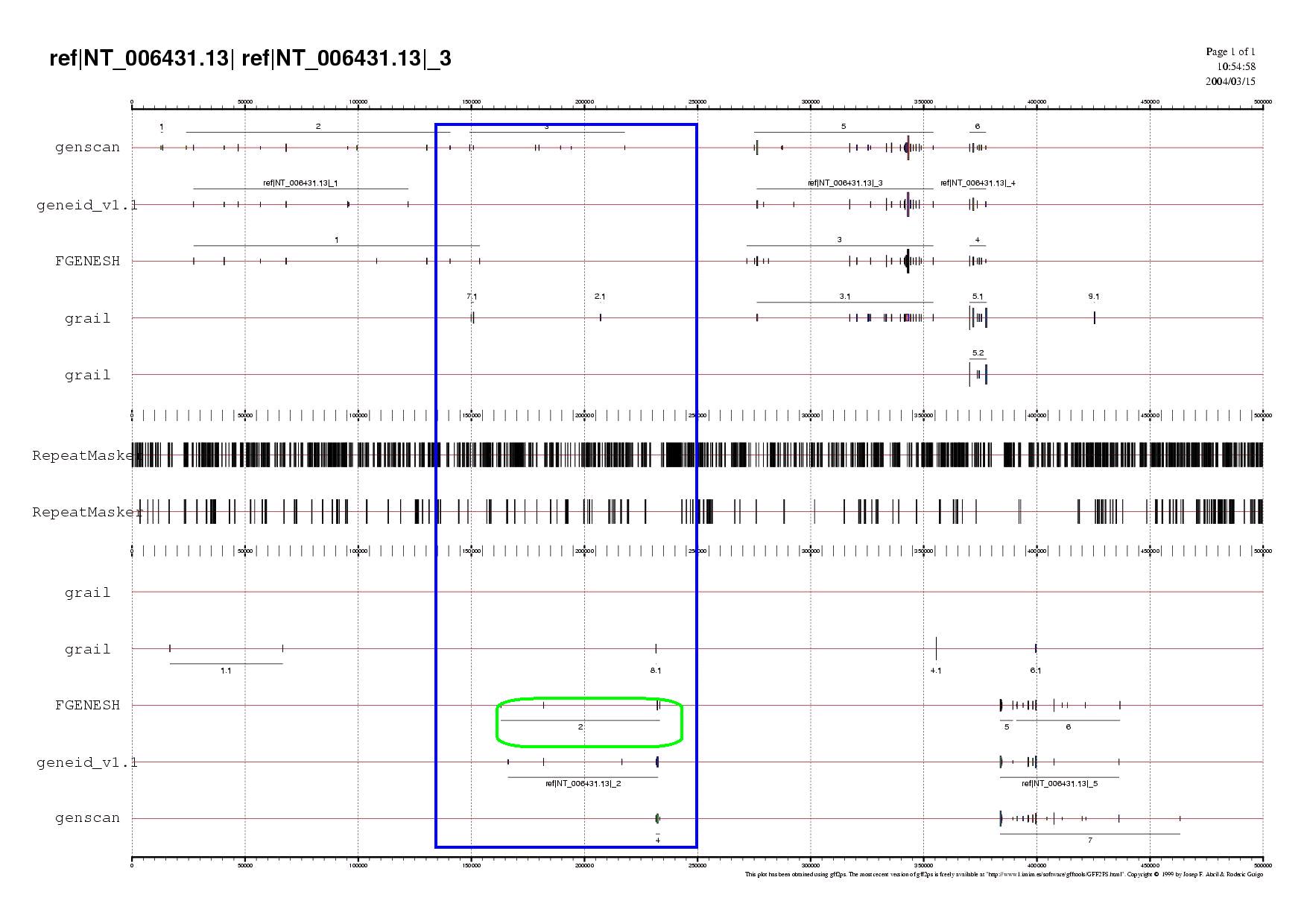
Aquesta subseqüència, que es troba entre els nucleòtids 152755 i 233502, comença a l'últim exó de la primera predicció de FGenesh (que és també l'últim exó de la primera subseqüència). Per aquesta raó no apareix marcat a la taula que s'adjunta a continuació, només apareix en color vermell la coordenada que s'ha pres com a final i a la qual se li han sumat els 1000 nucleòtids més. Per tant, es pot deduir que hi haurà un solapament de les subseqüències 1 i 2.
| PROGRAMA | NÚMERO DE GEN | COORDENADA D'INICI | COORDENADA FINAL | SENTIT |
| Geneid | 2 | 232502 | 166145 | reverse |
| Fgenseh | 2 | 233374 | 163021 | reverse |
| Genscan | 4 | 233374 | 231584 | reverse |
| Genscan | 3 | 149221 | 217894 | forward |
| Grail | 2.1 | 207046 | 207153 | forward |
| Grail | 8.1 | 231730 | 231584 | reverse |
Validació de la predicció dels gens
Al següent gràfic es pot observar la predicció dels gens efectuada pels diferents programes contrastada amb els resultats obtinguts al BLASTN.
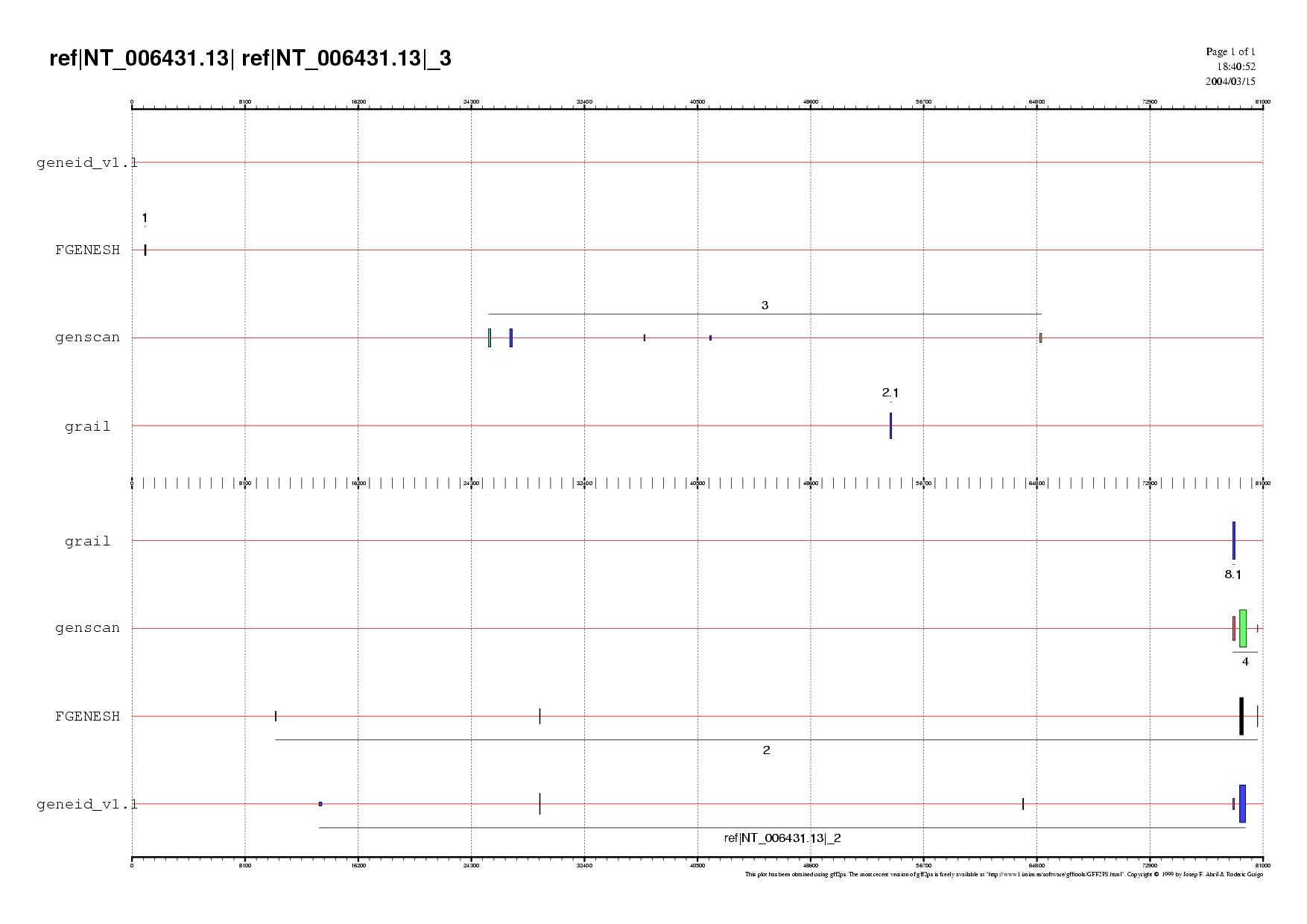
Com es pot observar, no hi ha recolzament de cap predicció, ja que no hi ha hagut resultats de ESTs humans per a aquesta subseqüència. Tal i com s'ha fet a la subseqüència anterior, s'ha repetit aquest pas però utilitzant una base de dades de ESTs d mamífers. Malauradament, tampoc s'obtenen resultats.
Així, l'única solució, és continuar l'anàlisi amb aquelles prediccions que semblin més probables.Llavors, com que a la cadena en reverse apareix un únic gen predit pels quatre programes i a més hi ha un exó comú entre ells que coincideix en la coordenada, s'ha decidit prosseguir en l'anàlisi amb aquest gen.
Identificació de les proteïnes
La següent seqüència correspon la predicció del gen 2 de Fgensh (reverse), que per la seva llargada s'ha cregut que era el més adequat per esbrinar la identificació de la proteïna.
>FGENESH: 2 4 exon (s) 163021 - 233374 123 aa, chain - MVLPSYSKKPLISNVEQLILGIPGQNRREIGHGQDIFPAEKLCHLQDRKVNLHRAAWGEC IVAPKTLSFSYCQGTCPALNSELRHSSFECYKEINLPVEIEGPYHVCFHSTLVRGALEEF TEA
Observant el gràfic que s'adjunta continuació es pot extreure la següent interpretació:

Es pot veure que el gen trobat no presenta cap hit amb un score superior a 50. El millor hit trobat té una homologia de només un 31% i un e-value de 0.001. Els altres hits trobats tenen valors pitjors.
El que crida l'atenció és la presència d'una regió on tots els hits hi troben un cert grau d'homologia. Això pot fer pensar en l'existència d'un possible domini central a la proteïna.
Fent una cerca en una base de dades de domins conservats de NCBI, s'ha trobat la presència de tres possibles dominis, tots ells TGF_beta, que en un dels casos presenta un e-value de 4e-09.

Per tant, sembla que el gen predit podria ser un gen de la família dels TGF_beta.
Estudi de les regions promotores
Els resultats obtinguts amb el programa TRASNFAC han predit la localització d'una regió promotora en reverse. Aquest promotor es troba en la posició 367 i té un score de 0.981.
matrix position core matrix sequence (always the factor name identifier (strand) match match (+)-strand is shown) V$GATA3_03 367 (-) 0.981 0.982 taATATCtgt GATA-3 Total sequences length=500 Total number of sites found=1 Frequency of sites per nucleotide=0.002000
Malgrat els resultats de la cerca de promotors siguin bons, no es pot saber amb seguretat si aquest gen existeix o no perquè els resultats de ESTs no l'han recolzat i a més a més no s'ha trobat cap proteïna amb un score significatiu a BLASTP. Llavors, en aquest cas, el més apropiat seria continuar la recerca.