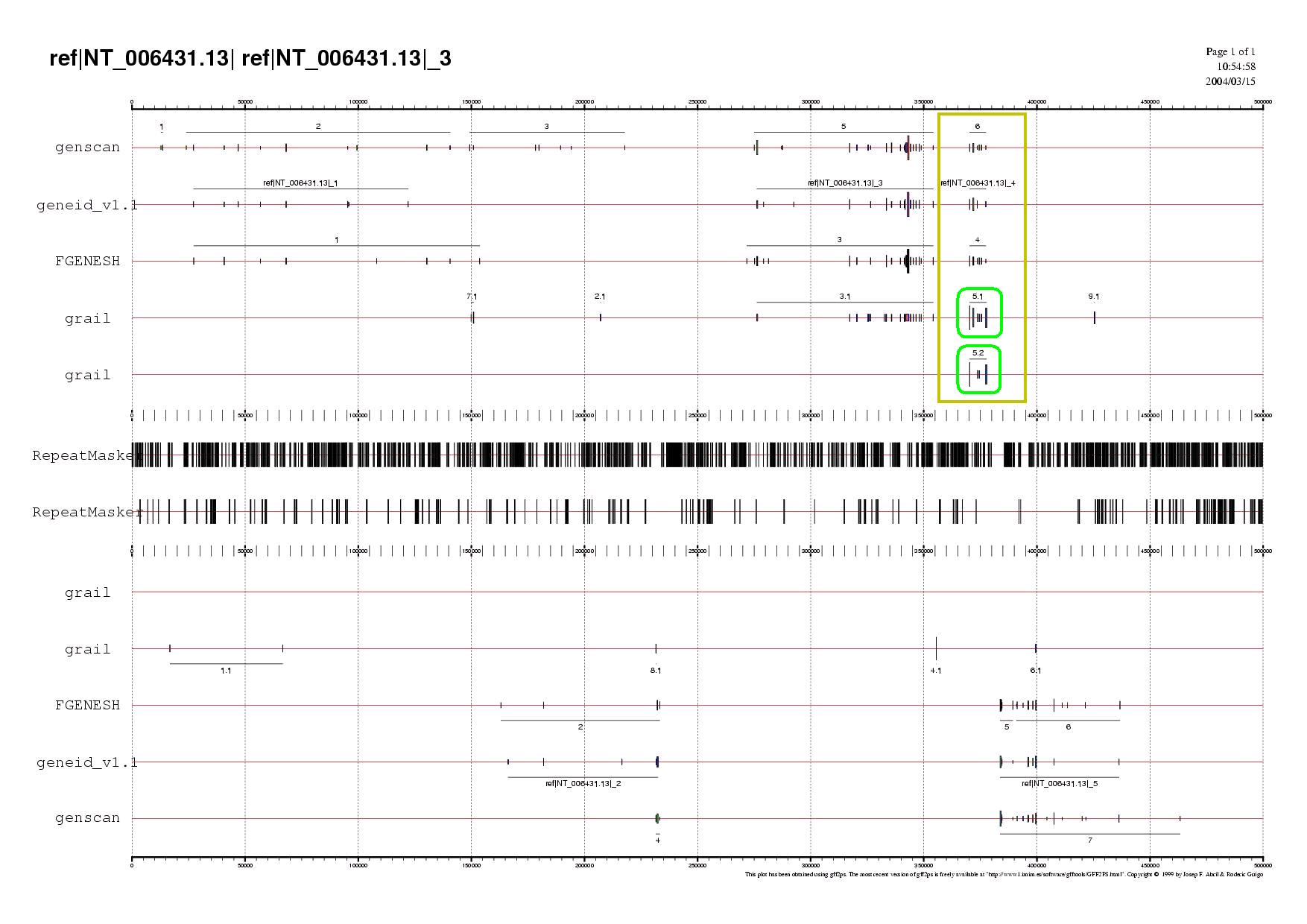
En aquesta subseqüència es troben les prediccions que apareixen a continuació:
| PROGRAMA | NÚMERO DE GEN | COORDENADA D' INICI | COORDENADA FINAL | SENTIT |
| Geneid | 4 | 370224 | 377480 | Forward |
| Fgenesh | 4 | 370224 | 377480 | Forward |
| Genscan | 6 | 370224 | 377480 | Forward |
| Grail | 5.1 | 370224 | 377769 | Forward |
| Grail | 5.2 | 370224 | 377769 | Forward |
Tal i com passva a la subseqüència anterior en aquesta regió també es pot veure que només hi ha predicció de gens a la cadena en forward.

Com es pot observar al gràfic tots els exons predits estan suportats per ESTs. Tots els programes de predicció de gens coincideixen en la predicció del primer exó i es pot veure que els ESTs no només el suporten sinó que a més a més mostren les regions UTR, confirmant així que la predicció dels programes ha estat ben realitzada. L'últim exó també presenta ESTs de les regions UTR i podem veure que la predicció que fa Grail dóna un exó més extens i sembla que és la més encertada.
Cal comentar que el programa Grail ha predit dues varaints de la mateixa proteïna, una d'elles sense el segon exó. Això seria un exemple de splicing alternatiu tot i que no seria l'únic ja que es pot veure que entre l'exó primer i el segon apareixen molts ESTs recolzant un inici alteratiu. Això es pot deduir perquè tal i com passava en els exons inicials i finals predits apareix la UTR ben marcada.
A continuació es pot veure el gràfic que mostra la distribució dels hits trobats que presenten una alta homologia amb la primera variant de la proteïna predita pel programa Grail.
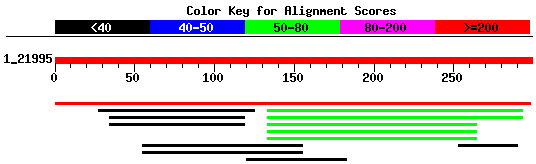
Com es pot observar hi ha molt pocs hits trobats, de fet , només hi ha una proteïna que presenta un score superior a 200 (582) i té una homologia alta (94%). Aquesta proteïna no és molt informativa perquè probablement deu estar en estudi, ja que ha estat descrita a començaments d'aquest any i encara és hipotètica. Per tant, no podem saber-ne la identitat.
Els altres hits que hem trobat es poden dividir en dos grups. Uns d'ells presenta un score força baix (proper a 50) i molt baixa homologia (un 26%). Aquest grup engloba proteïnes d'espècies molt allunyades a nosaltres (plantes i bacils). Ès molt poc informatiu i l'únic que pot cridar l'atenció és el fet que tots els hits trobats s’ubiquin a la mateixa regió. Podria tractar-se d'un domini que no hagi estat molt conservat al llarg de l'evolució i que per això presenti una tan alta divergència.
L'altre grup que es pot veure són hits que presenten una identitat inferior al 40% i a més a més tenen scores molt baixos. No es pot extreure, doncs, cap conclusió amb ells.
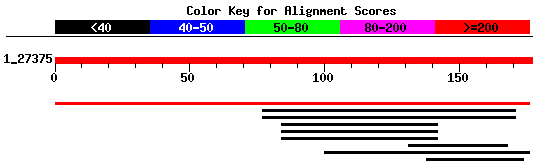
Pel que fa a la vairant 2 predita per Grail es pot obsevar que ocorre el mateix que per a l'altra variant però en aquesta la identitat amb la proteïna trobada (que és la mateixa que per a la variant 1) és d'un 100%. Probablement la proteïna publicada ha estat la variant 2 i per això la 1 difereix una mica (aquesta última conté un exó que la 2 no té). Els altres hits trobats no són informatius perquè tenen un score inferior a 40 i molt poca identitat.
Estudi de les regions promotores
La possible regió promotora que s'ha analitzat al Transfac és la següent:
subseq4promotora CAAAAGCACCTCAGTGGTTGCTTGGGGACTGGGGGAGGGGCTGGATTACTATCTTGGCTG TGGTGTCGANNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN NNNNNNNNNNNNNNNNNNNNNTTCAGAAACATTTGTCCATGTAGTTTTGCCTTTGAATGG TTGGGTCAATGAAGAGAAAAACGAGTGAAAACAGGGAATCATGACACTTTGTTTTTTTAC GTGTAAATATTCGCAAAACGCCCAAACTGGTAACTTTGGGAACACGGGTTCACGCAGAAG AAGGGCTGCTGTCTGGGGAGGACTGAAACTCGGGTTCCCGAAGTCGGGCTGCTCTGGGGC CACGGAGAGAAGGGGAGAGAACGTCGAGGAAGAGGCAGAGCTCAAGTGGACGGAGGATGG AACACAGAGCGCGGCCGGGACAAAGGGGCAGGCCAGACAGCCGTGACAGAGAAACTAGGC GGTCCGCTCCTGGGACGCGGEls resultats que s'han obtingut, indiquen la presència de tres regions promores; dues de les quals es troben en la cadena de frame positiu, de la mateixa manera que també hi trobem la predicció del gen suportat altament pels ESTs.
matrix position core matrix sequence (always the factor name identifier (strand) match match (+)-strand is shown) V$COMP1_01 174 (-) 0.914 0.801 tgaatggttgggtCAATGaagaga COMP1 V$PAX6_01 232 (+) 0.960 0.813 tttttTTACGtgtaaatattc Pax-6 V$NKX25_01 402 (+) 1.000 1.000 tcAAGTG Nkx2-5
Del les dues possibles regions promotres, una d'elles té una puntuació de 1.000 i es troba en la posició 402 (sempre respecte els 500 pb que anteriorment s'han tallat a partir de la posició del primer exó considerant aquesta la posició +1).
De manera que, a partir dels resultats aportats per la validació dels ESTs (els quals permeten reconstruir gairebé completament el cDNA) així com la presència d'una proteïna amb un score molt alt (94%), i uns promotors; es pot afirmar que és molt probable que aquest gen existeixi, essent la proteïna per la qual codifica la següent:
Score E Sequences producing significant alignments: (bits) Value gi|24308476|ref|NP_714917.1| hypothetical protein MGC33648 ... 582 >e-165