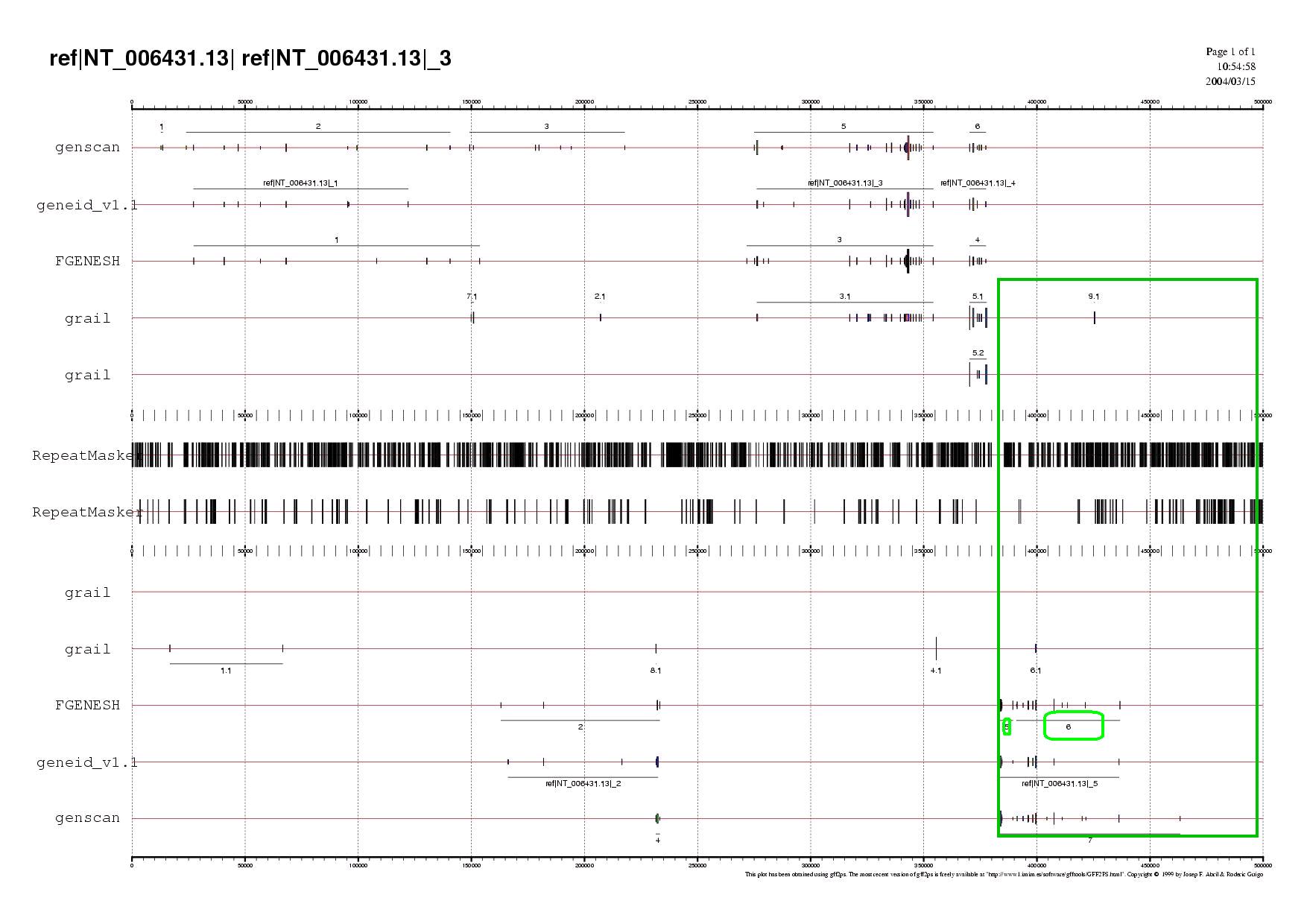
En aquesta subseqüència es poden trobar els gens que apareixen a al següent taula:
| PROGRAMA | NÚMERO DE GEN | COORDENADA D' INICI | COORDENADA FINAL | SENTIT |
| Geneid | 5 | 436382 | 388706 | reverse |
| Fgenesh | 5 | 389434 | 383706 | reverse |
| Fgenesh | 6 | 436802 | 391010 | forward |
| Genscan | 7 | 463391 | 383706 | reverse |
| Grail | 8.1 | 231584 | 31730 | reverse | Grail | 9.1 | 231584 | 231730 | forward |
Validació de la predicció de gens
Tal i com es pot veure al gràfic, sembla que els programes Genscan., Fgenesh i Geneid han fet una predicció molt similar. Tots ells prediuen el mateix final i els exons interns , només difereixen a l'hora de determinar l'inici del gen. Un petit detall que diferencia els resultats del programa Fgensh dels altres, és que en comptes de predir un sol gen n'ha predit dos. També cal remarcar que el programa Genscan aporta una predicció amb un exó inicial molt més allunyat
Grail ha donat uns resultats completament diferents perquè ha predit només dos exons, un dels quals (el que hi ha a la cadena en forward) no ha estat detectat pels altres programes.
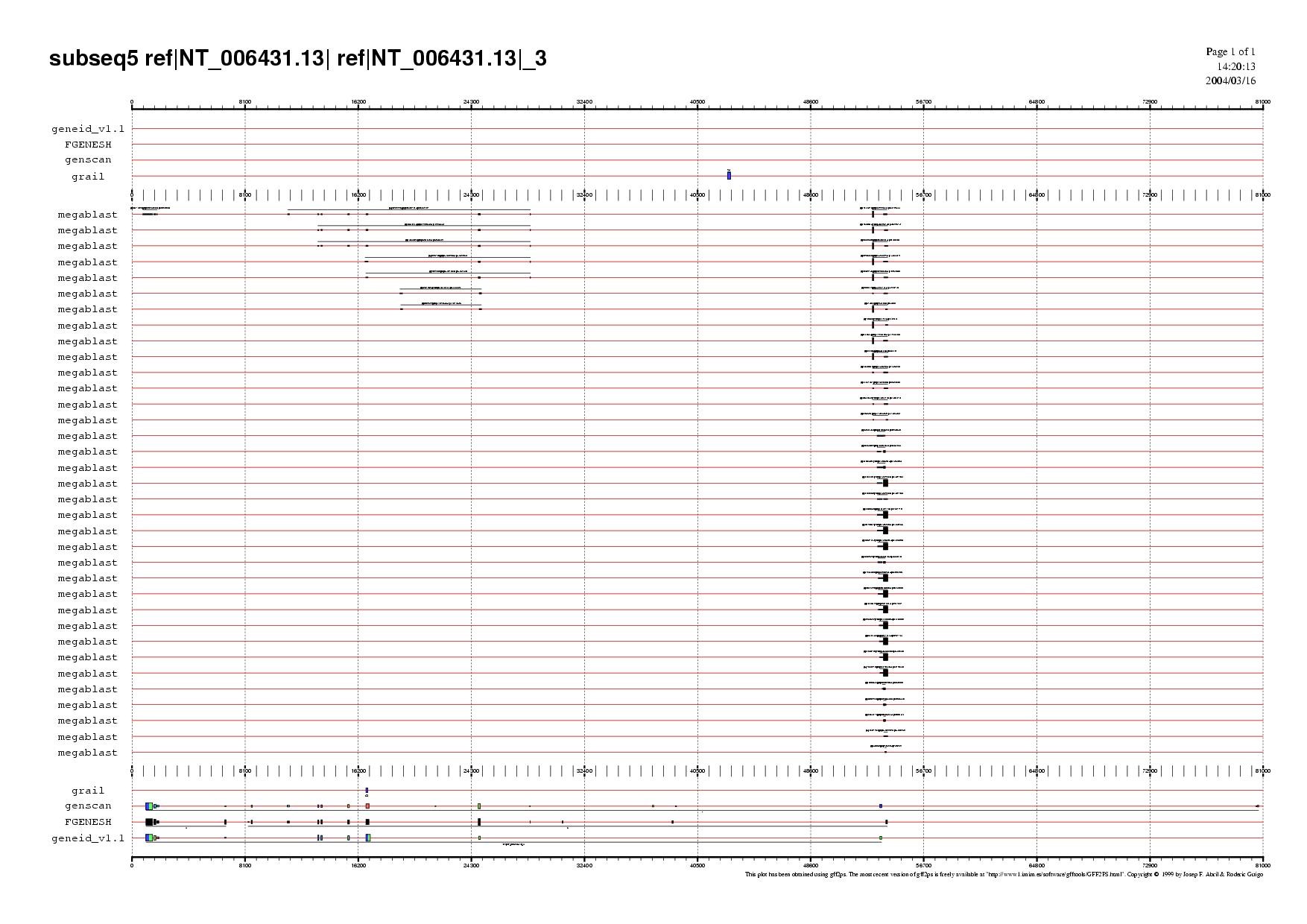
Mirant la validació pels ESTs humans, es pot apreciar el següent:
- Les predicions fetes pels programes Geneid i Fgenesh són les més robustes ja que apareixen una gran quantitat de ESTs suportant l'exó inicial predit per aquests programes.
- L'exó predit en forward pel programa Grail no ha rebut suport de cap EST, i per tant pot ser hagi estat un error del programa.
- Els exons intermedis estan suportats per una bona colla de ESTs apareixent splicing alternatiu en alguns fragments.Es pot observar, també que no hi ha cap fragment que connecti aquests ESTs amb els que prediuen l'inici del gen. Això fer pensar que no es tracta d'un únic gen.
- Hi ha un pseudogen a al final de la subseqüència (primer resultat de BLASTN) que es pot deduir per la presència d'un llarg EST molt separat de la resta. També podria ser que es tractés d'una regió UTR, no s'hauria de descartar aquesta hipòtesi
Un cop analitzat el gràfic el que sembla més adient és fer la cerca de la base de dades de proteïnes amb le prediccions efectuades o per Fgenesh o per Geneid. Atès a que el programa Geneid no aportava la seqüència de les proteïnes, s'ha decidit efectuar el BLASTP amb les prediccions de Fgensh.
Com ja s'ha comentat anteriorment, el programa Fgenesh ha predit dues proteïnes en comptes d'una. Llavors, la cerca de BLASTP s'efectuarà amb les proteïnes de les prediccions 5 i 6 d'aquest programa
Identificació de les proteïnes
Un dels dubtes que s'ha presentat després de fer el BLASTN, ha estat la possibilitat de que les proteïnes 5 i 6 predites per Fgensh en fóssin una en comptes de dues, tal i com apuntaven altres programes. Una cerca en BLASTP permetrà saber-ho ja que es podrà veure si són fragments o contràriament, presenten una homologia del 100% amb alguna proteïna.
Aquí es mostren les dues proteïnes utilitzades en la cerca amb el BLASTP:
>FGENESH: 5 4 exon (s) 383706 - 389434 272 aa, chain - MTAWTEEECRSFEHALMLFGKDFHLIQKNKVRTRTVAECVAFYYMWKKSERYDYFAQQTR FGKKRYNHHPGVTDYMDRLVDETEALGGTVNASALTSNRPEPIPDQQLNILNSFTASDLT ALTNSVATVCDPTDVNCLDDSFPPLGNTPRGQVNHVPVVTEELLTLPSNGESDCFNLFET GFYHSELNPMNMCSEESERPAKRLKMGIAVPESFMNEVSVNNLGVDFENHTHHITSAKMA VSVADFGSLSANETNGFISAHALHQHAALHSE
>FGENESH: 6 12 exon (s) 391010 - 436802 401 aa, chain - MDIRPNCLIYINNMNDKIKEEGLKRFPHALFSQFGHVMERPGRAEVANMDLVWTKQNLQL GMYQVSLGHPLRHVGDEQFLELASFGSSSPVGSLSSEDHDFDPTAEMLVHDYDDERTLEE EEMMDEGKNFSSEIEDLEKDSTVYLQFSIVTSAESVFMPWLEQEGTMPLEDLLAFYGYEP TIPAVANSSANSSPSELADELPDMTLDKEEIAKDLLSGDDEETQSSADDLTPSVTSHETS DFFPRPLRSNTACDGDKESEVEDVETDSGNSPEDLRKEIMIGLQYQAEIPPYLGEYDGNE KVYENEDQLLWCPDVVLESKVKEYLVETSLRTGSEKIMDRISAGTHTRDNEQALYELLKC NHNIKEAIERYCCNGKASQDVSETVQTQISHPPATSTFWKK
Anàlisi del gen 5 de Fgenesh
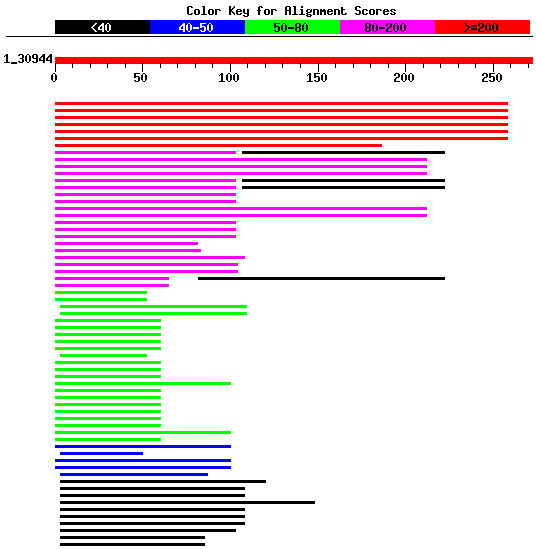
Fent una observació general del gràfic es pot veure que sembla que hi ha uns hits que presenten homologia amb gairebé tota la seqüència i amb scores força elevats i llavors uns altres que presenten homologia únicament amb una regió inicial de la proteïna.
També es pot observar que aquesta primera regió presenta hits que abarquen tot el rang de valors possibles i que provenen d'espècies molt allunyades filogenèticament. Probablement es deu tractar d'un domini altament conservat i per això podem veure que espècies com el Xenopus presenten proteïnes amb scores molt inferiors als de espècies com la rata o el ratolí.
Fent un anàlisi més exhaustiu dels primers hits es pot veure que:
- El primer de tots és una proteïna hipotètica anomenada FLJ35954 d'humà. Aquesta proteïna va ser publicada a Pubmed el desembre del 2003 i probablement deu trobar-se encara en estudi. És una proteïna d'unió a DNA que presenta un 100% d'homologia, té un score de 526 i un e-value de 10 exp -148 . Amb aquests resultats gairebé segur que la predicció correspon a aquesta proteïna.
- Les dues següents proteïnes tenen un score molt elevat (523) i un e-value molt semblant a l'anterior (10exp -147). Els articles publicats l'agost del 2003 les defineixen també com a hipotètiques i sembla que són la mateixa però de diferents formes de splicing. Es van extreure de teixit de ronyó fetal i la seva funció és desconeguda.
- Els dos següents hits, que també presenten un evalue i un score força bons, són una proteïna de ratolí provinent del cDNA d'una proteïna coneguda i una altra que seria la homològa a aquesta però de rata. Segons les dades que apareixen són proteïnes que contenen un domini anomenat ELM2, de funció desconeguda, que podria estar implicat en la unió a DNA
Finalment, també caldria comentar que sembla que hi podria haver un altre domini en aquesta proteïna ja que hi ha hagut alguns hits que han presentat una certa homologia amb una regió central de la proteïna. Els scores que presenten són tan baixos que no és possible saber-ho amb certesa.
Els resultats obtinguts de la base de dades de dominis conservats apunten a l'existència de diferents domins, el més imortant dels quals correspon a un domini d'unió a DNA (score de 119 i e-value de 5 exp -28).
Anàlisi del gen 6 de Fgenesh
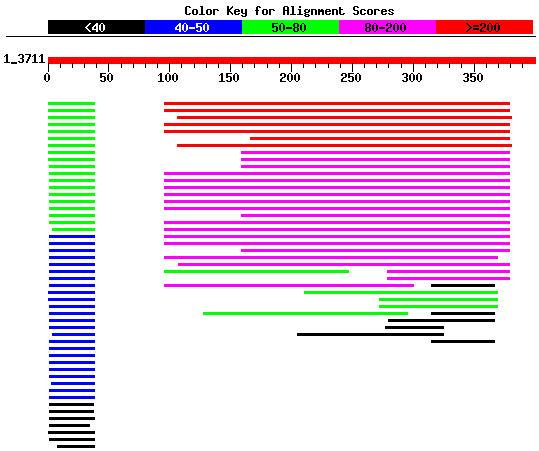
Fent una observació del gràfic es pot veure que sembla que hi ha dues regions que són homòlogues a altres proteïnes i una regió interna que no presenta homologia amb cap proteïna coneguda. També es pot veure que la regió final presenta scores més elevats que la primera regió.
Si ens fixem en els hits trobats, sembla que les proteïnes que presenten una més alta homologia, score i e-value són les mateixes que les resultants de la cerca anterior. Això estaria indicant que, tal i com alguns programes de predicció apuntaven, en aquesta regió tenim una única proteïna i no dues.
Mirant els links de la primera regió es pot veure que aquests corresponen a proteïnes de ratolí i rata. Aquesta regió es correspon al pseudogen del que s'ha parlat anteriorment. Llavors, podria ser que el pseudogen s'hagués integrat abans de l'aparició de l'home i per això s'entendria la homologia presentada amb proteïnes d'aquests animals. A més a més, el fet de que no hi hagi hagut una cap tipus de pressió evolutiva (ja que no codifica per a res) hauria permès que el pseudogen acceptés qualsevol mutació en la seva seqüència. Per aquesta raó, mentre el gen original hauria anat modificant-se, tot i que a una velocitat de canvi petita, el pseudogen cada cop hauria divergit més de la seqüència original.
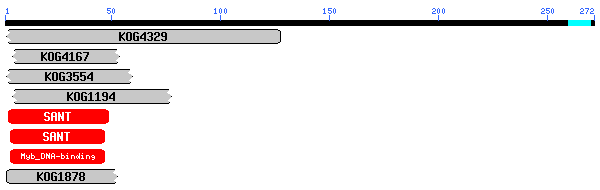
Com es pot veure al gràfic, no hi ha dominis que presentin homologia amb la proteïna ja que els que apareixen correponen a la regió on es troba el possible pseudogen.
Estudi de les regions promotores
La possible regió promotora que s'ha analitzat al Transfac és la següent:
subseq5promotora AAAACGTACTTTCTTGAAACCAGGGAACCGATTAAATAGCACAGATAACATCATCTCACG AGTCTCTGCTGGTAAATTAACTTAAAAATAAAACAGAATTCGGAGGGTAGTAAGAACCTG AGGATTTGGGTATCAGCTGAATTCAGTGTTTCCTGACCAGGCTTTCTGTTTGCGGTTGTT GCTATCTGTTCCACAGTTTGGGCTTTTTTCTTTTCTTTTGTCAGAAAAAGTGTCACACAT CTTAGAAATTATATCAGAATCTGTTTTTGCCTACTGGATTTGCATTGGTTTATCATACAA TGGAAATCCTTGTAACTGTCTCAAGGCATTTGTGGATGAGCCCAGTGTCCCGCACCCATC TTCATGGTCTTTAGAGCCACAATACTTACCACATGGCCAAACTGAGAAAACAGAGCGTGT GGGAATCTCTTCAATCCTTCTTCTTTAATTTTGTCATTCATATTGTTGATATAAATTAAG CAATTTGGTCTGATATCCATEls resultats generats, mostren la possible presència de tant sols una regió promotores. Aquesta es troba en la cadena de frame negatiu, essent un promotor d'un possible gen en reverse. Si s'observa novament el gràfic es pot veure que l'inici del gen predit per Fgenesh, concretament el primer exó altament suportat pels ESTs, es troba en posició reverse.
matrix position core matrix sequence (always the factor name identifier (strand) match match (+)-strand is shown) V$OCT1_Q6 275 (-) 1.000 0.955 tggaTTTGCattggt Oct-1
La possible regió promotora, es troba a la posició 275 i es correspon al factor Oct-1.
Tot i que els resultats d'ESTs no són gaire bons, ja que no validen molt bé l'inici del gen, la cerca amb el Blastp ha donat una proteïna amb alta homologia a la predita. Tot i que en un principi s'havia formulat la hipòtesi de la possible presència de dos gens, aquesta ha quedat descartada amb els resultats de BLASTP.La possible regió no es correspon a cap TATAbox però no es pot descartar la seva implicació en la regulació del gen.