E.dispar
La maquinaria de transcripcion en Entamoeba dispar
Elementos Secis de E.dispar
El output inicial de SECISearch 2.1 fue de 15 posibles elementos SECIS de los cuales 6 los pudimos descartar por tener una estructura secundaria que no se corresponde con la que se considera prototípica de un elemento SECIS. Con los 9 elementos restantes se procedió tal y como se ha detallado en materiales y métodos. Finalmente no se ha obtenido ningún posible elemento SECIS que esté asociado, ya sea a alguna selenoproteína u homóloga con cisteína, en ninguno de los organismos de la base de datos de NCBI. Pudiera ser que alguno de los hits obtenidos se correspondiera con alguna posible selenoproteína no descrita hasta el momento. Un resultado que explicara que hay indicios de que uno de los posibles elementos SECIS obtenidos constituya como tal y participe en la síntesis de una nueva selenoproteína no descrita hasta ahora sería que el alineamiento del blastx estuviera próximo y en posición 3’ de un codón de terminación TGA. Como se sabe, muchas de las proteínas de E. dispar presentes en la base de datos de NCBI se han obtenido mediante complejos algorismos informáticos. Estos programas no han tenido en cuenta que, en una serie de casos muy concretos, el codón TGA no ejerce su función mayoritariamente atribuida de parar la traducción y pudiera ser que se hubiera predicho erróneamente que alguna de esas proteínas termina en un codón TGA cuando en realidad, se trata de una selenoproteína y su traducción continua. Sin embargo, esta hipótesis no se ha podido aceptar en ninguno de los casos. Los motivos por los que se ha optado descartarlos se describen a continuación.
Codón de terminación diferente a TGA:
En muchos de los casos analizados, el codón de terminación de la proteína asociada no ha sido TGA, requisito indispensable para que una posible secuencia SECIS pueda ser considerada como tal, ya que, hasta el momento, es el único codón que codifica para selenocisteína. Así, se han podido descartar la mayoría de nuestras secuencias candidatas:
| SECIS | Proteína asociada | ||
|---|---|---|---|
| Referencia NCBI | Nombre | E-value | |
| SECIS 2 | ref|XP_001733812.1| | hypothetical protein [Entamoeba dispar SAW760] | 2e-73 |
| ref|XP_001733261.1| | hypothetical protein [Entamoeba dispar SAW760] | 2e-73 | |
| ref|XP_001738254.1| | hypothetical protein [Entamoeba dispar SAW760] | 2e-73 | |
{kind=link}
| SECIS | Proteína asociada | ||
|---|---|---|---|
| Referencia NCBI | Nombre | E-value | |
| SECIS 4 | ref|XP_001733812.1| | hypothetical protein [Entamoeba dispar SAW760] | 9e-129 |
| ref|XP_001733261.1| | hypothetical protein [Entamoeba dispar SAW760] | 2e-128 | |
{kind=link}
| SECIS | Proteína asociada | ||
|---|---|---|---|
| Referencia NCBI | Nombre | E-value | |
| SECIS 5 | ref|XP_656795.1| | phosphoribulokinase /uridine kinase family protein [Entamoeba histolytica HM-1:IMSS] | 4e-155 |
| ref|YP_001741365.1| | Uridine kinase [Candidatus Cloacomonas acidaminovorans] | 1e-29 | |
| ref|NP_347309.1 | Fision threonyl-tRNA synthetase (N-terminal part) and uridine kinase [Clostridium acetobutylicum ATCC 824] | 1e-28 | |
{kind=link}
| SECIS | Proteína asociada | ||
|---|---|---|---|
| Referencia NCBI | Nombre | E-value | |
| SECIS 6 | ref|XP_001740496.1| | myosin light chain kinase [Entamoeba dispar] | 0,0 |
| ref|XP_652996.1| | protein kinase domain containing protein [Entamoeba histolytica HM-1:IMSS] | 0,0 | |
| ref|XP_650081.1| | protein kinase domain containing protein [Entamoeba histolytica HM-1:IMSS] | 1e-62 | |
| ref|XP_650940.1| | protein kinase domain containing protein [Entamoeba histolytica HM-1:IMSS] | 1e-62 | |
| ref|XP_001736905.1| | hypothetical protein [Entamoeba dispar SAW760] | 1e-62 | |
{kind=link}
| SECIS | Proteína asociada | ||
|---|---|---|---|
| Referencia NCBI | Nombre | E-value | |
| SECIS 7 | ref|XP_001736478.1| | hypothetical protein [Entamoeba dispar SAW760] | 9e-80 |
| ref|XP_650667.1| | hypothetical protein [Entamoeba histolytica HM-1:IMSS] | 2e-73 | |
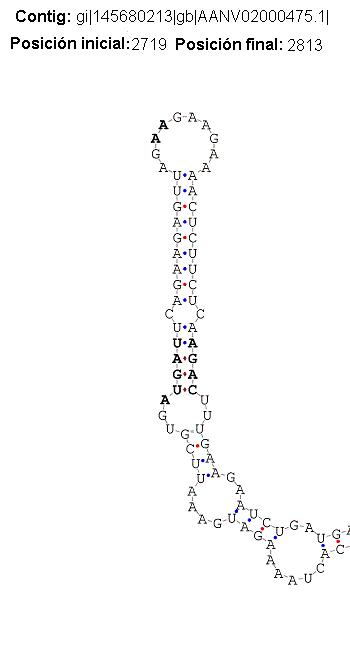{kind=link}
| SECIS | Proteína asociada | ||
|---|---|---|---|
| Referencia NCBI | Nombre | E-value | |
| SECIS 9 | ref|XP_001734179.1| | hypothetical protein [Entamoeba dispar SAW760] | 1e-180 |
| ref|XP_651769.2| | hypothetical protein [Entamoeba histolytica HM-1:IMSS] | 4e-171 | Imágenes|
| ref|XP_001738113.1| | hypothetical protein [Entamoeba histolytica HM-1:IMSS] | 4e-102 | |
| ref|XP_001740257.1| | hypothetical protein [Entamoeba dispar SAW760] | 1e-100 | |
| ref|XP_656600.1| | hypothetical protein [Entamoeba histolytica HM-1:IMSS] | 2e-100 | |
| ref|XP_650744.1| | hypothetical protein [Entamoeba histolytica HM-1:IMSS] | 4e-99 | |
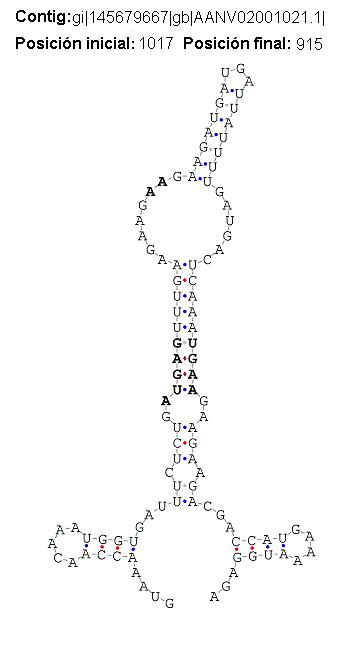{kind=link}
Asociación con proteínas extensamente estudiadas
Otro motivo que ha permitido descartar una de nuestras posibles secuencias SECIS es que, a la hora de hacer un blastx con la base de datos de NCBI, se obtenga como resultado proteínas que, por estar presentes en muchos tipos de organismos diferentes –y por tanto importantes para la vida -, se han estudiado extensamente y se sabe con certeza, no son selenoproteínas.
En nuestro caso se ha hallado una asociación con la proteína actina, proteína de indiscutible ubicuidad en gran parte de organismos. Presentamos a continuación la tabla resumen:
| SECIS | Proteína asociada | ||
|---|---|---|---|
| Referencia NCBI | Nombre | E-value | |
| SECIS 8 | ref|XP_001736572.1| | actin [Entamoeba dispar SAW760] | 0,0 |
| ref|XP_657320.2| | actin [Entamoeba histolytica HM-1:IMSS] | 0,0 | |
{kind=link}
Secuencia SECIS alineada en posición 5’ del codón TGA de terminación.
En este caso, se han podido descartar distintos elementos SECIS porque los hits más significativos obtenidos en hacer el blastx encuentran homología entre nuestra posible secuencia SECIS y regiones upstream del codón de terminación de la proteína asociada. Una secuencia SECIS debe estar siempre situada por detrás del presunto codón que codificará para selenocisteína.
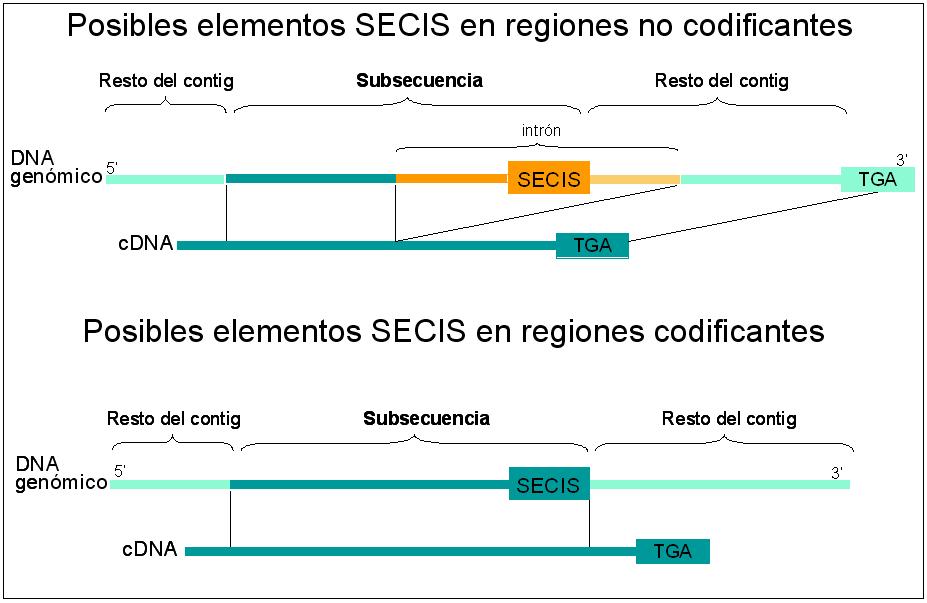
Se distinguen dos tipos de asociaciones en los que el codón TGA se encuentra por detrás (3’) del posible elemento SECIS:
Posibles elementos SECIS en regiones no codificantes
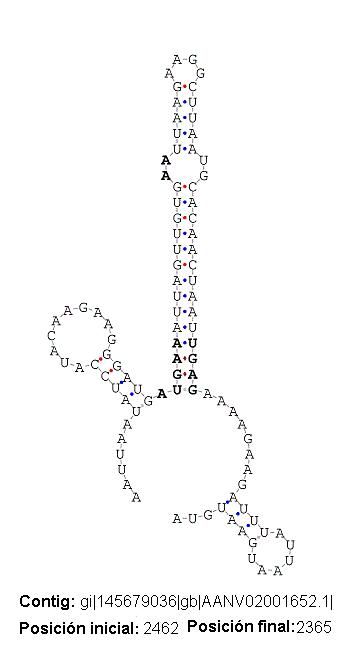
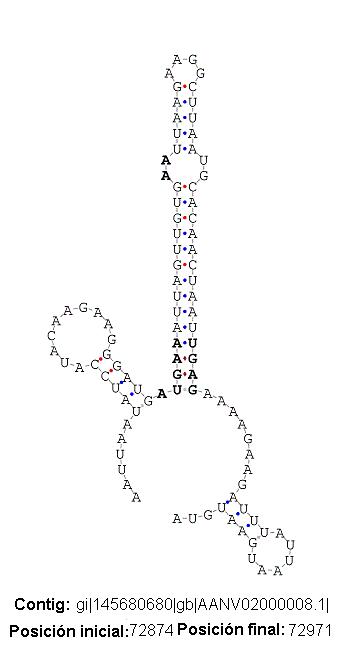
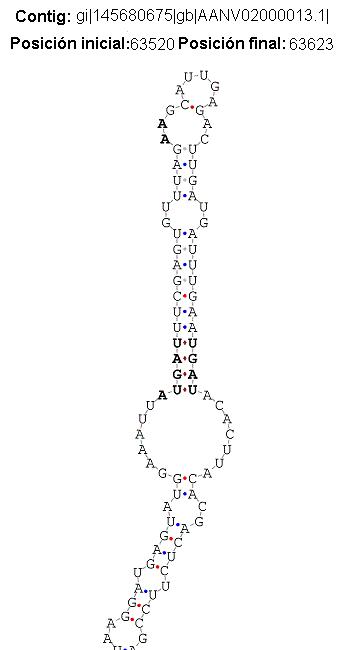
Se han registrado casos en los que sólo una porción de nuestra secuencia query se alinea con el cDNA de una proteína hit del genoma de E. dispar. Está porción de la subsecuencia está situada en una región immediatamente por encima (5’) de nuestra posible secuencia SECIS. El hecho de que la secuencia SECIS no aparezca en la secuencia cDNA de la proteína hit permite deducir que la región donde se encuentra el candidato a SECIS no se traduce posteriormente, se puede deducir que se encuentra en un intrón. E la secuencia SECIS no constituye como tal (veáse figura). Acontinuación se presenta una tabla con los resultados detallados:
| SECIS | Proteína asociada | ||
|---|---|---|---|
| Referencia NCBI | Nombre | E-value | |
| SECIS 3 | ref|XP_001736572.1 | Hypothetical protein [Entamoeba dispar SAW760] | 0,0 |
| ref|XP_657320.2| | TBC/Rab GTPase activating domain containing protein [Entamoeba histolytica HM-1:IMSS] | 0,0 | |
| ref|XP_649041.1| | Rab GTPase activating protein [Entamoeba histolytica HM-1:IMSS] | 7e-95 | |
| ref|XP_001741626.1| | hypothetical protein [Entamoeba dispar SAW760] | 3e-93 | |
{kind=link}
| SECIS | Proteína asociada | ||
|---|---|---|---|
| Referencia NCBI | Nombre | E-value | |
| SECIS 4 | ref|XP_001733261.1| | Hypothetical protein [Entamoeba dispar] | 1e-49 |
| SECIS | Proteína asociada | ||
|---|---|---|---|
| Referencia NCBI | Nombre | E-value | |
| SECIS 9 | ref|XP_654742.2| | hypothetical protein [Entamoeba histolytica HM-1:IMSS]] | 2e-22 |
Posibles elementos SECIS en regiones codificantes
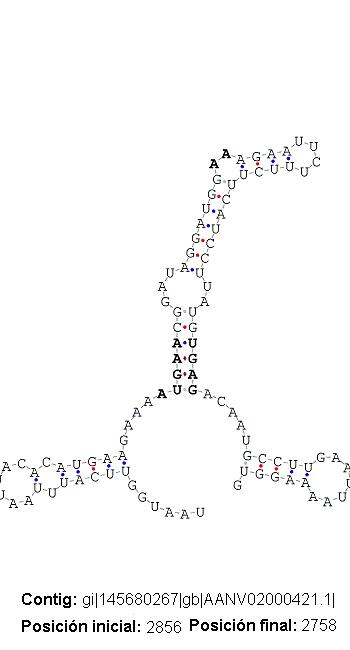
Por otro lado, se han registrado un caso en que el alineamiento con la proteína hit también incluye el posible elemento SECIS. Es decir la secuencia predicha por SECISearch codifica directamente para proteína y no ejerce, por tanto, como elemento SECIS (veáse figura). Los casos registrados son:
| SECIS | Proteína asociada | ||
|---|---|---|---|
| Referencia NCBI | Nombre | E-value | |
| SECIS 1 | ref|XP_001733812.1| | Hypothetical protein [Entamoeba dispar SAW760] | 6e-129 |
| rref|XP_001733261.1| | TBC/Rab GTPase activating domain containing protein [Entamoeba histolytica HM-1:IMSS] | 2e-128 | |
| ref|XP_001738254.1| | Rab GTPase activating protein [Entamoeba histolytica HM-1:IMSS] | 1e-49 | |
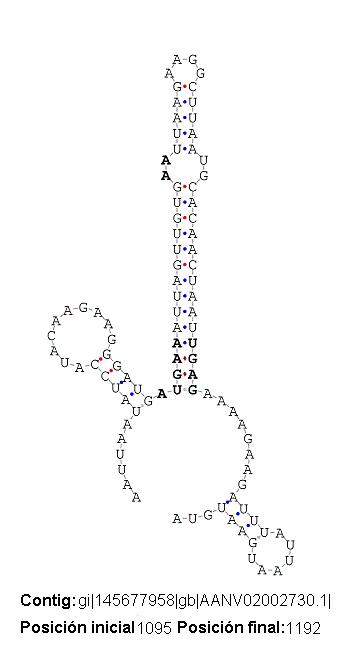{kind=link}



