between positions 28424373-8433960 in Pseudonaja textilis’ genome. This gene was found to have five exons and a SECIS element between positions 28458274-28458354 (in the forward strand). These conclusions were drafted although Seblastian did not predict any protein in this case.
- GPx4 -
GPx4 was only associated to scaffold GPx4_2. This could be explained because GPx4 is the most evolutionary conserved selenoprotein[14]. Both sequences (query and predicted selenoprotein) have a Sec; however, in Pseudonaja textilis’ sequence many gaps were found at both the beginning and end of the sequence. This could be because the sequence has not been annotated correctly or due to evolutionary change in Pseudonaja textilis’ genome.
GPx4_2 gene was found to have three exons between positions 19743-22478 in the reverse strand, and one SECIS candidate was found in the 3’UTR region of the gene between positions 16416-6491. With this information is possible to say that GPx4 is found in the Pseudonaja textilis' genome. Protein prediction with Seblastian also matched this conclusion.
- GPx7 -
GPx7 was found to be related to three scaffolds: GPx4_1, GPx7_2 and GPx8_2. The best sequence alignment (with the human query) out of these three scaffolds was found with GPx7_2. All the predicted genes for GPx7 were located in similar positions, therefore, it was concluded that there was no duplication for GPx7. Neither the predicted protein nor the human query were found to have Sec; they both had Cys. In conclusion, GPx7 is found in Pseudonaja textilis genome, its gene has three exons and it is located between positions 8626710-8634517 in the positive strand. Neither SECIS nor protein were predicted for this gene, and this results matched the conclusion drafted: GPx7 protein in Pseudonaja textilis’ genome is a cysteine-containing homologue.
- GPx8 -
GPx7_1 and GPx8_1 have been related to human GPx8. Looking at the T-Coffee output, the best is GPx8_1, because it has all the sequence annotated except two gaps located at the beginning of the alignment. In this case there is not a duplication because both genes are in the same location. About the amino acid Sec, it wasn’t found in human GPx8 and, according to our results, neither in Pseudonaja textilis’ scaffold GPx8_1. This amino acid has been substituted for a Cys in both cases. These results suggest that GPx8 is localized in the Pseudonaja textilis’ genome between positions 15538559-15542683, in the positive strand. Neither SECIS nor protein were predicted for this gene, and this results match with the conclusion: Pseudonaja textilis’ GPx8 is a cysteine-containing homologue as well.
To conclude, GPx family contains eight GPxs homologue selenoproteins that are heterogeneously distributed amongst species. In the case of most reptiles, GPx5 and GPx6 are missing because both proteins were generated after the separation between mammals and the rest of vertebrates[14]. The rest (six GPx proteins) have been localized in the genome of this reptile. Four of these six (GPx1, GPx2, GPx3, GPx4) contain a Sec residue in their active site[12], and this residue has been conserved in both species (human and Pseudonaja textilis). In the case of the other two proteins (GPx7, GPx8), the Sec residue has been substituted for a Cys[12] in humans and in Pseudonaja textilis as well. Finally, it is worth highlighting that in the analysis of these proteins the same scaffolds have been correlated with different GPxs proteins in many occasions, but no duplications have been detected. The explanation to this phenomenon relies on the fact that in the ancestor of vertebrates there were only GPx1-4; the rest of the selenoproteins of this family were originated from these first four. Hence, all sequences are similar amongst themselves[14, 13]. In this case, it would be easier to compare them using a more accurate program to do the alignment.
Iodothyronine deiodinases
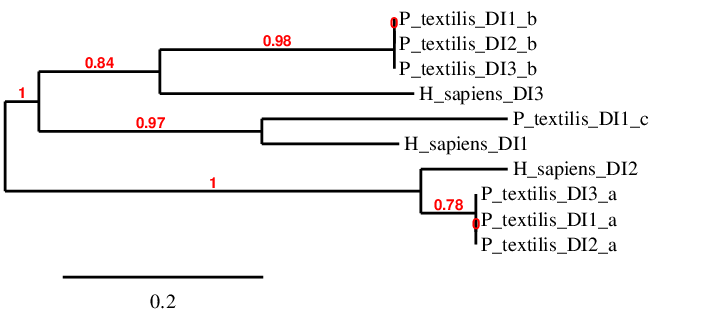
Iodothyronine deiodinases (DIs) regulate the activation and inactivation of thyroid hormone[15]. There are three DIs, and each of them have different functions. D2 is directed almost exclusively to the efficient conversion of T4 to T3 by 5′-deiodination (an activating reaction)[16]. D3 inactivates T4 and T3 by converting them to relatively inactive lesser iodothyronines (rT3 and 3,3′-diiodothyronine, T2) by 5-deiodination[16]. In contrast, D1 is able to catalyze both 5- and 5′-deiodination and can act on a variety of different iodothyronines[16]. All three proteins were found in the vertebral ancestor and in mammals they all have Sec[14]. The deiodinases possess a thioredoxin-fold and show significant intra-family homology[14]. In order to facilitate the analysis, a phylogenetic tree has been done to compare the amino acid sequences from scaffolds related to DIs with the human sequences.
- DI1 -
DI1 is only closely related to DI1_c. Both have only one Sec and they are aligned. However, Pseudonaja textilis’ scaffold has two regions of gaps at the beginning and the end of the alignment. Consequently, it is not known if the analyzed sequence starts with Met, another amino acid or with a real gap. Moreover, this causes that the exact amount of Sec cannot be observed. Despite these two objections, it is possible to deduce that DI1 is found in the Pseudonaja textilis’ genome, specifically in the forward strand between positions 9543073-9546309, and its SECIS element is located between 9547667-9547734. Its gene has three exons. Protein predicted matched our conclusion.
- DI2 -
DI2_a scaffold is perfectly aligned with human DI2. The other two scaffolds (DI1_a, DI3_a) related to human DI2 are in the same genomic locations than DI2_a; hence there are no duplications for this gene in Pseudonaja textilis. About the alignment between DI2_a and the human protein, both have one Sec and start with Met. Therefore, DI2 is found in Pseudonaja textilis’ genome; its gene has two exons and it is located between positions 46265341-46280502 in the reverse strand. The SECIS was located between coordinates 46263880-46263957. Protein predicted matched the extracted conclusions.
- DI 3-
DI3 was associated with three scaffolds (DI1_b, DI2_b, DI3_b); all of them were found in similar locations, therefore they are not duplications. DI3_b has the best alignment with the human query; however, some gaps were found at the end of the alignment, due to evolutionary processes or incorrect annotation. Despite this fact, scaffold DI3_b has a Sec aligned with the human protein, and both protein sequences starts with Met. Consequently, it can be stated that DI3 is found in Pseudonaja textilis’ genome; it has one exon and it is located between coordinates 1425472-1426296 in the forward strand. The SECIS element was located between coordinates 1426808 -1426886. Protein predicted matched the extracted conclusions.
In conclusion, all three enzymes from DI family were found in the genome of Pseudonaja textilis, and have one Sec aligned with the Sec from the respective human query.
Selenoprotein 15
The 15-kDa selenoprotein 15 is a thioredoxin-like protein located in the endoplasmic reticulum (ER). Although its specific function is not known, it is involved in the quality control of glycoprotein folding through its interaction with the UDP-glucose glycoprotein-glucosyltransferase[17].
Sel15 was found in one scaffold, ULFR01000014.1. The predicted gene was located between positions 9557738-9557568 in the reverse strand, containing three exons. In the T-Coffee output, a Sec residue was aligned with Sec from the human query. However, there were some gaps at the beginning of the protein sequence and it is not possible to know which is the first aminoacid of the sequence. About SECIS element prediction, one candidate element was found in the reverse strand and 3’ UTR region between positions 9534667-9534740. Seblastian predicted a 15 kDa selenoprotein. In conclusion, Sel15 was found in Pseudonaja textilis' genome as a selenoprotein.
Selenoprotein H
SelH is a thioredoxin-like selenoprotein located uniquely in the nucleoli. It is highly expressed during embryonic development and it is associated with heat shock and stress response regulation. Also, it possesses glutathione peroxidase activity and is involved in glutathione synthesis[12].
SelH was found in one scaffold, ULFR01000127.1. The predicted gene was located between positions 1359275-1359355 in the forward strand, containing one exon. In the T-Coffee output obtained, the candidate Sec-containing region (from the Pseudonaja textilis’ genome) aligned with the human query was missing, and the prediction did not start with Met. Regarding SECIS element prediction, one candidate was found in the forward strand and 3’ UTR region between positions 1359931-1360019. Also, Seblastian predicted selenoprotein H isoform X2. Thus, results indicate there is a high probability to find SelH with the Sec in Pseudonaja textilis’ genome, but due to an incomplete annotation during this selenoprotein’s analysis Sec has not been detected.
Selenoprotein I
SelI is a recently evolved selenoprotein, which is found only in vertebrates. It is one of the least studied selenoproteins, thus its function is yet unknown. However, it is known to be a transmembrane protein containing a highly conserved CDP-alcohol phosphatidyltransferase domain[12, 18].
SelI was found in one scaffold, ULFR01000041.1. The predicted gene was located between positions 11175045-11182101 in the reverse strand, containing five exons. In the T-Coffee output, Sec from Pseudonaja textilis’ genome was aligned with Sec from the human query, and the prediction started with Met. Pseudonaja textilis’ sequence was perfectly aligned with the human query except for three gaps at the end of the alignment. Regarding SECIS prediction, one candidate element was found at the reverse strand 3’ UTR region between positions 1117399-11174072. Therefore, it was concluded that SelI is found in Pseudonaja textilis' genome.
Selenoprotein K
SelK is a 16-kDa selenoprotein located in the ER and the plasma membranes. It belongs to a type III group of transmembrane proteins. It contains a single transmembrane domain, and is implicated in ER-associated degradation of misfolded proteins. It is highly expressed in the heart, where it may function as an antioxidant[19, 12].
SelK was found in one scaffold, ULFR01000004.1. The predicted gene was located between positions 28181633-28184706 in the forward strand, comprising four exons. In the T-Coffee output, Pseudonaja textilis’ candidate Sec-containing region was missing, probably due to incorrect annotation. Despite this fact, the alignment was good and both sequences started with Met. About SECIS element prediction, one candidate was found in the forward strand and 3’ UTR region between positions 28185821-28185899. Seblastian predicted selenoprotein K isoform X1. Above, it was concluded that Selk was in Pseudonaja textilis' genome as a Sec-containing selenoprotein.
Selenoprotein M
SelM is a distant homolog of Sel15, a thioredoxin-like protein located in the ER. It is highly expressed in the brain, where it is may play a neuroprotective role[17, 20].
SelM was found in one scaffold, ULFR01000207.1. The predicted gene was located between positions 69685-70766 in the forward strand, containing two exons. The T-Coffee output revealed multiple gaps in the Pseudonaja textilis’ sequence; in consequence, Sec-containing candidate region was missing; furthermore, prediction did not start with Met. About SECIS element prediction, one candidate was found in the forward strand 3’ UTR region between positions 71473-71540. Also, Seblastian predicted selenoprotein M. Therefore, despite Sec and Met being missing, it was conclude that SelM was found in the Pseudonaja textilis' genome.
Selenoprotein N
SelN is a transmembrane glycoprotein located in the ER. It is highly expressed during embryonic development; however its function remains unknown. In adult skeletal muscle it is essential for muscle regeneration and satellite cell maintenance, and it is also involved in the intracellular calcium mobilization through its interaction with the ryanodine receptor. Its deficiency is linked to several forms of early-onset myopathies[12, 21].
SelN was found in one scaffold, ULFR01000020.1. The predicted gene was located between positions 7301308-7316163 in the reverse strand, comprising eleven exons. In the T-Coffee output, two Sec were found in the Pseudonaja textilis’ protein sequence. Only one of these two amino acids was aligned with the corresponding human one. However, despite the alignment being good, some gaps were found in one of the two Sec-containing regions from P.textilis’ genome. Therefore, it would be possible that P.textilis’ SelN had even three Sec residues. Further studies should be performed to prove this hypothesis. About SECIS prediction, two candidate elements were found in the reverse strand between positions 7296454-7296526, and 7318535-7318621, with only the last one being at 3’ UTR region. In this case, no known selenoproteins were predicted by Seblastian. Therefore, it can be concluded that Pseudonaja textilis' genome contains a SelN protein with Sec residues.
Selenoprotein O
SelO is a widely distributed selenoprotein and one of the least characterized. It is located in the mitochondria, where it may exert an antioxidant effect, but its exact function is not known [12, 22].
SelO was found in one scaffold, ULFR01000067.1. The predicted gene was located between positions 3261430-3272855 in the reverse strand, comprising ten exons. In the T-Coffee output, its Sec residue was aligned with a Sec from the human query; however, the prediction did not start with a Met because some gaps where found in the initial part of P.textilis’ sequence. About SECIS prediction, one candidate element was found in the reverse strand downstream 3’ UTR region between positions 3261074-3261149. In addition, Seblastian predicted the selenoprotein O, so in conclusion, Pseudonaja textilis' genome contains the SelO as selenoprotein.
Selenoprotein P
SelP is an abundant glycoprotein found in the plasma. The unique feature of SelP is the presence of multiple Sec residues and SECIS elements, which can vary between species. It is responsible for the transport and delivery of selenium to peripheral tissues and also, it is linked to an antioxidant function[23, 24].
SelP was found in one scaffold, ULFR01000003.1. The predicted gene was located between positions 12415791-12419906 in the reverse strand, comprising four exons. In the T-Coffee output, only one Sec residue from P.textilis was aligned with a Sec from the human query, which in fact contains ten residues of this amino acid. P.textilis may have more Secs, but the part of the human quert where most Secs could be found was missing in P.textilis’ genome. More studies should be performed to investigate if these gaps are real or a consequence of an incorrect annotation. Despite this, the prediction did start with Met. About SECIS prediction, one candidate elements was found in the reverse strand and 3’ UTR region between positions 12414226-12414293. What is more, Seblastian predicted selenoprotein P. Therefore, it is concluded that SelP is in in Pseudonaja textilis' genome as a selenoprotein.
Selenoprotein R
- Sel R1-
SelR1 or MsrB1 is a zinc-containing Methionine sulfoxide reductase located both in the cell nucleus and cytosol. It functions as an important antioxidant enzyme with Sec that participates in oxidized protein repair[12, 24].
SelR1 was found in one scaffold, ULFR01000025.1. The predicted gene was located between positions 275892-277049 in the reverse strand, comprising two exons. In the T-Coffee output, Sec contained in the P.textilis’ genome was aligned with Sec from the human query; however, the predicted protein did not start with Met. Regarding SECIS element prediction, one candidate was found in the reverse strand 3’ UTR region between positions 273115-273190. What is more, Seblastian predicted methionine-R-sulfoxide reductase B1 isoform X1. Thus, it can be concluded that Pseudonaja textilis' genome contains a SelR1 as a selenoprotein.
- Sel R2 -
SelR2 or MsrB2 is a Cys-containing homolog located in the mitochondria, where it repairs proteins particularly susceptible to oxidative damage. Compared to SelR1, it less catalytically efficient, though similar[26, 27].
SelR2 was found in one scaffold, ULFR01000001.1. The predicted gene was located between positions 38308415-38308510 in the reverse strand, comprising one exon. In the T-Coffee output the alignment contained many gaps, in consequence no solid conclusions can be extracted from this output. Despite this fact, a Cys from the human sequence was aligned with a Cys in the snake sequence. About SECIS element prediction, three candidates were found in the positive strand and were thus ruled out. In this case, no known selenoproteins were predicted by Seblastian. The fact that the alignment was in this case really bad prevented conclusions extraction. Therefore, further studies should be done to investigate whether SelR2 is in P.textilis’ genome and if it contains Sec or Cys.
- Sel R3 -
SelR3 or MsrB3 is a Cys-containing homologue with two isoforms located both in the mitochondria and ER[26].
SelR3 was found in one scaffold, ULFR01000001.1. The predicted gene was located between positions 38308346-38328467 in the reverse strand, comprising five exons. In the T-Coffee output, Cys residue from P.textilis’ genome was aligned with Cys from the human query; however, the predicted gene did not start with Met, because there were some missing amino acids at the beginning of the alignment. Despite this, the alignment was good. Regarding SECIS prediction, three candidate elements were found in the positive strand and were thus ruled out. In this case, no known selenoproteins were predicted by Seblastian. In conclusion, e, SelR3 is in the in Pseudonaja textilis' genome as a Cys-containing homologue.
Selenoprotein S
SelS is a selenoprotein which is structurally similar to SelK. It is located in the ER membrane, where it participates in ER-associated degradation of misfolded proteins[12].
SelS was found in one scaffold, ULFR01000044.1. The predicted gene was located between positions 7370514-7376336 in the reverse strand, comprising five exons. In the T-Coffee output, Sec from P.textilis’ genome was aligned with Sec from the human query; however, the predicted protein did not start with Met because some parts of P.textilis’ amino acid sequence were missing. Despite this fact, the alignment was good. Regarding SECIS element prediction, one out of three candidate elements was found in the reverse strand between positions 7420367-7420446, but not in 3’ UTR region; thus it was ruled out. In this case, no known selenoproteins were predicted by Seblastian. These results were contradictory, because a Sec residue was found but no valid SECIS elements were predicted. This could have been due to an incorrect annotiation. Despite this fact, it can be concluded that SelS could be found in Pseudonaja textilis' genome, but further research would be necessary in the 3’ UTR region to find out a SECIS element.
Selenoprotein T
SelT is a thioredoxin-like protein mainly located in the ER and Golgi. It is involved in the regulation of Ca2+ homeostasis and neuroendocrine function, and it may exert a neuroprotective role in dopaminergic neurons.[28, 29]
SelT was found in two scaffolds: ULFR01000017.1 and ULFR01000041.1. The predicted genes were located between positions 19184835-19194423 and 1299765-1300697, respectively. As the positions are not similar at all, a selenoprotein duplication in the Pseudonaja textilis' genome could be deduced. Among these sequences, the best T-Coffee corresponded to the second, having the highest alignment score and similar amino acid sequence. However, the first one has a good alignment as well, but with two gapped regions at the beginning and end of the alignment. Moreover, both T-Coffee outputs contained a Sec from Pseudonaja textilis' genome aligned with the Sec from the human query. Despite this fact, only in the first scaffold a SECIS element could be predicted in 3’UTR region. Thus, it is concluded that SelT (as a Sec-containing selenoprotein) is found in Pseudonaja textilis' genome, more precisely in the forward strand, its SECIS element located between positions 19195016-19195099. This conclusion matches the Seblastian prediction. Regarding the duplication, the fact that in the second scaffold no SECIS elements could be found (but a Sec was identified), and Seblastian provided no predictions, it cannot be concluded neither whether this duplication has occurred, nor if this possible SelT is a selenoprotein or a cysteine-containing homologue. More studies should be done in order to investigate this.
Selenoprotein U
- Sel U1 -
SelU1 is a newly identified selenoprotein highly expressed in the bone, brain, liver and kidney. In some vertebrate lineages it is a Cys-containing homolog and possesses the conserved thioredoxin-like fold; however its function is unknown[30, 31].
SelU1 was found in two scaffolds: ULFR01000071.1 and ULFR01001072.1. The predicted genes were located between positions 4866533-4878335 and 1138-12941, respectively. As the positions are not similar at all, a selenoprotein duplication in the Pseudonaja textilis' genome could be deduced. In the T-Coffee output, both scaffolds had the same alignment score and amino acid sequence. Moreover, both Pseudonaja textilis' sequences contained a Sec but the human sequence didn’t; a SECIS element was predicted in their 3’ UTR region for both scaffolds. Therefore, both proteins are selenoproteins. The first predicted gene comprised five exons and was located in the reverse strand with its SECIS element between positions 4866280-4866344. Regarding the second predicted gene, it contained five exons and had a SECIS element is located between positions 13130-13194 in the forward strand. In both cases the protein predicted with Seblastian was SelU1. In conclusion, Pseudonaja textilis' genome has a SelU1 duplication, both proteins being selenoproteins.
- Sel U2 -
SelU2 is a Cys-containing homolog and its function is unknown[18].
SelU2 was found in one scaffold, ULFR01000024.1. The predicted gene was located between positions 11437471-11440572 in the forward strand, comprising five exons. In the T-Coffee output, Cys located in P.textilis’ genome was aligned with Cys from the human sequence; however, the prediction did not start with Met due to a gap in P.textilis’ scaffold at the beginning of the alignment. Despite this fact, the alignment was good. In this case, neither SECIS elements nor selenoprotein were predicted by Seblastian. Therefore, it is concluded that SelU2 is found in the Pseudonaja textilis' genome as a cysteine-containing homologue.
- Sel U3 -
SelU3 is a Cys-containing homologue and its function is unknown[18].
Sel U3 was not found in Pseudonaja textilis by using a homology-based approach.
Selenoprotein V
SelV is a recently evolved selenoprotein which is found only in placental mammals. It emerged most likely by duplication from SelW. In contrast to SelW, it is expressed exclusively in the in testes, and thus may be involved in reproduction, but its specific function is not known[18].
SelV was not found in Pseudonaja textilis genome, as it aroused at the root of placental mammals.
Selenoprotein W
- Sel W1 -
SelW1 is a thioredoxin-like small selenoprotein located in the cytosol and highly expressed in the muscles and brain. However, its specific function remains unknown[12, 32].
SelW1 was found in one scaffold, ULFR01000078.1. The predicted gene was located between positions 2133506-2133577 in the forward strand, containing three exons. In the T-Coffee output, some gaps where located at the beginning of Pseudonaja textilis’ genome; in consequence, Sec-containing region for the scaffold was missing, and the prediction did not start with Met. Interestingly, an additional (not aligned) Sec was found in Pseudonaja textilis genome. Regarding SECIS element prediction, one candidate was found in the forward strand and 3’ UTR region between positions 2135271-2135359. Also, Seblastian predicted SelW. Therefore, it was concluded that SelW1 is found in this reptile genome as a selenoprotein.
- Sel W2 -
SelW2 is a Cys-containing homologue and its function is unknown [18].
SelW2 was found in one scaffold, ULFR01000096.1. The predicted gene was located between positions 1698998-1700770 in the reverse strand, comprising three exons. In the T-Coffee output, Cys was aligned with Cys residue from the human sequence; however, the prediction did not start with Met because some gaps were found at the beginning of the alignment. Regarding SECIS prediction, one candidate element was found in the reverse strand and 3’ UTR region between positions 1689371-1689442. In this case, no known selenoproteins were predicted by Seblastian. Nevertheless, we can conclude that SelW2 is found in the Pseudonaja textilis’ genome as a cysteine-containing homologue.
Methionine sulfoxide reductase A
Methionine sulfoxide reductases (Msrs) are thiol-dependent enzymes which catalyze conversion of methionine sulfoxide to methionine[33]. There are three known Msr: MsrA, MsrB, and fRMsr[33]. In this study, MsrB are annotated as SelR, the same way they appear in SelenoDB 1.0. These proteins, as their name indicates, are responsible for the reduction of methionine-sulfoxide residues. Specifically, MrsA is in charge of reducing residues with R conformation[33].
In the human case, MrsA is a cysteine-containing homologue. In Pseudonaja textilis two scaffolds were associated with this protein: ULFR01000020.1 and ULFR01000081.1. The predicted genes were located between 4237109-4267287 in the positive strand and between 1606490-1726958 in the negative strand, respectively. As the positions are not similar nor overlapping, it is deduced that a MrsA duplication might have occurred in this genome. In the T-Coffee output both sequences presented some gaps in the beginning of the alignment, so the presence of an initial Met was uncertain, but despite this fact, it was a good quality alignment and Cys residues from human sequence were aligned with Cys from Pseudonaja textilis. Due to the fact that no Sec was found in P.textilis genome nor SECIS elements were located in 3’ UTR region, it can be concluded that MrsA was duplicated in this species and both protein are cysteine-containing homologues.
Thioredoxin reductases
Thioredoxin reductase (TR) enzymes are important selenoproteins that, together with thioredoxin (Trx) and additional Trx-dependent enzymes, carry out several antioxidant and redox regulatory roles in cells, such as reduction of peroxides and regulation of several transcription factors involved in these processes. In mammalians, the three enzymes that belong to this family have a Sec in their catalytic site[34].
In order to facilitate the study of this family, a phylogenetic tree was performed using the amino acids sequences obtained during the alignment analysis and the human sequences of the proteins predicted for P. textilis.
- TR1 -
Three scaffolds (TR2_a, TR1_a, TR3_a) were associated to TR1. Considering the fact that all of them occupy similar positions, these cannot be not duplications, and only one scaffold was considered correct. TR1_a had the largest sequence and the best alignment with the human TR1. Only one Sec was found in the gene coding for this protein in both species, and the two sequences were aligned at this point. However, despite this good alignment, there were some gaps at the beginning of P.textilis’ sequence; hence it is not possible to know for sure if the predicted TR1 protein starts with Met or not. Another sequentiation would be helpful to clarify if this fragment starts with Met, another amino acid or if there is a real gap. To conclude, TR1 was found in Pseudonaja textilis’ genome, in the forward strand between position 16000451-16024075 and it consists of thirteen exons and one SECIS in 3’UTR region, specifically between positions 16024303-16024379. Protein predicted by Seblastian was consistent with these results.
- TR2 -
TR2 seems to be closely related to only one sequence found in the scaffold TR2_c. The potential TR2 sequence obtained from Pseudonaja textilis’ genome had an optim alignment with the human query. However, there were some gaps at the beginning of the alignment and at the end of the Pseudonaja textilis’ predicted protein sequence. Therefore, it’s uncertain whether this sequence starts with a Met as the human one does. Moreover, one of these gaps coincides with the expected aligned region containing the Sec that would match the one from the human TR2. Hence, it would be necessary to repeat the sequencing of this fragment with better tools to get to know if these gaps occur for real in Pseudonaja textilis’ genome or if they appear in the analysis because of an incorrect sequentiation. A part from this dubious Sec, another Sec was detected in this protein of the Pseudonaja textilis’ proteome but not in the human’s one. Considering all this information, it can be concluded that TR2 is found in the Pseudonaja textilis’ genome, it contains eleven exon and it is located in the positive strand between positions 3089808-3108823. Its SECIS is located between positions 3113947-3114027. It’s not possible to compare these results with Seblastian because no prediction was found.
- TR3 -
TR3 was associated with three scaffolds (TR1_b, TR2_b, TR3_b), all of them having similar location coordinates, so no duplications are expected. The best T-Coffee alignment is the one performed with TR3_b, because it presents the largest sequence annotated aligned. However, two regions of gaps were found at the initial and final parts of the protein alignment. One of these gaps coincides with the region of P.textilis’ genome expected to contain the Sec that would align with the human’s sequence; therefore, it is not possible to determine if in this position the P.textilis’ genome has a Sec, another amino acid or a real gap. Moreover, the first residue of the predicted protein is also missing, so it is unclear whether the protein starts with a Met or not. Further studies should be performed to investigate how many Sec are contained in this protein and to clarify the initial amino acid. Apart from this, it is worth mentioning that one Sec was found in the middle region of P.textilis’ protein predicted sequence that was lacking in human’s query. Therefore, TR3 is found in the Pseudonaja textilis’ genome in the reverse strand between positions 21578407-21603562 and contains fourteen exons. Three possible SECIS were predicted, but only one of these three is found in the 3’ UTR region, specifically between position 21578116 -21578189. Seblastian did not do any protein prediction in this case, regardless these results.
In conclusion, these results suggest that all TR are present in the eastern brown snake’s genome and that they all have at least one Sec in the protein sequence. In the case of TR2 and TR3, the Sec located at the human sequences were aligned with gap regions, so it is possible that P.textilis has two Secs in these proteins (not just one as the human query). More studies should be done to know the exact number of Sec amino acids and their positions in the snake's scaffolds.
Machinery selenoproteins
- SECp43 -
SECp43 is a machinery protein related to the synthesis of selenoproteins. Essentially, it enhances selenoprotein expression and regulates shuttling of the SecS‐selenocysteyl‐tRNA[Ser]Sec complex between the nucleus and cytoplasm[5].
SECp43 was found in one scaffold, ULFR01000020.1. The predicted gene was located between positions 4009210-4020733 in the forward strand, containing nine exons. In the T-Coffee output, Pseudonaja textilis’ sequence was perfectly aligned with the human query, and the prediction started with Met. Regarding SECIS prediction, no candidate element was found at the forward strand 3’ UTR region. Therefore, it was concluded that SECp43 is found in Pseudonaja textilis' genome.
- SECIS binding protein 2 (SBP2) -
SECIS binding protein 2 is a machinery protein related to the synthesis of selenoproteins. It binds to the SECIS element, preventing the reading of the UGA codon as a stop codon. Also, it recruits the eEFSec-selenocysteyl-tRNA[Ser]Sec complex to the ribosome[35, 36].
SBP2 was found in one scaffold, ULFR01000024.1. The predicted gene was located between positions 13856600-13875203 in the forward strand, containing eight exons. In the T-Coffee output, around the first half part of the sequence was gapped in Pseudonaja textilis’ genome. The same happened with the last few amino acids of the sequence. Nevertheless, the obtained alignment was quite good. Regarding SECIS prediction, no candidate element was found at the forward strand 3’ UTR region, but as this protein is part of the selenoprotein family because of its role as a machinery enzyme, but does not contain a Sec, this is not surprising. Therefore, it was concluded that SBP2 is found in Pseudonaja textilis' genome as a cysteine-containing homologue.
- O-phosphoseryl-tRNA(Sec) kinase (PSTK) -
PSTK is machinery protein related to the synthesis of selenoproteins. In particular, it is a kinase that phosphorylates the seryl-tRNA[Ser]Sec complex so that it can serve as a substrate for the SecS[37].
PSTK was found in one scaffold, ULFR01000026.1. The predicted gene was located between positions 12080798-12086332 in the forward strand, containing four exons. In the T-Coffee output, first and last parts of the sequence were missing in the Pseudonaja textilis' genome, which could be explained due to bad annotation of the sequence. Despite this, the alignment between both sequences was good. Regarding SECIS prediction, no candidate element was found at the forward strand 3’ UTR region, which is not surprising, as this machinery protein does not contain Sec itself. Therefore, it was concluded that PSTK is found in Pseudonaja textilis' genome as a cysteine-containing homologue.
- Sec synthase (SecS) -
Sec synthase is a machinery protein related to the synthesis of selenoproteins. Specifically, it is a pyridoxal phosphate‐dependent enzyme that dephosphorylates O‐phosphoseryl tRNA[Ser]Sec and transfers monoselenophosphate onto the tRNA to form Sec‐tRNA[Ser]Sec[5].
SecS was found in one scaffold, ULFR01000013.1. The predicted gene was located between positions 13856600-13875203 in the reverse strand, containing eleven exons. In the T-Coffee output, the alignment was perfect and it did start with Met. Only a few last amino acids were missing in the Pseudonaja textilis' genome. Regarding SECIS prediction, no candidate element was found at the forward strand 3’ UTR region; SEICS element is not needed because this machinery protein does not contain Sec. Therefore, it was concluded that SecS is found in Pseudonaja textilis' genome as a cysteine-containing homologue.
- Selenophosphate synthetase 1 (SPS1) -
Selenophosphate synthetase 1 is a SPS2 paralog, which may be indirectly related to the synthesis of selenoproteins through a different Sec utilization pathway; however, its exact function is not known[38].
SPS1 was found in two scaffolds: ULFR01000053.1 and ULFR01000059.1. The predicted gene was located between positions 2571818-2578056 and 5153327-5162647, respectively. As the positions are not similar at all, this could be explained as a duplication of SPS1 in Pseudonaja textilis' genome. However, no literature was found to confirm this hypothesis. Among these sequences, the best T-Coffee alignment corresponded to the second scaffold, which showed a perfect match and sequence started with Met. More precisely, the first scaffold found matched SPS2 (as indicated in the following section), where a Sec from the snake's genome was aligned with the Sec located in the human sequence. Thus, it was concluded that SPS1 was found in Pseudonaja textilis' genome between positions 5153327-5162647 in the reverse strand, containing eight exons. About SECIS prediction, one candidate element was found in the reverse strand and 3’ UTR region between positions 5108853-5108928, but probably this is due to a confusion, as the program might have considered the sequence that belongs to SPS2 because of their similarity. Considering all the information above, it was concluded that SPS1 is found in Pseudonaja textilis'.
- Selenophosphate synthetase 2 (SPS2) -
Selenophosphate synthetase 2 is a machinery protein related to the synthesis of selenoproteins. Interestingly, it is in itself a Sec-containing protein, and it is involved in the synthesis of selenophosphate, which is required in order to obtain a Sec-tRNA [38].
SPS2 was found in the same two previous scaffolds: ULFR01000053.1 and ULFR01000059.1. The predicted gene was located between positions 2571809-2578056 and 5153351-5162629, respectively. However, in the T-Coffee output, a Sec from the predicted protein was aligned with the Sec from the human protein sequence in the first case but not in the second. Also, both T-Coffee outputs showed a few amino acids missing in the same part of the Pseudonaja textilis' sequence, but the alignment at the beginning of the sequence was better in the first case. Thus, SPS2 was found in Pseudonaja textilis' genome between positions 2571809-2578056 in the forward strand, consisting of eight exons. Regarding SECIS prediction, one candidate element was found in the forward strand and 3’ UTR region between positions 2578428-2578502. What is more, Seblastian predicted selenide water dikinase 2 isoform X2. Therefore, it was concluded that SPS2 is found in Pseudonaja textilis' genome as a selenoprotein.
- Selenocysteine Eukaryotic elongation factor (eEFSec) -
Eukaryotic elongation factor is a machinery protein related to the synthesis of selenoproteins. It plays a key role in the elongation during the translation process. Specifically, it guides the Sec-tRNA to the UGA codon and allows its translation into a Sec [5].
eEFSec was found in one scaffold, ULFR01000004.1. The predicted gene was located between positions 24154157-24327532 in the positive strand, containing eight exons. In the T-Coffee output, no Sec was found, and even though the quality of the alignment was almost perfect, the first three amino acids were missing in Pseudonaja textilis' genome, so the prediction did not start with a Met. About SECIS prediction, one element was found in the forward strand downstream at the 3’ UTR region between positions 24294823-24294903, but it was ruled out. In this case, no proteins were predicted by Seblastian. Considering all the information above, it was concluded that eEFSec is found in Pseudonaja textilis' genome.
Conclusions
After performing and discussing all the bioinformatic analysis, taking into account the 41 reference sequences from the human genome that belonged to the selenoprotein family, several proteins from this family were found out in the genome of Pseudonaja textilis. To facilitate the comprehension of the obtained reptile selenoprotome, a table was created with all the final results (Fig 50). It is important to highlight that three protein duplications were observed: SelT, SelU1 and MrsA. However, in the case of SelT it is not clear if the duplicated protein is a Cys-containing homologue or a selenoprotein. Curiously, one of these duplications, SelU1, contains a Sec residue, in contrast to the human genome, which contains a Cys residue.
On the other hand, four proteins were missing: GPx5, GPx6, SelU3 and SelV. The rest of the proteins were homologous to those annotated in the human genome. In total, 40 proteins were found, 20 of which were Sec-containing selenoproteins and 12 were Cys-containing homologues. It is important to take into account that 3 proteins (SelH, SelK, SelM) showed a gap aligned with the Sec residue from the human sequence and no other Sec residues; nevertheless, they were considered to be selenoproteins since they presented a SECIS element in 3’UTR region. Also, 2 proteins (SelS, SelT) showed a Sec residue in their sequences although no SECIS elements in 3’UTR region could be found. Likewise, these may be considered selenoproteins as well. Finally, 3 (SBP2, SPS1, eEFSec) machinery proteins carrying other amino acids other than Sec or Cys were identified.
To reach these conclusions, many aspects were taken into account, even though there were some limitations in the process such as certain mismatches in the alignments, especially those involving Met as the first amino acid, which was sometimes missing in the P.textilis candidate selenoproteins. Another limitation was that in some cases, such as SelH, SelM, SelP and SelR2, the quality of the alignment was not good enough (Fig 50). However, using the human genome as reference was an advantage, as it is a SelenoDB 1.0 model phylogenetically close to this snake species and also the best studied genome. As a matter of fact, some alignment discordances could have occured due to an imperfect annotation of the Pseudonaja textilis genome.
Considering the exhaustivity of these analyses, and despite the possible inaccuracies of some alignments, it is plausible to affirm that these results are better than those predicted automatically by the program Seblastian, as many facts and data were taken into account and perhaps the proteins predicted here should be included in this tool. However, it would be worthwhile to conduct further studies to analyse those lacking points and uncertainties present in these results in order to obtain better understanding of the role of selenoproteine families in the species P.textilis.
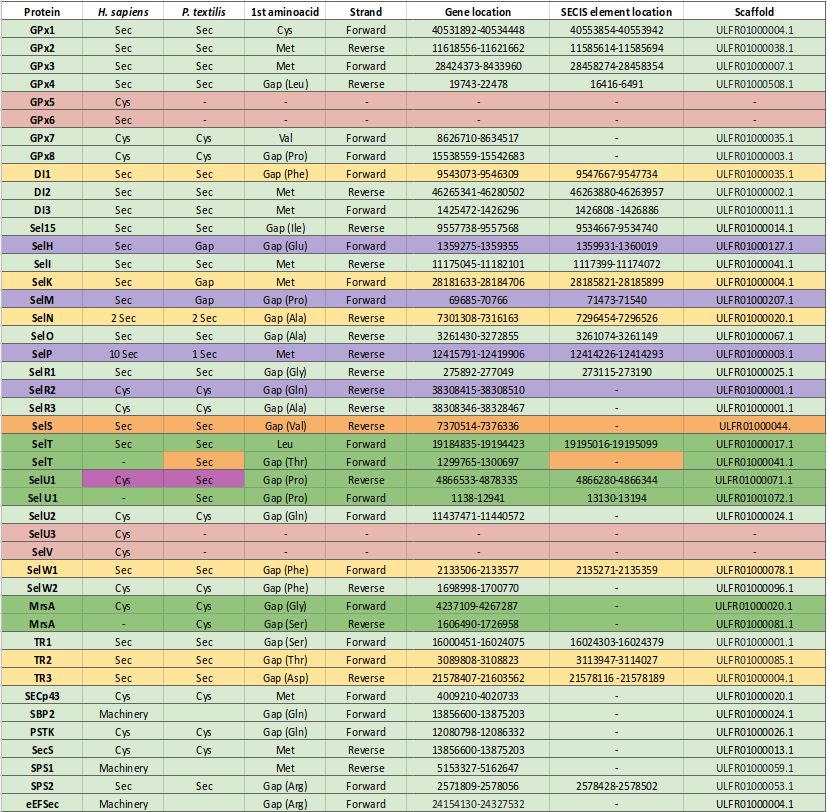
This project has definitely helped us, the authors, to familiarize ourselves with the bioinformatic analyses and the computational tools. We have been able to practice teamwork, coordination and interpretation of results from a critical point of view, considering the big amount of data obtained and regardless the problems we found during the process. We are proud to say that we have learnt a lot and we have contemplated a new horizon in the field of biology.
References
1. Byun, B. J.; Kang, Y. K. (2011). Conformational Preferences and pKa Value of Selenocysteine Residue. Biopolymers. 95 (5): 345–353.
2. Lu J, Holmgren A. Selenoproteins. Journal of Biological Chemistry. 2008;284(2):723-727.
3. Mariotti M, Lobanov A, Manta B, Santesmasses D, Bofill A, Guigó R, Gabaldón T, Gladyshev V. Lokiarchaeota Marks the Transition between the Archaeal and Eukaryotic Selenocysteine Encoding Systems. Mol Biol Evol. 2016; 33(9): 2441–2453.
4. Turanov AA, Xu XM et al. Biosynthesis of selenocysteine, the 21st amino acid in the genetic code, and a novel pathway for cysteine biosynthesis. Adv Nutr. 2011; 2(2): 122-128.
5. Squires J, Berry M. Eukaryotic selenoprotein synthesis: Mechanistic insight incorporating new factors and new functions for old factors. IUBMB Life. 2008;60(4):232-235.
6. Reeves M, Hoffmann P. The human selenoproteome: recent insights into functions and regulation. CMLS. 2009;66(15):2457-2478.
7. Kryukov GV, Castellano S, Novoselov SV, Lobanov AV, Zehtab O, Guigo R, Gladyshev VN. Characterization of mammalian selenoproteomes. Science. 2003;300:1439–1443.
8. Mariotti M, Ridge P, Zhang Y, Lobanov A, Pringle T, Guigo R et al. Composition and Evolution of the Vertebrate and Mammalian Selenoproteomes. PLoS ONE. 2012;7(3):e33066.
9. Lobanov A, Hatfield D, Gladyshev V. Eukaryotic selenoproteins and selenoproteomes. Biochim Biophys Acta Gen Subj. 2009;1790(11):1424-1428.
10. Lobanov A, Fomenko D, Zhang Y, Sengupta A, Hatfield D, Gladyshev V. Evolutionary dynamics of eukaryotic selenoproteomes: large selenoproteomes may associate with aquatic life and small with terrestrial life. Genome Biol. 2007;8(9):R198.
11. Lobanov A, Hatfield D, Gladyshev V. Reduced reliance on the trace element selenium during evolution of mammals. Genome Biol. 2008;9(3):R62.
12. Labunskyy, V., Hatfield, D. and Gladyshev, V. (2014). Selenoproteins: Molecular Pathways and Physiological Roles. Physiological Reviews, 94(3), pp.739-777.
13. Bhabak KP, Mugesh G. Functional mimics of glutathione peroxidase: Bioinspired synthetic antioxidants. Acc Chem Res. 2010;43(11):1408-19.
14. Mariotti M, Lobanov A V, Guigo R, Gladyshev VN. SECISearch3 and Seblastian: new tools for prediction of SECIS elements and selenoproteins. Nucleic Acids Res. 2013;41(15):e149.
15. Bianco AC, Salvatore D, Gereben B, Berry MJ, Larsen PR. Biochemistry, cellular and molecular biology, and physiological roles of the iodothyronine selenodeiodinases. Endocr Rev. 2002;23:38–89.
16. St Germain DL, Galton VA, Hernandez A. Minireview: Defining the roles of the iodothyronine deiodinases: current concepts and challenges. Endocrinology. 2009;150(3):1097-107.
17. Labunskyy V, Hatfield D, Gladyshev V. The Sel15 protein family: Roles in disulfide bond formation and quality control in the endoplasmic reticulum. IUBMB Life. 2007;59(1):1-5.
18. Mariotti M, Ridge P, Zhang Y, Lobanov A, Pringle T, Guigo R et al. Composition and Evolution of the Vertebrate and Mammalian Selenoproteomes. PLoS ONE. 2012;7(3):e33066.
19. Hatfield DL, Schweizer U, Tsuji PA, Gladyshev VN. Selenium: Its Molecular Biology and Role in Human Health. Switzerland; Springer:2012.
20. Reeves M, Bellinger F, Berry M. The Neuroprotective Functions of Selenoprotein M and its Role in Cytosolic Calcium Regulation. Antioxid Redox Signal. 2010;12(7):809-818.
21. Castets P, Lescure A, Guicheney P, Allamand V. Selenoprotein N in skeletal muscle: from diseases to function. J Mol Med. 2012;90(10):1095-1107.
22. Han S, Lee B, Yim S, Gladyshev V, Lee S. Characterization of Mammalian Selenoprotein O: A Redox-Active Mitochondrial Protein. PLoS ONE. 2014;9(4):e95518.
23. Burk R, Hill K. SELENOPROTEIN P: An Extracellular Protein with Unique Physical Characteristics and a Role in Selenium Homeostasis. Annu Rev Nutr. 2005;25(1):215-235.
24. Wrobel J, Power R, Toborek M. Biological activity of selenium: Revisited. IUBMB Life. 2015;68(2):97-105.
25. Lee B, Lee S, Choo M, Kim J, Lee H, Kim S et al. Selenoprotein MsrB1 promotes anti-inflammatory cytokine gene expression in macrophages and controls immune response in vivo. Sci Rep. 2017;7(1).
26. Kim H, Gladyshev V. Methionine Sulfoxide Reduction in Mammals: Characterization of Methionine-R-Sulfoxide Reductases. Mol Biol Cell. 2004;15(3):1055-1064.
27. Lee BC, Dikiy A, Kim HY, Gladyshev VN. Functions and Evolution of Selenoprotein Methionine sulfoxide reductase s. Biochim Biophys Acta. 2009;1790(11):1471-1477.
28. Dikiy A, Novoselov SV, Fomenko DE, Sengupta A, Carlson BA, Cerny RL, Ginalski K, Grishin NV, Hatfield DL, Gladyshev VN.SelT, SelW, SelH, and Rdx12: genomics and molecular insights into the functions of selenoproteins of a novel thioredoxin-like family.Biochemistry 46:6871-6882, 2007.
29. Boukhzar L, Hamieh A, Cartier D, Tanguy Y, Alsharif I, Castex M, et al. Selenoprotein T Exerts an Essential Oxidoreductase Activity That Protects Dopaminergic Neurons in Mouse Models of Parkinson’s Disease. Antioxid Redox Signal. April 2016;24(11):557-74.
30. Jiang Y, Huang J, Lin G, Guo H, Ren F, Zhang H. Characterization and Expression of Chicken Selenoprotein U. Biol Trace Elem Res. 2015;166(2):216-224.
31. Sattar H, Yang J, Zhao X, Cai J, Liu Q, Ishfaq M et al. Selenoprotein-U (SelU) knockdown triggers autophagy through PI3K–Akt–mTOR pathway inhibition in rooster Sertoli cells. Metallomics. 2018;10(7):929-940.
32. Whanger P. Selenoprotein expression and function—Selenoprotein W. Biochim Biophys Acta. 2009;1790(11):1448-1452.
33. Lee BC, Dikiy A, Kim HY, Vadim NG. Functions and Evolution of Selenoprotein Methionine Sulfoxide Reductases. Biochim Biophys Acta. 2009; 1790(11): 1471–1477.
34. Gromer S, Johansson L, Bauer H, Arscott D, Rauch S, David P, et al. Active sites of thioredoxin reductases: Why selenoproteins?. PNAS. 2003;100(22):12618-12623.
35. Low S. SECIS-SBP2 interactions dictate selenocysteine incorporation efficiency and selenoprotein hierarchy. EMBO J. 2000;19(24):6882-6890.
36. Tujebajeva RM, Copeland PR, Xu XM, Carlson BA, Harney JW, Driscoll DM, et al. Decoding apparatus for eukaryotic selenocysteine incorporation. EMBO. 2000;2:158–163.
37. Carlson BA, Xu XM, Kryukov GV, Rao M, Berry MJ, Gladyshev VN, et al. Identification and characterization of phosphoseyl-tRNA[Ser]Sec kinase. Proc Natl Acad Sci U S A. 2004;101(35):12848-53.
38. Lobanov A, Hatfield D, Gladyshev V. Selenoproteinless animals: Selenophosphate synthetase SPS1 functions in a pathway unrelated to selenocysteine biosynthesis. Protein Sci. 2007;17(1):176-182.
About us
We are four 4th-grade Human Biology students from University Pompeu Fabra (Barcelona). This project is part of the Bioinformatics course carried out from September until December 2018. Please feel free to contact us for doubts or questions about our work.



We would like to thank our tutors for the help provided both presentially and non-presentially. We would also like to express our gratitude to Georg Wild for being our html-mentor in the process of creating this website.
