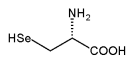
Fins fa relativament poc es creia que eren 20 els aminoàcids que constituïen les proteïnes. Però amb el descobriment de les selenoproteïnes (Sel), ha calgut afegir un nou membre a la llista: la selenocisteïna (Sec o U, Fig.1), que únicament es diferencia de l'aminoàcid cisteïna per la presència de Seleni enlloc de Sofre.
|
| 
|
Fig.1
La característica diferencial de les selenoproteïnes és la presència d'aquest aminoàcid, que és codificat pel codó TGA. Fins fa relativament poc es creia que aquest codó era únicament un codó STOP, però ara s'ha vist que en un 0,1% dels casos codifica per l'amionoàcid Sec.
 |
| Fig.2 |
La traducció alternativa del codó TGA per una selenocisteïna enlloc d'un codó STOP és deguda a la presència d'una estructura de mRNA coneguda com a element SECIS (Selenocysteine insertion sequence, Fig.2). Aquest element es localitza a la regió 3' UTR del mRNA que codifica per la selenoproteïna (excepte en bacteris, que es troba just després del codó TGA). La seva estructura, que generalment consisteix en 2 loops i 2 hèlix, permet el reclutament de varis factors i enzims que permeten la incorporació de l'aminoàcid Sec a la proteïna que s'està sintetitzant.
Les selenoproteïnes tenen representació en els 3 dominis (Eukarya, Bacteria i Archaea), però es tracta d'unes proteïnes de les quals es té poc coneixement de la seva importàcia funcional. Sembla ser, però, que es localitzen sovint al centre actiu dels enzims (sovint implicats en reaccions redox) i és important per a la seva activitat.
La correcte identificació de selenoproteïnes és important ja que es creu que permeten les funcions biològiques del seleni, que està implicat en processos tan diversos com la infertilitat masculina, la prevenció del càncer i les malalties cardíaques, reduccions de l'expressió viral, l'envelliment i la funció immunològica.
En humans s'han identificat 25 selenoproteïnes, però encara es desconeix la presència de proteïes similars en molts organismes.
En aquest treball estudiarem la distribució de 3 gens de selenoproteïnes del genoma humà en el domini eucariota. Les selenoproteïnes escollides han estat la SelI, la SelX (també coneguda com a SelR) i la SelW. Cal tenir present que únicament hem treballat amb organismes que tenen el genoma sequenciat.
Per assolir aquest objectiu hem realitzat un TBLASTN de la seqüència de les 3 selenoproteïnes humanes contra la base de dades EGO (Eukaryotic Gene Orthologs) i la EST, per tal de triar les seqüències nucleotídiques d'altres espècies que alineaven amb amb les nostres selenoproteïnes al ser traduïdes a proteïna.
Llavors hem dissenyat un programa per tal de filtrar les seqüències d'interès. De totes aquelles seqüències que alineaven, el nostre programa permetia seleccionar aquelles on la selenocisteïna de la nostra selenoproteïna alineava amb una cisteïna, una selenocisteïna o un codó stop (ja que sovint s'ha interpretat erròniament el codó TGA coma codó stop).
Posteriorment, hem traduït totes les seqüències nucleotídiques a proteïna mitjançant el programa Transeq; i hem realitzat un alineament múltiple amb el Clustalw per tal d'apreciar les regions conservades en totes les espècies.
Finalment, hem buscat elements SECIS mitjançant el programa SECISearch en aquelles seqüències que hem considerat que codificaven per una selenoproteïna.




