En aquest organisme obtenim 12 hits vàlids, 9 dels quals en la mateixa regió. Alguns d'aquests hits no alineen la selenocisteïna de la nostra query amb un codó STOP o amb una cisteïna i per tant no els hauríem de considerar vàlids. No obstant, com hem vist en altres casos, alguns d'aquests hits produeixen mitjançant Exonerate proteïnes que sí que alineen la selenocisteïna de la query amb cisteïnes o codons STOP. Per contra, el Genewise produeix una proteïna més curta que no inclou aquest alineament, i que en principi no hauria de ser considerada una coincidència.
Aquest és el cas del hit trobat en la regió gi|299737272|gb|GL376617.1| que produeix una proteïna que alinea la nostra selenocisteïna amb una cisteïna. En alinear aquesta proteïna amb la query original obtenim un score de 89, fet que ens fa pensar que pot tractar-se d'un homòleg amb cisteïna de la nostra query en aquest genoma. A més, aquesta regió conté també un possible element SECIS (energia lliure: -18.40). Veient això hipotetitzem que pot tractar-se d'una antiga selenocisteïna codificada per un codó TGA que ha mutat a TGT (això ho veiem al resultat de l'Exonerate). Els elements SECIS estan conservats, fet que ens porta a pensar que la mutació de la nostra hipòtesi és recent.
El hit de la regió gi|299737278|gb|GL376611.1| també alinea la selenocisteïna amb una cisteïna i la proteïna que produeix té un grau suficient d'indentitat amb la nostra query com per afirmar que es tracta d'un altre homòleg amb cisteïna de la nostra query en aquest genoma.
En la regió gi|299737325|gb|GL376564.1| hem trobat 9 hits molt propers entre ells però no solapats. Tots alineen la selenocisteïna amb una cisteïna excepte els hits 7 i 9 que l'alineen amb serina i aspàrtic, respectivament. Per tant, aquesta regió del genoma conté moltes zones amb alta similaritat amb la nostra query. Observant els resultats de l'Exonerate, veiem que en alguns casos, el programa no es capaç de predir cap gen en aquella zona, mentre que en altres casos prediu més d'una proteïna sobre la mateixa regió (una subseq concreta). En aquests casos, el resultat del fastatranslate és una proteïna molt gran amb molts codons STOP intercalats.
Com que no sabíem com interpretar això vam analitzar aquesta macroproteïna amb el BLASTp contra la base de dades de seqüències proteiques no redundants d'NCBI. En aquest resultats observem que la proteïna obtinguda conté realment dues còpies d'un membre de la familia de les Glutatió peroxidases (que podria ser la GPx7) i a més, diverses còpies de dominis Thioredoxin like.
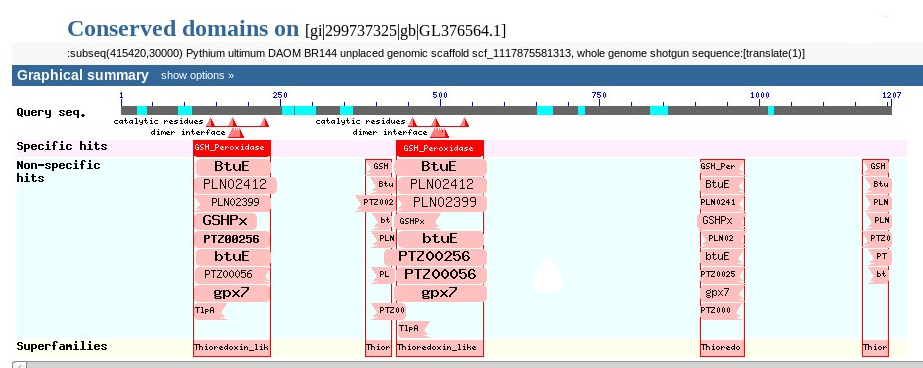
Per contra, el Genewise dóna un resultat força diferent: en el cas en què amb l'Exonerate no obtenia cap resultat (hit 9) el Genewise dóna un resultat acceptable, ja que obtenim una proteïna que al comparar-la amb la nostra query (TCoffee) mostra un alineament amb un score de 91 que usada com a query per un fer BLASTp porta a la GPx4 de P.infestans, predita el juliol del 2010.
>ref|XP_002997768.1| Gene info linked to XP_002997768.1 phospholipid hydroperoxide glutathione peroxidase, putative [Phytophthora
infestans T30-4]
gb|EEY67906.1| Gene info linked to EEY67906.1 phospholipid hydroperoxide glutathione peroxidase, putative [Phytophthora
infestans T30-4]
Length=1103
GENE ID: 9463149 PITG_18316 | phospholipid hydroperoxide glutathione
peroxidase, putative [Phytophthora infestans T30-4]
Score = 157 bits (396), Expect = 6e-37, Method: Compositional matrix adjust.
Identities = 79/147 (54%), Positives = 98/147 (67%), Gaps = 3/147 (2%)
Query 4 KRFLMEDLVGSVVLVVNVASKDPQAPLQYPELVTIADKYHDDGFTVLAFPSDQFGGDGQE 63
K MED G VVLVVNV+SK P YPEL + +KYH++G VL FP +QF G QE
Sbjct 887 KEVSMEDYKGKVVLVVNVSSKCGLTPTNYPELQQLHEKYHEEGLVVLGFPCNQFAG--QE 944
Query 64 FDTDGEILSYLVQAYKVNFPIMTKRDVNGLDARDAFLYLNAHLPGSFGPFTEWNFTKFLI 123
T EIL ++ Q Y V FP+ K DVNG +AR F YL A LPG+FG + +WNFTKFL+
Sbjct 945 PGTHEEILEFVKQ-YNVTFPLFEKHDVNGSNARPVFTYLKAKLPGTFGNYIKWNFTKFLV 1003
Query 124 DRHGKPFKRYETSVLPQSLEADIRQLL 150
DR+G+PFKR+ LP S E DI++LL
Sbjct 1004 DRNGQPFKRFAPKDLPPSFEEDIKELL 1030
En els casos en què l'Exonerate havia donat la macroproteïna, el Genewise produeix dues possibles proteïnes, una en cada strand (forward i reverse). De tota manera, sabem que tal com hem executat el Genewise, obtenim només, de totes les proteïnes possible, la que té un score més alt, tant un strand com en l'altre.Per tant, el Genewise està ocultant per a cada hit totes les altres proteïnes presents en la regió que l'Exonerate sí que mostrava.
Per intentar aprofundir més, hem agafat les proteïnes generades pel Genewise per a cada hit i les hem comparat amb un alineament multiple mitjançant TCoffee. Aquests són els resultats:
CLUSTAL W (1.83) multiple sequence alignment
gi|299737325|gb|GL376564.1|_subseq_399564_30000_.pep --KSIYELKDTDISGTEITFDKYKGKVLLVVNVSSNCGLTPTNYPELTAL
gi|299737325|gb|GL376564.1|_subseq_406731_30000_.pep A-HSIYQFMDLDIHGNPVSFDKYRGKVLLIVNVASGCKLASHNYPQLTHL
gi|299737325|gb|GL376564.1|_subseq_409506_30000_.pep A-HSIYQFMDLDIHGNPVSFDKYRGKVLLIVNVASGCKLASHNYPQLTHL
gi|299737325|gb|GL376564.1|_subseq_413480_30000_.pep AVKSIYELKDYDMQGNEVSMEKYKGKVLLVVNVSSLCGLTPTNYPELAEL
gi|299737325|gb|GL376564.1|_subseq_415420_30000_.pep AVKSIYELKDYDMQGNEVSMEKYKGKVLLVVNVSSLCGLTPTNYPELAEL
gi|299737325|gb|GL376564.1|_subseq_422557_30000_.pep AVKSIYELKDYDMQGNEVSMEKYKGKVLLVVNVSSLCGLTPTNYPELAEL
:***:: * *: *. ::::**:*****:***:* * *:. ***:*: *
gi|299737325|gb|GL376564.1|_subseq_399564_30000_.pep DEKYRDQGLVILAFPCNQFGSQEPGTNEEIVEFVKQYNAQYQFFEKADVN
gi|299737325|gb|GL376564.1|_subseq_406731_30000_.pep HEKYRNQGFEVLAFPCNQFGSEEPRNNEEIVQYVSQFNANYELFEKADVN
gi|299737325|gb|GL376564.1|_subseq_409506_30000_.pep HEKYRNQGFEVLAFPCNQFGSEEPRNNEEIVQYVSQFNANYELFEKADVN
gi|299737325|gb|GL376564.1|_subseq_413480_30000_.pep DKKYRDQGLEILAFPCNQFSNQEPGTHEEIMEFVKKYNCEFPFFEKHDVN
gi|299737325|gb|GL376564.1|_subseq_415420_30000_.pep DKKYRDQGLEILAFPCNQFSNQEPGTHEEIMEFVKKYNCEFPFFEKHDVN
gi|299737325|gb|GL376564.1|_subseq_422557_30000_.pep DKKYRDQGLEILAFPCNQFSNQEPGTHEEIMEFVKKYNCEFPFFEKHDVN
.:***:**: :********..:** .:***:::*.::*.:: :*** ***
gi|299737325|gb|GL376564.1|_subseq_399564_30000_.pep GPHARPVFAYLKAKLPGTFGNYIKWNFTKFLVDRNGQPFKRFAPTDKPLS
gi|299737325|gb|GL376564.1|_subseq_406731_30000_.pep GSHARPVFTFLKAKLPGTFGSFVKWNFTKFLVDRNGVPYKRFSPKDSPFD
gi|299737325|gb|GL376564.1|_subseq_409506_30000_.pep GSHARPVFTFLKAKLPGTFGSFVKWNFTKFLVDRNGVPYKRFSPKDSPFD
gi|299737325|gb|GL376564.1|_subseq_413480_30000_.pep GASARPVFTYLKAKLPGSFGNFVKWNFTKFLVDRNGQPYKRFAPKDLPFS
gi|299737325|gb|GL376564.1|_subseq_415420_30000_.pep GASARPVFTYLKAKLPGSFGNFVKWNFTKFLVDRNGQPYKRFAPKDLPFS
gi|299737325|gb|GL376564.1|_subseq_422557_30000_.pep GASARPVFTYLKAKLPGSFGNFVKWNFTKFLVDRNGQPYKRFAPKDLPFS
*. *****::*******:**.::************* *:***:*.* *:.
gi|299737325|gb|GL376564.1|_subseq_399564_30000_.pep FEHDIQELLS---
gi|299737325|gb|GL376564.1|_subseq_406731_30000_.pep LEDDIQELLN---
gi|299737325|gb|GL376564.1|_subseq_409506_30000_.pep LEDDIQELLN---
gi|299737325|gb|GL376564.1|_subseq_413480_30000_.pep FEDDIKALLEQKP
gi|299737325|gb|GL376564.1|_subseq_415420_30000_.pep FEDDIKALLEQKP
gi|299737325|gb|GL376564.1|_subseq_422557_30000_.pep FEDDIKALLEQKP
:*.**: **.
Com veiem, tenim dues proteïnes diferents, generades a partir de X dels hits. Cada una de les proteïnes està codificada en una strand diferent. Això ho sabem perquè com hem dit, el Genewise selecciona la millor proteïna de totes les que troba.
El Genewise dóna dues proteïnes sempre que el subseq del hit cobreixi la zona on aquestes estan. En alguns casos la subseq comença massa d'hora i la seva longitud (30000), no permet que pugui veure l'altre hit. En els casos en què la subseq cobreixi la zona de les dues proteïnes, podem observar les dues perquè es troben en strands diferents. Si estiguessin en el mateix strand, mai les haguéssim vist amb el Genewise (al contrari del que sí que havíem vist amb el resultat del Exonerate que hem passat per NCBI) perquè el propi programa hagués seleccionat la millor d'ambdues opcions.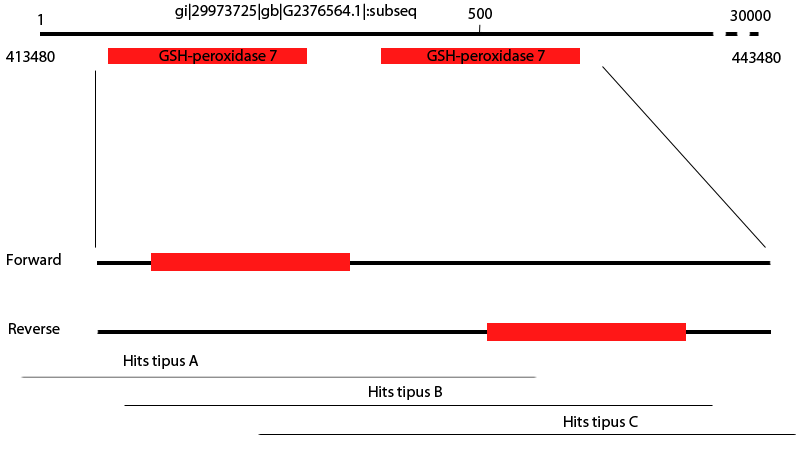 Esquema de la nostra hipòtesi: a cada strand trobem un dels gens i els hits solapants agafen diferents regions.
Esquema de la nostra hipòtesi: a cada strand trobem un dels gens i els hits solapants agafen diferents regions.
Resumint, els resultats de l'NCBI i del Genewise quadren totalment. En aquesta regió hi ha dues proteïnes homòlogues a la nostra query, que a més, tenen un alt grau de similaritat entre elles. Probablement, es tracta d'una duplicació molt recent, ja que el nombre de canvis entre una i l'altra es mínim.
Les petites diferències en algun del hits es deuen a que per generar les subseq utilitzem un mètode automatitzat per treballar amb el fastasubseq, que produeix subseq de diferents mides (si observem el codi de exonerate.sh, veurem que si al generar les subseq els valor sobrepassen els límits de la zona genòmica la redimensiona perquè s'hi adapti, per tant, hi ha subseq més llargues que altres). Això fa que l'Exonerate, al treballar amb determinades subseq, no vegi tota l'estructura genòmica que pot veure en altres fragments, i interpreti alguns motius de forma diferent, generant petites diferències en la proteïna final predita.
