Alineament ClustalW DI3
Ja per acabar, per comprovar definitivament que la proteïna trobada en Paramecium tetraurelia era una selenoproteïna, vam passar el scaffold tallat pel SECISearch. Aquest ens va mostrar la seqüè de l'element SECIS de la selenoproteïna DI.Cal dir però, que l'score del SECIS obtingut és de 13.7 i és inferior al valor que el programa considera òptim. Malgrat això, hem cregut que es complien tots els requisits com a selenoproteïna i a més després de la U hi havia una elevada conservació dels aminoàcids. Per tant, comfirmem la presència d'aquesta selenoproteïna en Paramecium tetraurelia
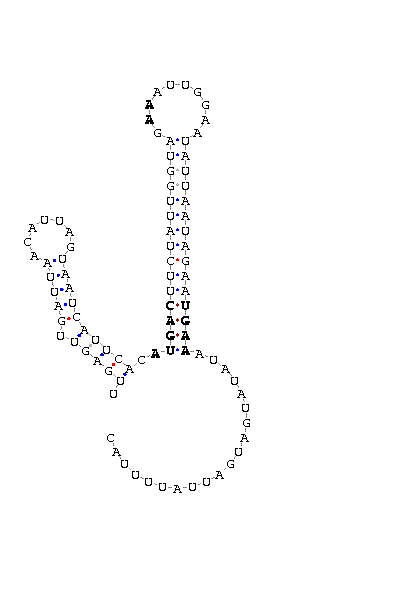
Thioredoxin reductase 1 (TR1)
La tioredoxina reductasa és una selenoproteïna important en la detoxificació del peròxid d'hidrogen. L'espècie humana presenta tres tipus de tioredoxines reductases diferents: TR1, TR2 i TR3. Totes elles presenten una selenocisteïna (U) en la seva seqüència d'aminoàcids. Quan vàrem alinear cadascuna d'elles amb el genoma de Paramecium tetraurelia mitjançant el tblastn del shell, aquesta selenocisteïna humana no va aparèixer en cap dels tres aliniaments realitzats:
tblastn TR1
tblastn TR2
tblastn TR3
Però havíem de fer alguna cosa. D'aquesta manera i com que la seqüència proteica de les tres tioredoxines reductases eren molt semblants, vàrem decidir seleccionar la TR1 humana per poder seguir treballant en aquesta part de projecte.
Observant els resultats obtinguts en el tblast corresponent a la TR1 humana contra el genoma de P. tetraurelia, vàrem agafar el scaffold_11 del nostre organisme perquè el seu alineament presentava un valor de e-value considerablement baix (de l'ordre de 2e-113). Tot seguit, vàrem extreure la regió d'aquest scaffold que tenia més homologia amb la TR1 humana i la vàrem guardar fent un $ emacs TR_scaffold_11_495300-498300.fa:
Fragment Scaffold 11 TR
El següent pas va ser fer anar el programa exonerate. Aquest programa ens va mostrar la seqüència d'aminoàcids predita per al nostre scaffold, així com també els codons que codificaven per a cadascun dels diferents aminoàcids. A més, en els resultats també apareixia la presència de tres exons amb els seus respectius inicis i finals teòrics. Diem teòrics perquè, tal i com ens va dir en Charles Chapple, sovint l'exonerate no mostra els exons sencers.
Exonerate TR
Així que vàrem buscar l'inici i el final teòric de cadascun dels tres exons en el TR_scaffold_11_495300-498300.fa a partir dels codons que ens mostrava l'exonerate. Però com hem comentat anteriorment, aquests exons no estaven sencers. Per aquesta raó, vàrem decidir ajuntar-los i fer un Nucleotideblast al NCBI per tal d'obtenir la seqüència potencial del seu respectiu RNAm.
Aquest RNAm només presentava els exons, de manera que això ens va ajudar moltíssim. Vàrem procedir aleshores a identificar els inicis i els finals reals de cadascun dels tres exons, així com les seqüències d'iniciació i de finalització de la traducció. El resultat que vàrem obtenir van ser els que es mostren en el següent link:
Seqüéncia completa de TR de Paramecium Tetraurelia
D'altra banda, també vàrem passar aquest scaffold_11 ja tallat pel programa informàtic SECISearch, el qual ens va mostrar la seqüència de l'element SECIS de la potencial selenoproteïna del nostre organisme P.tetraurelia. La seqüència marcada en fucsia del link anterior (Seqüéncia de nucleótids del RNAm) es correspon amb l'element SECIS. Per tant, vàrem deduir que el TGA del RNAm de la seqüència de finalització de la traducció no codificava realment per a un codó Stop, sinó que codificava per a la nostra esperadíssima selenocisteïna. De fet, el següent codó TGA que apareix en blau em el link és el veritable codó Stop de la nostra selenoproteïna TR en P. tetraurelia. En aquest mateix link tambè hi podem veure la seqüència de l'element SECIS en fucsia, la qual es troba aproximadament a unes 105 parells de bases d'aquest codó stop.
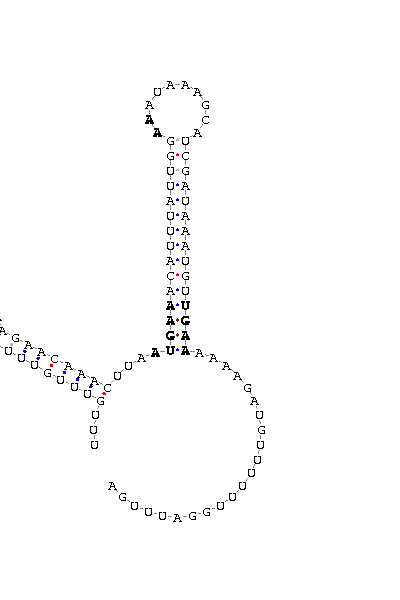
Però nosaltres volíem anar més enllà, volíem corroborar els nostres resultats. Per aquesta raó vàrem extreure els veritables introns, de manera que únicament ens vàrem quedar amb la seqüència de nucleòtids que contenia la seqüència d'inici del RNAm, els tres exons i la seqüència de finalització del RNAm. Aquesta seqüència la vàrem guardar fent un $ emacs TR_exons_final_RNAm.fa i la vàrem traduir a proteïna mitjançant la comanda $ fastatranslate TR_exons_final_RNAm.fa > TR_protein_exons_final_RNAm.fa
Possibles proteïnes de TR en P. tetraurelia
De totes les possibles proteïnes obtingudes, vàrem escollir aquella que començava per la metionina, ja que es tracta del primer aminoàcid que s'incorpora a les proteïnes.
Selenoproteïna TR real de Paramecium tetraurelia
Tot seguit vàrem accedir a la pàgina del NCBI i vàrem fer un tblastn d'aquesta seqüència proteica contra el genoma del nostre organisme P. tetraurelia. Els resultats varen ser significatius perquè l'aliniament tenia una valor d'e-value de l'ordre de 0,0 i un 96% d'identitat.
Blast final
Després, vàrem fer anar el ClustalW. Es tracta d'un programa que realitza aliniaments múltiples entre seqüències de DNA o de proteïnes. En el nostre cas vàrem fer servir la selenoproteïna TR del nostre organisme a estudiar i la TR humana. Els resultats que vàrem obtenir es mostren en el següent link:
Alineament ClustalW
Selenoprotein V
En aquest cas, el resultat obtingut amb el tblastn va ser molt interessant ja que la selenocisteïna (U) humana estava alineada amb un codó Stop (*) en P. tetraurelia, tot i tenir un valor de e-value considerablement elevat.
tblastn SelV
Per aquesta raó, vàrem considerar oportú anar al NCBI per tal de fer un tblastn del segment del scaffold (SelV_scaffold_135_215842-216093.fa) contra una seqüència de DNA ja traduïda, la qual dóna evidència de l'existència de l'expressió de dita proteïna en un determinat organisme. Aquesta seqüència de DNA rep el nom d'EST.
Fragment Scaffold 135 SelV
L'EST obtingut el vàrem copiar i guardar en un $ emacs SelV_EST.fa i tot seguit el vàrem traduir a proteïna mitjançant la comanda del shell $ fastatranslate SelV_EST.fa. Com a resultat vàrem tenir sis pautes de lectura diferents, però cap d'elles coincidia amb la seqüència d'aminoàcids que havíem obtingut en el primer alineament extret amb el tblastn del shell.
EST corresponent al fragment Scaffold 135
Les sis pautes de lectura del EST
Així doncs, vàrem haver de descartar la possibilitat de que aquesta selenoproteïna SelV existís en el nostre organisme P. tetraurelia per dues raons principals: primer, perquè el valor d'e-value era considerablement elevat; i segon, perquè cap de les sis possibles pautes de lectura del EST coincidien amb la proteïna alineada en el tblastn inicial.
RESULTATS HOMÒLOGUES EN Cys
Glutathione peroxidase 4 (GPx4)
Les glutathione peroxidase són una família d'enzims amb activitat peroxidasa que tenen com a paper principal protegir l'organisme de reaccions oxidatives.
Les GPX 1-4, 6 són selenoproteïnes humanes, en canvi, les GPX 5,7 i 8 són proteïnes que contenen cisteïna.
Primer de tot vam realitzar un tblastn per cada una de les GPXs humanes contra el genoma del Paramecium tetraurelia i vam observar el següent:
-
Les GPXs que en l'humà són selenoproteïnes, la U (selenocisteïna) de la proteïna humana se'ns alineava amb una cisteïna (C) amb un score força alt i un e-value molt baix en el scaffold 10 del genoma de Paramecium tetraurelia . Això significa que existeix homologia significativa entre la selenoproteïna humana i el scaffold 10 del genoma del nostre organisme. La GPx6 la vam descartar perquè no va trobar homologia.
blast GPx 1-4
Les GPXs que en l'humà contenen cisteïna (GPx 5,7 i 8), vam poder observar força homologia entre la selenoproteïna humana i un fragment del genoma de P. tetraurelia on la cisteïna de l'humà se'ns alinia amb una altra cisteïna del nostre organisme. Aquestes GPXs per tant, no les hem tingut en compte perquè ni en l'humà ni en Paramecium tetraurelia són selenoproteïnes.
tblastn GPx 5,7 i 8
Després de realitzar el blast per veure l'homologia i per observar si la U (selenocisteïna) de la proteïna humana se'ns alineava amb una U o C en el nostre organisme, vam seleccionar el scaffold que tenia un e-value més baix i un score més alt. Amb això, vam veure que l'scaffold més significatiu amb el qual les GPxs de la 1 a la 4 tenien més homologia era el número 10. En el blast vam veure també, que la U se'ns alineava amb una cisteïna del nostre organisme.
A continuació vam escollir la GPx4 perquè és la que tenia un e-value més baix en aquest scaffold i vam tallar un fragment d'aquesta regió amb la comanda fastasubseq.
Fragment Scaffold 10 GPx
Després d'obtenir aquest fragment més petit del scaffold 10, vam realitzar la comanda exonerate per obtenir la seqüència nucleotídica del gen. Al realitzar l'exonerate, no vam obtenir res i vam decidir trobar l'EST d'aquell fragment i tampoc el vam trobar. Com al blast havíem observat que al principi no hi havia homologia, vam enganxar els 39 aminoàcids que faltaven a la proteïna de Paramecium de la selenoproteïna humana.
Posteriorment, vam fer un exonerate amb aquesta proteïna i el fragment de scaffold 10 tallat, on obtenim com a resultat una proteïna amb dos exons i un intró.
Exonerate GPx4
A partir de la predicció de l'estructura de la proteïna, mitjançant el fastatranslate vam traduir els exons de la proteïna.
I amb la seqüència anterior vam fer un tblastn en el NCBI contra els mRNAs coneguts de Paramecium tetraurelia, per comprovar que aquella predicció de proteïna es trobava al nostre organisme. A partir d'aquest mRNA i la seva corresponent proteïna, vam localitzar a la regió d'interès del scaffold l' ATG d'inici de la traducció de la GPx4 de Paramecium i el TGA stop.
Seqüència completa de GPx4 de Paramecium Tetraurelia
Proteïna GPx4 de Paramecium Tetraurelia
Aquesta predicció final de la GPx4 de Paramecium la vam alinear, mitjançant un blast contra tot el genoma de Paramecium tetraurelia, per comprovar que la identitat era del 100%, i que efectivament aquella proteïna estava present al nostre organisme.
Blast final
Ja finalment, per observar el percentatge d'identitat entre la GPx4 de Paramecium tetraurelia i la humana, vam fer un alineament mitjançant el ClustalW.
Alineament ClustalW
Methionine-R-sufoxide reductase 1 (SelR1)
El tblastn inicial de SelR1 humana contra el genoma de Paramecium tetraurelia mostrava un alineament de la U humana amb una C al scaffold_111. L'e-value obtingut va ser força baix, per tant vam procedir a extreure el fragment del scaffold que ens interesava.
blast
tblastn SelR1
Fragment Scaffold 111 SelR1
Vam utilitzar l'exonerate però degut a que l'homologia entre la proteïna humana i la seqüència de Paramecium no eren prou elevades, no vam obtenir cap resultat. Per superar aquest llindar, vam ajuntar el començament de la proteïna humana a la seqüència aminoacídica de Paramecium . Vam fer córrer l'exonerate una altra vegada i vam obtenir la predicció estructural, en la qual vam veure que aquesta proteïna té dos exons i un intró .
Exonerate SelR1
Vam traduir els exons i vam fer el blast contra mRNA al NCBI per tal d'aconseguir la seqüència completa de SelR1. A partir d'aquesta, vam localitzar a la regió d'interès del scaffold 111 el començament i finilatizació de la traducció de SelR1 de Paramecium tetraurelia.
Seqüència completa de SelR1 de Paramecium Tetraurelia
Per comprovar que la proteïna predita efectivament es troba al genoma de Paramecium tetraurelia vam utilitzar una altra vegada el programa exonerate.
Exonerate SelR1
Finalment, per observar el percentatge d'homologia entre SelR1 humana i SelR1 de Paramecium vam fer servir el programa ClustalW.
Alineament ClustalW
RESULTATS SECISearch
En el cas del genoma de Paramecium tetraurelia, no vam poder córrer el SEISearch per tot el genoma d'un sol cop (com s'ha explicat a Materials i Mètodes) ja que el servidor no funcionava correctament. Després d'hores d'intent, vam decidir córrer el programa sobre fragments del genoma. El procediment a seguir va ser:
Obrir en un emacs el genoma de Paramecium tetraurelia en format multifasta.
Seleccionar amb el mouse el 2-3% del genoma de forma recurrent (fins a 3%, fins a 5% agafant del 3 al 5%, etc.) de forma que agaféssim varis scaffolds a la vegada.
Copiar els fragments en SECISearch i donar-li a Submit.
Seleccionar només els hits amb un score superior a 15.
Un cop fet això per tot el genoma, els possibles elements SECIS obtinguts (indicadors de possibles noves selenoproteïnes) van ser els següents:
| Scaffold_ 26 / Score: 19'14 |
| Scaffold 29 / Score 22,10 |
| Scaffold_ 51 / / Score 18,44 |
| Scaffold_ 60 / / Score 24,16 |
| Scaffold_73 / / Score 17,36 |
| Scaffold_78 / / Score 15,44 |
| Scaffold_86 / / Score 16,11 |
| Scaffold_114 / / Score 15,33 |
| Scaffold_144 / / Score 33,12 |
| Scaffold_155 / / Score 16,11 |
Per manca de temps a l'hora de realitzar el treball, no ens ha estat possible continuar amb l'anàlisi d'aquestes potencials noves selenoproteïnes.
A part d'aquestes 10 potencials selenoproteïnes, mitjançant el SECISearch, vàrem trobar les selenoproteïnes que es van obtenir mitjançant el procediment d'homologia amb blast.
| Scaffold_ 133 / Score: 13,3 |
FAMÍLIA DI |
| Scaffold_11 / Score 21,16 |
FAMÍLIA TR |
En el cas de la selenoproteïna de la família DI, es va acceptar un score inferior a 15 ja que hi havia indicis molt clars i determinants (homologia amb DI humanes, predicció de l'estructura gènica amb l'exonerate, TGA al mig de l'ORF, etc) de què en el scaffold_133 hi havia una selenoproteïna pertanyent a la família de les DI.


