Selenoproteins are proteins that contain in its structure one or more residues of the nonstandard amino acid selenocysteine, which in turn has Selenium in its structure. Selenocysteine has the particularity that is encoded by the UGA codon. So as to include this amino acid in a protein, Sec insertions sequence (SECIS) must be present as well as a specific machinery.
Here, we aim to characterize and annotate the selenoproteome of Centrocercus urophasianus, which although unknown, is the largest native grouse species in North America. In order to do so, an homologous-based study between Centrocercus urophasianus and a proximate species phylogenetically, Gallus gallus, was performed. The program created used tblastn, exonerate and T-Coffee. Also, SECISearch3 and Seblastian were employed.
With this study we identified 19 selenoproteins in the genome of our target species.
Overall, with this project we hope to shed light on the Centrocercus urophasianus genome and therefore provide a better understanding of this species.
Selenium is an essential trace element. Despite being present in very low levels in the human organism, selenium is an essential micronutrient with important functions in the organism and therefore being relevant in many pathophysiological conditions [1]. It has been related to many health benefits such as decreasing cancer’s incidence, protecting against cardiovascular diseases and boosting the immune system, even though it was initially thought to be a toxin [2].
Selenium can be found in the aminoacid Selenocysteine (SEC), which is known as the 21st amino acid in the genetic code. This aminoacid has shown similar functions to cysteine, being the difference having a selenium instead of a cysteine. Once in the protein, Sec acts as a catalytic residue.
Selenocysteine is encoded by the UGA codon which is located upstream of a stem-loop structure known as Sec insertions sequence (SECIS) element. This element is of crucial importance since the UGA codon normally encodes for a STOP codon. Thus, the incorporation of Selenocysteine instead of producing an stop codon has to be genetically encoded [3].
From this aminoacid, the concept of Selenoproteins arises. These are proteins which contain in its structure one or more residues of the nonstandard amino acid selenocysteine.These proteins can be found in organisms from all three domains of life (Eukarya, Archaea and Bacteria) whereas yeast, fungi, and higher plants lack these selenoproteins [4].
Up to date, there have been 25 selenoproteins identified in the human proteome and 24 in the mouse and rat one.
The biological functions of some of them remain yet to be identified. From what it is known, most selenoproteins act catalyzing oxidation/reduction reactions which leads to antioxidant protection.
Specifically, the families of Selenoproteins that are mostly linked to this function are glutathione peroxidases (GPxs) and thioredoxin reductases (TrxRs).
Despite Redox Regulation being the main function characterized, selenoproteins also play a role in many other specific processes. For instance, selenoproteins may also have an structural role due to their capacity to oligomerize proteins via the formation of diselenide or mixed disulfide-selenide bridges. Others, such as iodothyronine deiodinases , are related to thyroid hormone metabolism or with spermatogenesis, which is the case of GLPx4.
The mechanism of action of these proteins is not completely understood yet. However, many studies carried out recently have shown the crucial role of this kind of protein in human diseases. To cite an instance, selenoprotein deficiency caused by low dietary Se can lead to affections such as Keshan disease, Kashin-Beck disease, Myxedematous Endemic Cretinism and male infertility [1].
SELENOPROTEINS FAMILIES
Based on where the Sec residue is located, selenoproteins can be divided into two different groups:
The first group includes the Selenoprotein families whose Sec residue location is in the C-terminal region. That is to say, thioredoxin reductases (TrxRs) and selenoprotein I (SelI), SelK, SelO, Sel P, SelR, and SelS.
The second group, which contains the rest of the selenoproteins is characterized by the presence of the Sec residue in the N-terminal region, This group includes the following glutathione peroxidases, iodothyronine deiodinases, SelH, SelM, SelN, SelT, SelU, SelV, SelW, SPS2, and Sep15.
The Sec residue is located in the C-terminal region
Thioredoxin reductases (TrxRs)
This enzyme, which is a component of the Trx system, catalyzes the reduction of thioredoxin or other proteins using NADPH. There are three of them in the human genome [5].
Selenoprotein I (SelI)
Selenoprotein I, which has a transmembrane structure, is involved in the endoplasmic reticulum-associated protein degradation [5].
Selenoprotein K (SelK)
This protein is an ubiquitous type mainly expressed in the spleen, immune cells, brain and heart. Its structure suggests that it principally works as a reductasa that can be adapted to a wide range of substrates [1].
Selenoprotein O (SelO)
From all of 25 mammalian selenoproteins, SelO is the one with the largest volume. This protein can be found in a wide variety of organs such as the brain or the heart. Although its function is not completely established, it is thought to participate in oxidative stress and regulation of S-glutathionylation levels [5].
Selenoprotein R (SelR) or Methionine-R-sufoxide reductase B
SelR is a selenoprotein with antioxidant characteristics. Its function consists in repairing damaged proteins due to oxidation and taking part in the redox regulation system by using methionine residues. The expression of this protein is regulated by dietary selenium [5].
Methionine-R-sufoxide reductase A
As part of the group of Methionine sulfoxide reductases (Msrs), this enzyme catalyzes the conversion of methionine sulfoxide to methionine. Besides, MsrA is able to reduce free methionine-S-sulfoxide [6].
Selenoprotein S (SelS)
Sel S is a transmembrane protein situated in the ER that is linked to ER-associated degradation (ERAD) of unfolded as well as misfolded proteins. It is expressed in a wide range of tissues such as liver, kidneys or adipose tissue [1].
The Sec residue is located in the N-terminal region
Glutathione peroxidases
These are a family of Selenoproteins with antioxidant characteristics. Particularly, they catalyze the reduction of hydrogen peroxide and other peroxides such as lipid hydroperoxides using GSH as an essential cofactor. By doing this, they protect the organism against oxidative stress. The GPX family contains 8 isoforms. However, only five of them (GPx1, GPx2, GPx3, GPx4 and GPx6) in the human genome can indeed do this process [5].
Iodothyronine deiodinases
These selenoproteins are a family of membrane proteins with oxido-reductasa activity. They are involved in thyroid metabolism. More specifically, Iodothyronine deiodinases catalyze reductive deiodination of thyroid hormones, producing their activation and inactivation. There are three of them in the human genome [5].
Selenoprotein H (SelH)
Sel H is a selenoprotein that presents DNA-binding properties [1].
Selenoprotein M (SelM)
Sel M is a thiol-disulfide oxidoreductase [1].
Selenoprotein N (SelN)
Sel N has been related to disorders referring to the muscle and to the ryanodine receptor control [1].
Selenoprotein P (SelP)
This protein, which has 10 sec residues, is mainly synthesized in the liver. Studies have shown SelP's function to be related to the transport and homeostasis of Se [1].
Selenoprotein T (SelT)
Sel T is a selenoprotein member of the thioredoxin-like family located at the Golgi apparatus and ER. It has also been seen that it is expressed in embryonic tissues. Studies suggest that its function is related to ontogenesis, tissue regeneration and maturation and the metabolism and nervous and endocrine system [1].
Selenoprotein U (SelU)
This selenoprotein is a newly identified protein which is part of the thioredoxin-like family. It is mainly expressed in eukaryotes. Its function remains primarily unknown [7].
Selenoprotein V (SelV)
This selenoprotein is a member of the thioredoxin-like family whose expression only takes place in spermatocytes. Its N-terminal domain is abundant in prolines and SeCys are situated in a hydrophobic domain [1].
Selenoprotein W (SelW)
Sel W is a small protein that is thought to have antioxidant functions despite the fact that its precise pathways are yet to be established [1].
Selenoprotein 15 (Sel15)
Sel15 is a thiol-disulfide oxidoreductase, as it is Sel M. This protein is expressed in the Endoplasmic reticulum and is involved in controlling that protein folding takes place correctly [1].
SELENOPROTEINS BIOSYNTHESIS
So as to synthesize selenoproteins it is necessary the interpretation of the UGA codon not as a stop codon but as a selenocysteine insertion signal (SECIS). Moreover, Sec´s tRNA has to be able to correctly bind serine and carry out the necessary modification in order to subsequently insert the aminoacid into a selenoprotein.
The machinery to do so includes specific secondary structures in the mRNA (SECIS), a unique tRNA (Sec.tRNA(SEc)), an RNA binding protein (SBP2) and a specialized elongation factor (EFsec) [8].
Biosynthesis of tRNA-Sec
Initially, tRNA is aminoacylated with serine that comes from the diet. This structure is known as tRNA[Ser]Sec. In mammals, there are two isoforms of this molecule that are distinct from each other depending on whether they have a ribose methylated at position 34 or not.
The process by which Sec is binded to its tRNA is facilitated by seryl-tRNA synthetase. In archaea and eukaryotes, the next step of the process is carried out by the phosphoseryl-tRNA[Ser]Sec kinase (PSTK) which converts seryl-tRNA[Ser]Sec to phosphoseryl-tRNA[Ser]Sec. Afterwards, SecS converts phosphoseryl-tRNA[Ser]Sec into the end product of the pathway selenocysteyl-tRNA[Ser]Sec. Particularly, this is achieved by SecS enabling the acceptance of selenophosphate. This selenophosphate is synthesized by Selenophosphate synthetase 2 (SPS2) from selenophosphate at the expense of ATP.
Apart from this path explained there is also the possibility of selenide being replaced by sulfide in the reaction that involves SPS2. In this case thiophosphate (H”PO3-) will be generated. This product will interact with SecS and PSer-tRNA[Ser]Sec so as to generate Cys-tRNA[Ser]Sec [9].
Figure 1. Synthesis of tRNA-Sec [10]
Sec insertion into protein
The insertion of selenocystein into a selenoprotein takes place thanks to a conserved stem–loop structure, known as the Sec insertion sequence (SECIS) element and depends on the UGA codon. In karyotic organism, SECIS is located at the 3’-UTR. Also, in mamalian selenoprotein mRNAs there are two forms of SECIS elements Type I and Type II elements
In this process two additional structures play a role, being them: SBP2 and EFsec. The first one is suggested to bind in the first place to the SECIS element of the selenoprotein mRNA. Moreover, EFsec function of binding Sec-tRNASec allows the interaction between EFsec and SBP2. It is this contact that promotes the insertion of selenocysteine and, therefore, recording of the UGA codon.
EVOLUTION OF SELENOPROTEINS
Selenoproteins have not been maintained during evolution in the same way in all organisms. For instance only about 25% of bacteria and 15% of archaea continue having these proteins nowadays. As far as eukaryotes are concerned, there has been more conservation of these molecules since around half of eukaryotes still have selenoproteins.
Many genes are needed to biosynthesize and insert selenocysteine into proteins so as to obtain selenoproteins. Thus, once the trait is lost, there is no way to regain it. However, there is an exception to this which are the uncommon phenomena of lateral transfer of an operon responsible for the Sec trait in prokaryotes [2].
Centrocercus urophasianus
The greater sage-grouse (Centrocercus urophasianus) is a kind of grouse found nowhere except in the west of North America both in the United States and Canada.
In fact, it is the largest native grouse species in North America [11].
Its main particularities are the peculiar courtship dances males display in which up to 70 males gather together and strut with their chests puffed out, their tales extended and their yellow air sacs inflated so as to attract females [12].
Its current population is estimated to be around 200.000-500.000 individuals however each day this population decreases.
TAXONOMY
KINGDOM
Animalia
PHYLUM
Chordata
CLASS
Aves
ORDER
Galliformes
FAMILY
Phasianidae
GENIUS
Centrocercus
SPECIES
C.urophasianus
DESCRIPTION
Centrocercus urophasianus, more commonly known as the greater sage-grouse, is a large, long-pointed tail bird with round wings. Also, its legs feathered to the base of the toes. The most characteristic trait of the greater sage-grouse are the bulbous yellow sacks located on their breasts that they are able to inflate during their mating display.
Thus, these sacks are only seen in males. Besides, other differences between genders could be that males tend to be larger than females and also do show a white ruff around their necks [11].
Figure 2:Centrocercus urophasianus [11]
BEHAVIOUR
For most of the year sage-grouse are inconspicuous, browsing on sagebrush and other plants at ground level. From March to May, males, which are intensively territorial on leks, perform elaborate and highly coordinated dances in bare ground called leks. Females visit these leks to evaluate the males and choose the best mates. Many of the females will match with the same male.
Young males tend to end up having confrontations between them which can end up in wing attacks.
Although Greater Sage-Grouse are strong and they can fly at considerable speed, they are not characterized by their endurance which leads to flights that usually are no longer than a few miles [13].
DISTRIBUTION
This species is mainly nonmigratory since it tends to move short distances (approximately 20 miles) between wintering and nesting areas. During these short migration processes females are the ones who lead the way to their chicks.
Figure 3:Centrocercus urophasianus distribution [13]
As we have previously mentioned, the greater sage-grouse is sorely located in North America. In fact it can be found in 11 states of the United States and two Canadian provinces. More precisely, the state of America that accounts for a bigger population is Wyoming (37% of the total population), followed by Montana (18%) and Nevada and Idaho (both of them 14%). No other state exceeds the 7% [11].
However it is also important to mention that given the fact that its distribution has decreased considerably in the last years, the greater sage-grouse is considered a species in danger [13].
FEEDING
Their diet consists mainly of leaves, buds and insects. Nevertheless, there are variations depending on the season of the year. For instance, during fall and winter their principal sources of energy are leaves and fresh shoots of sagebrush. The other half of the year, they may also ingest flowers and some kinds of insects (specially the young individuals). Most grouse have a digestive system that is well adapted to ingesting hard seeds however for the greater Sage-Grouse this is not the case [12].
In this homology-based study, we aimed to identify the selenoproteosome and the machinery needed so as to sintethyse the selenoproteins of a recently sequenced organism: Centrocercus urophasianus. To do so, we designed a semiautomatic program with the purpose of annotating the proteins deduced from this bird using tools such as tblastn, exonerate, t-coffee and Seblastian, among others.
The figure below shows the overall process we have carried out during our project:
We chose chicken (Gallus gallus) selenoproteoma as reference due to its close phylogenetic relation to our species of interest and given the fact that it is well annotated.
In order to find the selenoproteoma of this reference species we used the selenoDB 2.0 database.
Then, we employed this genome to align it to the one of Centrocercus urophasianus´s genoma.
We then downloaded these sequences in FASTA and changed the selenocysteine represented by "U" to "X". We did also remove possible "@" located in some sequences. This step was crucial so that the tblastn performed next was able to correctly read the sequence without detecting any error. The command needed to do this substitution was the following:
Obtention of the genomes and the index
Firstly, we obtained the programs necessary to carry out our project. These programs were provided by the professors of the bioinformatics course at UPF from a servidor that could be accessed using the following:
The genome of C. urophasianus was accessed from the following public server:
The index that was used as database was also provided to us by the University and could be accessed by doing the command:
TBLASTN
Blast enabled us to compare the queries with the genome of our organism of interest, Centrocercus urophasianus. Particularly, we used tblastn since it gives us the opportunity to align proteins to genomic sequences.
The blast was run using the following command:
The result obtained will be a search of the possible alignments. In order to decide which are the best alignments we needed to establish a threshold. This was possible using the E-value. This variable accounts for the number of times this alignment would take place if we just considered randomness.
More specifically, the threshold we used determined that hits with a value higher than 0,0001 were desestimated. The reason for this is that the lower the E-value is, the higher the hits significance and we only wanted significant hits.
With this program we located the regions of interest that we will then extract with the Fastasubseq.
FASTAFETCH
In order to obtain the contigs of interest, we run the Fastafetch command. This gave us the chance to extract the contigs from the C. urophasianus, which identifies with the best matches of tBLASTn. The command used to do so is shown below:
The output was saved with the name genome_fetch_$prot
FASTASUBSEQ
We used the fastasubseq command with the aim to extract the specific region inside the contig generating a new file. To run this command we needed to define the initial position, which is the start, and the length that the region of interest will have.
In order not to lose any information, we added approximately 50.000 base pairs up and 50.000 base pairs down in our contig of interest.
In order to assign a value to the variables $start and $lenght, depending on the strand (forward or reverse), and the length of the scaffold, different conditions were determined.
First, the variables $minimum1 and $minimum2 were assigned to decide if the protein was in the forward or reverse strand:
To identify the proteins located in the reverse strand, this code was written:
To identify if the proteins were located in the forward strand, this code was written:
However, we also had to determine if the scaffolds were long enough to add 50.000 base pairs up and down. Therefore, we had to insert these conditions inside both forward and reverse stranded-proteins. Here is the example for those proteins located in the reverse strand. The same reasoning was performed in the forward strand, but different variables were settled.
Here we show the command used:
Files obtained from this comand are stored as subseq_$prot.
EXONERATE
Inside this region that we defined using fastasubseq, both introns and exons were present. Bearing in mind that we were only interested in the exons, the exonerate software helped us to predict the number and exact location of the protein's exons. Also, in the command we added an egrep of the exons so as to extract them.
We then stored the results obtained in a file called prot1.exonerate.gff.
The command used is represented next:
FASTASEQFROMGFF
Next, we run a Fastaseqfromgff command that is used to generate a single file of the exons obtained from the previous step. This command created a new file which put together the adjacent exons therefore obtaining the respective cDNA.
Fastaseqfromgff command is shown below:
FASTATRANSLATE
From the C. urophasianus cDNA sequence that we have just predicted, we applied FastaTranslate so as to obtain the corresponding protein sequence that was stored in a file called aa_$prot. When running this command, we wanted it to start translating from the start and to avoid the use of other reading frames. To do so, we use the -F1 argument
The command used is presented here:
T-COFFEE
T-COFFEE's function was to produce a global alignment between the aminoacid's sequence that we predicted and the query from chicken (Gallus gallus).
SECIS AND SEBLASTIAN
As we have explained in the introduction Sec insertions sequences (SECIS) are crucial for the correct presentation of the Sec residues. This is why finding these elements provided us a way to determine where selenoproteins were supposed to be. In order to confirm the results obtained, we used Seblastian. We run both of these programs manually.
AUTOMATIZATION
All the steps explained were automatized in a program (poner link a programa) that enables us to process all the selenoproteins at the same time.
In this program a loop was created so that it gave us the opportunity to analyze all the proteins in our directory. For each of the proteins processed, different files will be created for each of the steps explained.
So as to access to the program developed we used the following command:
This family of Selenoproteins, which is made up of 8 isoforms, is characterized by its antioxidant properties. More precisely, glutathione peroxidases, using GSH as cofactor, reduce hydrogen peroxide and other peroxides, for instance lipid hydroperoxides. Thus, this contributes to the protection of the organism against oxidative stress.
In our study we have considered the glutathione peroxidases GPx3, GPx7 and GxP8.
GPx3
The scaffold that we analyzed for this protein was JAHKSY010000026.1. More precisely, the region studied was between the positions 10914276 - 10913320 . Considering the start and the end of this region of the genome and the query, we determined the location to be in the negative strand.
By using exonerate we were able to determine that the gene is made up of 4 exons. Also, fastatranslate enabled us to establish the number of aminoacids of the protein studied, which in this case was 192.
T - coffee showed a high score, exactly 996, which is close to 1000 and this led to the conclusion that there is a considerable degree of conservation between the protein of our reference organism (Gallus gallus) and the protein that we managed to predict. Nevertheless, some aminoacid variations could be observed in particular positions between these proteins. In the output of the protein predicted we could observe a ‘*’ in the position of an aminoacid. This, in the T-Coffee, corresponded to an Indel. Nevertheless, taking into account that both selenocysteines and indels are encoded by a STOP codon, the indel shown could have been a selenocysteine. So as to obtain a solution to this question we needed to use Seblastian.
T-Coffee did also show a gap at the beginning of the predicted protein. The explanation to this could be related to the fact that there has been a deletion on the genome of our species or also because the protein may not be well annotated. Besides, T-Coffee enabled us to determine that GPx3 protein does not start with Methionine which means that this part of the protein has not been as properly predicted as we would have wanted.
Employing Seblastian we have not detected any selenoprotein nor selenocysteines. As far as SECIS elements are concerned, by using the SECISearch3 program we have been able to determine a grade A SECIS element.
Therefore, bearing in mind that SECIS elements have been found but not selenocysteine, this suggests that currently Centrocercus Urophasianus GPx3 is not a selenoprotein. Selenocysteine loss may be due to evolutionary forces.
GPx7
The scaffold that was considered in the study of this protein was JAHKSY010000018.1.
Specifically, the region studied was between the positions 23811381 - 23813556. Bearing in mind the start and the end of the region of the genome and the query, we determined the location in the positive strand.
Exonerate enabled us to determine that the gene is made up of 2 exons. Also, using fastatranslate we established the number of aminoacids of the protein studied, which in this case was 130.
T - coffee showed a significantly high score, precisely 998, which is close to 1000 and this led to the conclusion that there is a considerable degree of conservation between the protein of our reference organism (Gallus gallus) and the protein that we managed to predict. Almost no aminoacid variations could be observed in positions between these proteins. In the case of GPx7 protein, T-Coffee did not show a gap at the beginning of the predicted protein. Moreover, T-Coffee enabled us to determine that GPx7 protein does not start with Methionine from which we concluded that this part of the protein has not been as properly predicted as we would have wanted.
Using Seblastian we have not detected any selenoprotein and thus no selenocysteines were observed. Regarding SECIS, employing the SECISearch3 program we have been able to determine a grade C SECIS element.
Therefore, the existence of SECIS elements but not the presence of any selenocysteine suggested that currently Centrocercus Urophasianus GPx7 is not a selenoprotein. Selenocysteine loss may have happened due to evolutionary processes.
GPx8
The scaffold that was taken into consideration in our project of this protein was JAHKSY010000968.1. More precisely, the positions that were considered for the study were the following 18018 - 20611. Bearing in mind the start and the end of the region of the genome and the query, we determined the location in the positive strand.
With Exonerate we were able to determine that the gene is made up of 2 exons. Besides, employing fastatranslate we established the number of aminoacids of the protein studied, which in this case was 123.
T - coffee showed a high value, precisely the score of alignment in this case was 994, which is close to 1000 and this led to the conclusion that there is a considerable degree of conservation between the protein of our reference organism (Gallus gallus) and our predicted protein. Practically no aminoacid variations could be observed in positions between these proteins. In the case of GPx8 protein, T-Coffee did not show a gap at the start of the protein we managed to predict. Furthermore, T-Coffee enabled us to determine that GPx7 protein does not start with Methionine which led us to conclude that this initial region of the protein has not been as properly predicted as we would have wanted.
Regarding SECIS, making use of the SECISearch3 program we have been unable to determine SECIS elements. This loss could be explained if we consider the loss of these elements in our species of study due to evolutionary processes.
Thus, the absence of SECIS elements and selenocysteine suggests that the GPx8 of Centrocercus urophasianusis not a selenoprotein nowadays.
Furthermore, we have had to analyse this protein manually, as the program was not programmed to work with small scaffolds, and fastasubseq command was not able to precisely determine the length. Moreover, the program does not filter positions by e-value, which can lead to fastasubseq errors.
Iodothyronine deiodinases
Iodothyronine deiodinases are a family of selenoproteins located in the membrane that possess oxido-reductasa capacity. These proteins play a crucial role in the thyroid metabolism since they catalyze the deiodination of thyroid hormones. In our project we have considered the Iodothyronine deiodinases DI I and DI II.
DIO1
The scaffold that was chosen in our project of this protein was JAHKSY010000018.1. Specifically, the positions that we studied were the following 24483886 - 24487618. Taking into consideration the start and the end of the region of the genome and the query, we determined the location in the positive strand.
Exonerate enabled us to establish that the gene is made up of 4 exons. Moreover, employing fastatranslate we determined the number of aminoacids of the protein studied, which in this case was 246.
T - coffee showed a high value, precisely the score of alignment in the case of DIO1 was 997, which is close to 1000. From this, we concluded that there is a considerable degree of conservation between the protein of our reference organism (Gallus gallus) and our predicted protein. Few variations in the aminoacid sequence could be observed between the two proteins. Regarding DIO1 protein, T-Coffee did not show a gap at the start of the protein we managed to predict. Moreover, T-Coffee enabled us to determine that DI I starts with Methionine which indicates a good prediction in this initial part of the protein.
In the output of our protein predicted we observed a ‘*’ that in the T-Coffee was shown as an Indel. However, given the fact that both selenocysteines and indels are encoded by a STOP codon, the indel shown could have been a selenocysteine. So as to obtain a solution to this question we needed to use Seblastian.
Making use of Seblastian we have detected one selenoprotein with its corresponding selenocysteine. As far as SECIS are concerned, by using the SECISearch3 program we have been able to determine a grade A SECIS element.
Thus, since SECIS elements have been found as well as selenocysteines, this suggests that DIO1 protein in Centrocercus is a selenoprotein.
DIO2
The scaffold that we analyzed for this protein was JAHKSY010000014.1. The positions chosen as the region of interest were the following 33783895 - 33772424. Taking into consideration the start and the end of this region of the genome and the query studied, we established the location of the gene in the negative strand.
By using exonerate we determined that the gene is made up of 3 exons. Also, fastatranslate enabled us to establish the number of aminoacids of the protein studied, which in this case was 408.
T - coffee showed a high score, exactly 996. This led us to conclude that there is a considerable degree of conservation between the protein of our reference organism (Gallus Gallus) and the protein that we predicted with our program. Practically no variations of aminoacids were observed between the sequences. However, T-Coffee did show a gap at the start of the predicted protein. This could be explained considering a possible deletion on the genome of our species or it could also be that the protein has not been well annotated.
As far as the Seblastian is concerned, we have detected one selenoprotein with its corresponding selenocysteine. In regards to SECIS, by using the SECISearch3 program we have been able to determine a considerable number of SECIS elements, 65.
Hence, given the fact that selenocysteines have been found as well as the considerable amount of SECIS elements located, we managed to determine that DIO2 protein is currently a selenoprotein in Centrocercus.
DIO3
The scaffold that was taken into consideration in the project of this protein was JAHKSY010000014.1
Precisely, the region studied was between the positions 42491680 - 42492453. Bearing in mind the start and the end of the region of the genome and the query, we determined the location in the positive strand.
Exonerate enabled us to determine that the gene is made up of 1 exon. Moreover, using fastatranslate we established the number of aminoacids of the protein studied, which in this case was 258.
T - coffee showed a high score, exactly 996. With this information, we reached the conclusion that there is a considerable degree of conservation between the protein of our reference organism (Gallus gallus) and the protein that we predicted with our program. Practically no variations of amino acids were observed between the sequences. However, T-Coffee did show a gap at the start of the predicted protein. Some explanations to this could be that there has been a deletion on the genome of our species or also that the protein has not been correctly annotated.
In the output of our protein predicted a ‘*’ was observed which in the T-Coffee results was shown as an Indel. Nevertheless, since selenocysteines and indels are both encoded by a STOP codon, the indel shown could have been a selenocysteine. In order to obtain a solution to this question we needed to use Seblastian.
Employing Seblastian we have been able to detect one selenoprotein with its corresponding selenocysteine. Regarding SECIS, by using the SECISearch3 program we determined the presence of 3 SECIS elements, two of them being grade B and the other one grade A.
Thus, considering the selenocysteine located as well as the SECIS elements found, all this suggests that the protein DIO3 of Centrocercus urophasianus is a selenoprotein.
Furthermore, we have had to analyse this protein manually, as the criteria used in the program to select the $start and the $length for the fastasubseq command was not suitable for this protein. Even if the program could filter by e-value, this selection would not work for DI3.
Thioredoxin reductases (TrxRs)
This family of selenoproteins plays a role as part of the Trx system. Its function is related to the reduction of thioredoxin or other proteins using NADPH. In our project we have considered the thioredoxin reductases Tr I, Tr II and Tr III.
Tr I
The scaffold considered to study the Tr I protein was JAHKSY010000022.1. Precisely, the region sconsidered was between the positions 9443818 - 9435463. Considering the start and the end of this region of the genome and the query, we determined the location in the negative strand.
Making use of exonerate we were able to determine that the gene contains 12 exons. Besides, with fastatranslate we determined the number of aminoacids of the protein studied, which in this case was 479.
T - coffee showed a score of alignment of 999. Being this value remarkably high, we were able to elucidate a considerable conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict. However, we do see some variations of amino acids between the sequences. With T-Coffee we also determined the presence of a gap at the start of the protein. An explanation to this gap could be a deletion on the genome of our species or it could also have happened that the protein is not well annotated.
Moreover, Tr I protein does not start with Methionine. This indicates that this part of the protein has not been correctly predicted.
Using Seblastian we have detected one selenoprotein and its corresponding selenocysteine. In regards to SECIS, employing the SECISearch3 program we have been able to determine 4 SECIS, one of them being grade A and the rest grade B.
Thus, the existence of SECIS elements and presence of any selenocysteine suggested that currently Centrocercus urophasianus Tr I is a selenoprotein.
Tr II
The scaffold taken into consideration in our project was JAHKSY010000030.1. Specifically, the region considered was between the positions 11505291 - 11534961. Taking into consideration the start and the end of this region of the genome and the query, we determined the location in the positive strand.
Employing exonerate we established that the gene contains 16 exons. Besides, with fastatranslate we determined the number of aminoacids of Tr II, which was 514. T - coffee indicated a score of alignment of 997. Being this value considered high, we were able to elucidate a considerable conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict. Some variations in the aminoacid sequence could be seen, however there were only a few.
Also, with T-Coffee we did not determine a gap at the start of the protein. Moreover, Tr II protein has a Methionine in its start which indicates a good prediction at the start of the protein.
In the output of our predicted Tr II we observed a “*” which was shown as an indel in the T-Coffee. Since selenocysteine and indels are both encoded by a STOP codon, the indel shown could have been a selenocysteine. So as to differentiate the situation we used Seblastian.
Applying Seblastian we have detected one selenoprotein and its selenocysteine. In regards to SECIS, employing the SECISearch3 program we have been able to determine a grade A SECIS element. Therefore, the existence of SECIS elements and the presence of selenocysteine suggested that currently Centrocercus urophasianus Tr II is a selenoprotein.
Tr III
The scaffold that we analyzed for this protein was JAHKSY010000022.1. Specifically, the region studied was between the positions 9454327 - 9435184. Considering the start and the end of this region of the genome and the query, we established the location in the negative strand.
By using exonerate we determined that the gene contains 16 exons. Also, fastatranslate enabled us to establish the number of aminoacids of the protein studied, which in this case was 606.
T - coffee showed a really high score of alignment, exactly 999, which led to the conclusion that the degree of conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict is very high. Thus, our protein has been really conserved. There were practically no variations of amino acids observed between the sequences.
Also T-Coffee did not show gaps at the start of the predicted protein. Besides, Tr III protein starts with Methionine which allows us to establish that a good prediction at the start of the protein has taken place.
In the output of our predicted Tr III a “*” was shown which in the T-Coffee output corresponded to an indel. However, since selenocysteines as well as indels are both encoded by a STOP codon, the indel shown could have been a selenocysteine. So as to differentiate the situation we used Seblastian.
Applying Seblastian we have detected one selenoprotein and its corresponding selenocysteine. As far as SECIS are concerned, employing the SECISearch3 program we have been able to determine four SECIS elements, one of them being grade A and the rest grade B.
Therefore, since SECIS elements have been determined as well as selenocysteine, this suggests that currently Centrocercus urophasianus Tr III is a selenoprotein.
Selenoprotein R (SelR) or Methionine-R-sufoxide reductase B
SelR, also known as Methionine-R-sufoxide reductase B, comprises a group of selenoprotein related to antioxidant properties. What these proteins do is mainly to repair damaged proteins due to oxidation and contribute to the redox regulation system making use of methionine residues.Also, dietary selenium regulates the expression of these proteins. In our study we have analyzed selR I and selR II.
SelR I
The scaffold that we analyzed for this protein was JAHKSY010000029.1. Precisely, the region sconsidered was between the positions 7371797 - 7372431. Considering the start and the end of this region of the genome and the query, we determined the location in the positive strand.
By using exonerate we were able to determine that the gene contains 3 exons. Besides, using fastatranslate we established 107 as the number of aminoacids of the protein studied.
T - coffee showed a score of alignment of 993, a high value which led to the conclusion that the degree of conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict is high. Practically no variations of amino acids were observed between the sequences studied.
Moreover, T-Coffee did not show gaps at the start of the predicted protein. Besides, SeR I protein starts with Methionine. This enables us to establish that a good prediction at the start of the protein has taken place.
In the output of our protein predicted we observed a “*” that in the T-Coffee it was identified as an Indel. However, bearing in mind that both selenocysteines and indels are encoded by a STOP codon, the indel saw in the T-coffee could have been a selenocysteine. To obtain a solution to this question we needed to use Seblastian.
Making use of Seblastian we have detected one selenoprotein and its corresponding selenocysteine. As far as SECIS are concerned, by using the SECISearch3 program we have been able to determine a grade A SECIS element.
Hence, the existence of SECIS elements as well as the fact that selenocysteine were present, suggested that currently Centrocercus urophasianus sel R I is a selenoprotein.
SelR III
The scaffold taken into account for SelR III protein was JAHKSY010000015.1. Specifically, the region considered was between the positions 32218860 - 32270277. Bearing in mind the start and the end of this region of the genome and the query, we determined the location in the positive strand.
By using exonerate we were able to determine that the gene contains 5 exons. Besides, using fastatranslate we established 164 as the number of aminoacids of the protein studied.
T - coffee showed a score of alignment of 1000. Due to this value obtained,we were able to establish a complete conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict is high. No variations of amino acids were observed between the sequences studied. Moreover, SeR III protein does not start with Methionine. This shows us that the initial part of the protein has not been correctly predicted.
Employing Seblastian no selenoproteins have been detected and therefore no selenocysteines are present. As far as SECIS are concerned, by using the SECISearch3 program we have been able to determine a grade B SECIS element.
Consequently, the existence of SECIS elements but not the presence of any selenocysteine suggested that currently Centrocercus urophasianus selR III is not a selenoprotein. Selenocysteine loss may be due to evolutionary processes that have taken place.
Methionine-R-sufoxide reductase A (MsrA)
This selenoprotein, which is part of the group of Methionine sulfoxide reductases (Msrs) catalyzes the conversion of methionine sulfoxide to methionine. Moreover, it reduces free methionine-S-sulfoxide.
The scaffold taken into account as to study the MsrA protein was JAHKSY010000039.1 Precisely, the region considered was between the positions 4198947 - 4091989. Considering the start and the end of this region of the genome and the query, we determined the location in the negative strand.
By using exonerate we were able to determine that the gene contains 3 exons. Besides, using fastatranslate we established 125 as the number of aminoacids of the protein studied.
T - coffee showed a score of alignment of 1000. Bearing into account this value obtained, we established a complete conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict. Furthermore, MsrA protein does not start with Methionine, which informs us about the fact that the initial part of the protein has not been correctly predicted.
Using Seblastian no selenoproteins have been detected and neither selenocysteines. Regarding SECIS, by using the SECISearch3 program we have been able to determine two SECIS elements, both of them grade B.
Thus, the existence of SECIS elements but not the presence of any selenocysteine indicated that currently Centrocercus urophasianus MsrA is not a selenoprotein. Selenocysteine loss may have its explanation in evolutionary processes.
Selenoprotein P (SelP I)
Selenoprotein P is mainly synthesized in the liver. Although little is known about this protein, studies have shown Selenoprotein P’s function to be related to the transport and homeostasis of Se. In our project we have studied selP I and selP II.
The scaffold that we analyzed for this protein was JAHKSY010000018.1. From this, the region studied was between the positions 20363678 - 20362748. Considering the start and the end of this region of the genome and the query, we determined the location in the negative strand.
By using exonerate we were able to determine that the gene contains 5 exons. Also, with fastatranslate we established the number of aminoacids of the protein studied, which in this case was 267.
T - coffee showed a score of alignment of 981 which accounts for a degree of conservation between the predicted protein and the protein of reference high, although we could see some level of sequence variation in terms of the amino acids.
In the output of our protein predicted we observed a “*” that in the T-Coffee was displayed as an Indel. Nevertheless, since selenocysteines and indels are encoded by a STOP codon, the indel shown could have been a selenocysteine. In order to solve this question we needed to employ Seblastian.
With the T-Coffee, we also managed to determine that there were no gaps at the start of the predicted protein. Besides, Sel P protein does not start with Methionine, which indicates that this part of the protein has not been as correctly predicted as we would have wanted.
Using Seblastian we were able to detect one selenoprotein and its selenocysteine. Regarding SECIS, using the SECISearch3 program we have determined one grade A SECIS element.
Hence, the existence of SECIS elements and the presence of selenocysteine suggested that currently Centrocercus urophasianus SelP I is a selenoprotein.
SelP II
The scaffold taken into account to study the SelP II protein was JAHKSY010000025.1. Precisely, the region considered was between the positions 13378614 - 13384140. Considering the start and the end of this region of the genome and the query, we determined the location in the positive strand.
Making use of exonerate we were able to determine that the gene contains 4 exons. Also, using fastatranslate we determined the number of aminoacids of the protein studied, which in this case was 249.
T - coffee showed a score of alignment of 995. This value, which is considerably high, indicates a high conservation between the protein of our reference organism (Gallus gallus) and our predicted protein.
With this T-Coffee we also did not obtain any gap at the start of the protein. Moreover, SelP II protein starts with Methionine, which indicates to us that the initial region of the protein has been correctly predicted.
In the output of our protein predicted we observed a “*” which was seen as an Indel in the T-Coffee However, given the fact a STOP codon encodes both selenocysteines and indels, the indel shown could have been a selenocysteine. In order to obtain a solution to this question we needed to make use of Seblastian.
Employing Seblastian, one selenoprotein has been detected and its corresponding selenocysteine. Regarding SECIS, making use of the SECISearch3 program we have been able to determine two SECIS elements, one of them grade A and the other grade C.
Thus, since SECIS elements have been found as well as selenocysteine, this suggests that currently Centrocercus urophasianus SelP II is a selenoprotein.
Sel S
Sel S is a transmembrane protein which is located in the ER. Its function is related to ER-associated degradation (ERAD) of unfolded as well as misfolded proteins. Its expression takes place in many tissues, being some examples of it, the liver, kidneys or the adipose tissue.
The scaffold considered to study the Sel S protein was JAHKSY010000023.1. Concretely, the region considered was between the positions 2293576 - 2297389. Considering the start and the end of this region of the genome and the query, we determined the location in the positive strand.
Making use of exonerate we determined that the gene contains 6 exons. Also, using fastatranslate we determined the number of amino acids of the protein studied, which in this case was 194.
T - coffee showed a score of alignment of 995. This value, which is considerably high, indicates a high conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict. With this T-Coffee we also did not obtain any gap at the initial region of the protein. Moreover, Sel S protein starts with Methionine. This tells us that the beginning protein has been properly predicted.
In the output of our protein predicted we observed a “*” that in the T-Coffee could be seen as an Indel. Given the fact that both selenocysteines and indels are encoded by a STOP codon, we were unable to determine the situation just with the T-Coffee. Thus, we needed to employ Seblastian.
Seblastian enabled use to detect one selenoprotein and its corresponding selenocysteine. Regarding SECIS, using the SECISearch3 program we have been able to determine three SECIS elements, one of them grade A and the other two grade B.
Therefore, the existence of SECIS elements as well as the presence of selenocysteine suggested that currently the protein Sel S found in Centrocercus urophasianusis a selenoprotein.
Selenoprotein U (Sel U): SelU I
This selenoprotein is a member of the thioredoxin-like family. It is mainly expressed in eukaryotes. Its function remains primarily unknown. In our project we have analyzed selU I.
The scaffold taken into account to study the Sel U I protein was JAHKSY010000017.1. Concretely, the region considered was between the positions 31266874 - 31260540. Considering the start and the end of this region of the genome and the query, we determined the location in the negative strand.
Making use of exonerate we were able to determine that the gene is made up of 5 exons. Also, using fastatranslate the number of aminoacids of the protein studied was determined to be 227.
T - coffee showed a score of alignment of 997. This value, which is high and close to 1000, indicates that the degree of conservation between the protein of our reference organism (Gallus gallus) and the predicted protein is high. In fact, few amino acid variations could be observed.
With this T-Coffee we also did not obtain any gap at the start of the protein. Besides, Sel U I protein starts with Methionine, which gives us the indication that the initial part of the protein has been predicted in a proper way.
In the sequence of our predicted protein we could observe a “*” in the position of an aminoacid that in the T-Coffee was shown as an Indel. However, since both selenocysteines and indels are encoded by a STOP codon, the indel shown could have been that or also a selenocysteine.This question could be answered employing Seblastian.
Seblastian enabled use to detect one selenoprotein and its corresponding selenocysteine. As far as SECIS are concerned, employing the SECISearch3 program we have been able to determine three SECIS elements, one of them grade A and the other two grade B.
Therefore, the fact that SECIS elements are present as well as selenocysteine indicates that currently the protein sel U I in Centrocercus urophasianusis a selenoprotein.
Selenoprotein I (SelI)
This selenoprotein is located in the membrane as a transmembrane molecule. Its function is linked to the endoplasmic reticulum-associated protein degradation.
The scaffold considered in the case of the protein Sel I for our study was JAHKSY010000010.1. Specifically, the region considered was between the positions 55991 - 37126. Taking into account the start and the end of this region of the genome and the query, we determined the location in the negative strand.
Employing exonerate we determined that the gene is made up of 10 exons. Besides, with fastatranslate we predicted the number of aminoacids of the protein studied which was 400.
T - coffee showed a score of alignment of 999. This value, which is remarkably high and almost 1000, translates in a high degree of conservation between the protein of our reference organism (Gallus gallus) and our predicted protein. In fact, almost no amino acid variations could be observed.
With this T-Coffee we also did not obtain any gap at the start of the protein. Besides, Sel I protein starts with Methionine, which gives us the indication that the initial part of the protein has been predicted in a proper way.
In the sequence of our predicted protein we could observe a “*” in the position of an aminoacid that in the T-Coffee was shown as an Indel. However, since both selenocysteines and indels are encoded by a STOP codon, the indel shown could have been that or also a selenocysteine.This question could be answered employing Seblastian.
Seblastian enabled use to detect one selenoprotein and its corresponding selenocysteine. As far as SECIS are concerned, using the SECISearch3 program we have been able to determine a grade A SECIS element.
Thus, since a SECIS element is present as well as selenocysteine, this suggests that currently the protein sel I in Centrocercus urophasianusis a selenoprotein.
Moreover, we have had to analyse this protein manually, as the program does not filter the tblastn results by e-value, which can lead to errors in selecting the $start and $length in the fastasubseq command.
Selenoprotein K (Sel K)
Selenoprotein K expression primarily takes place in the spleen, immune cells, brain and heart. Selenoprotein K, which is an ubiquitous type, is suggested to work as a reductasa able to adapt to many substrates owing to its structure.[14]
SelK I
The scaffold considered to study the Sel S protein was JAHKSY010000022.1. Exactly, the region considered was between the positions 12569911 - 12571104. Bearing in mind the start and the end of this region of the genome and the query, we determined the location in the positive strand.
Making use of exonerate we determine that the gene is made up of 4 exons. Moreover, employing fastatranslate we determined the number of aminoacids of the protein studied, which in this case was 95.
T - coffee showed a score of alignment of 985. This value, which is relatively high, indicates a considerable conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict. There are practically no variations between the aminoacids of both sequences. With this T-Coffee we also did not obtain any gap at the start of the protein. Besides, sel K I protein starts with Methionine, which indicates that the initial region of the protein has been predicted properly.
In the output of our protein predicted we observed a “*” which corresponded to an indel in the T-Coffee. However, taking into consideration that both selenocysteines and indels are encoded by a STOP codon, the indel shown in the T-Coffee results could have been a selenocysteine. In order to differentiate the situation we needed to use Seblastian.
Employing Seblastian we manage to detect one selenoprotein and its corresponding selenocysteine. As far as SECIS are concerned, making use of the SECISearch3 program we have been able to determine two SECIS elements, one of them grade A and the other one grade B.
Hence, the existence of selenocysteine plus the presence of SECIS elements indicates that the protein sel K I of our organism of interest is a selenoprotein.
SelK II
In the case of the protein K II no T-blast could be obtained for the following results. An explanation to this could be that this protein is not present in our organism of interest, Centrocercus urophasianus, or that it is very different from Gallus gallus’ protein K II. These two possibilities could have happened due to evolutionary processes by which the organism of interest would have lost or mutated a lot of this protein. Another possibility is that this protein is located in between two scaffolds, and T-blast is not capable of finding where this protein is in Centrocercus urophasianus’’genome.
SelK III
The scaffold that we analyzed for this protein was JAHKSY010000015.1. More precisely, the region studied was between the positions 47126848 - 47126798. Considering the start and the end of this region of the genome and the query, we determined the location in the negative strand.
By using exonerate we were able to determine that the gene is made up of 1 exon. Also, fastatranslate enabled us to establish the number of aminoacids of the protein studied, which in this case was 84.
T - coffee showed a high score, exactly 978, which is close to 1000 and this led to the conclusion that there is a considerable degree of conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict. Nevertheless, some aminoacid variations could be observed in some positions between these proteins. T-Coffee showed a gap at the first part of the predicted protein. The explanation to this could be related to the fact that there has been an indel (deletion or insertion) on the genome of our species or also because the protein may not be well annotated. Besides, T-Coffee enabled us to determine that SelKIII protein does not start with Methionine which means that this part of the protein has not been as properly predicted as we would have wanted.
Employing Seblastian we have not detected any selenoprotein. As far as SECIS are concerned, by using the SECISearch3 program we have been able to determine a grade B SECIS element and grade C SECIS element.
Therefore, bearing in mind that SECIS elements have been found but not selenocysteine, this suggests that currently Centrocercus urophasianus SelKIII is not a selenoprotein. Selenocysteine loss may be due to evolutionary forces.
Selenoprotein O (Sel O)
Selenoprotein O (SelO) is the largest mammalian selenoprotein with orthologs found in a wide range of organisms, including bacteria and yeast. SelO transfers AMP from ATP to Ser, Thr, and Tyr residues on protein substrates (AMPylation), uncovering their previously unrecognized activity[15]. It is suggested that SelO may be a redox-active mitochondrial selenoprotein which interacts with a redox target protein[16].
SelO I
The scaffold that was considered in the study of this protein was JAHKSY010000015.1. Specifically, the region studied was between the positions 18654395 - 18659329. Bearing in mind the start and the end of this region of the genome and the query, we determined the location in the positive strand.
Exonerate enabled us to determine that the gene is made up of 6 exons. Also, using fastatranslate we established the number of aminoacids of the protein studied, which in this case was 361. T - coffee showed a significantly high score, precisely 997, which is close to 1000 and this led to the conclusion that there is a considerable degree of conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict. Nevertheless, some aminoacid variations could be observed in some positions between these proteins. In the output of the protein predicted we could observe a ‘*’ in the position of an aminoacid. This, in the T-Coffee, corresponded to an Indel. Nevertheless, taking into account that both selenocysteines and indels are encoded by a STOP codon, the indel shown could have been a selenocysteine. So as to obtain a solution to this question we needed to use Seblastian. Besides, T-Coffee enabled us to determine that SelOI protein does not start with Methionine which means that this part of the protein has not been as properly predicted as we would have wanted.
Using Seblastian we have detected one selenoprotein. As far as SECIS are concerned, employing the SECISearch3 program we have been able to determine a grade A SECIS element and grade B SECIS element.
Thus, since SECIS elements have been found as well as selenocysteines, this suggests that SelOI protein in Centrocercus is a selenoprotein.
SelO II
The scaffold that was chosen in our project of this protein was JAHKSY010000016.1. Specifically, the positions that we studied were the following 32052060 - 32032928. Taking into consideration the start and the end of this region of the genome and the query, we determined the location in the negative strand.
Exonerate enabled us to determine that the gene is made up of 7 exons. Also, fastatranslate enabled us to establish the number of aminoacids of the protein studied, which in this case was 198. T - coffee showed a high score, exactly 1000 and this led to the conclusion that there is a completely conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict. No variations of amino acids were observed between the sequences studied. Besides, T-Coffee enabled us to determine that SelOII protein does not start with Methionine. This shows us that the initial part of the protein has not been correctly predicted.
Making use of Seblastian we have not detected any selenoprotein. As far as SECIS are concerned, by using the SECISearch3 program we have been able to determine a grade B two SECIS elements.
Therefore, bearing in mind that SECIS elements have been found but not selenocysteine, this suggests that currently Centrocercus urophasianus SelOII is not a selenoprotein. Selenocysteine loss may be due to evolutionary forces.
SelO III
The scaffold that we analyzed for this protein was JAHKSY010000015.1. The positions chosen as the region of interest were the following 18648147 - 18659329. Considering the start and the end of this region of the genome and the query, we established the location in the positive strand.
By using exonerate we were able to determine that the gene is made up of 9 exons. Moreover, fastatranslate enabled us to establish the number of aminoacids of the protein studied, which in this case was 626. T - coffee showed a high score, exactly 998, which is close to 1000 and this led to the conclusion that there is a considerable degree of conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict. Nevertheless, some aminoacid variations could be observed in some positions between these proteins. In the output of our protein predicted a ‘*’ was observed which in the T-Coffee results was shown as an Indel. Nevertheless, since selenocysteines and indels are both encoded by a STOP codon, the indel shown could have been a selenocysteine. In order to obtain a solution to this question we needed to use Seblastian.
Besides, T-Coffee enabled us to determine that SelOIII protein does not start with Methionine which means that this part of the protein has not been as properly predicted as we would have wanted.
Employing Seblastian we have been able to detect one selenoprotein. Regarding SECIS by using the SECISearch3 program we determined the presence of a grade A SECIS element and a B SECIS element.
Thus, since SECIS elements have been found as well as selenocysteines, this suggests that SelOIII protein in Centrocercus is a selenoprotein.
SelO IV
The scaffold that was taken into consideration in the project of this protein was JAHKSY010000015.1. More precisely, the region studied was between the positions 18648219 - 18649726. Bearing in mind, the start and the end of this region of the genome and the query, we determined the location in the positive strand.
By using exonerate we were able to determine that the gene is made up of 2 exons. Also, fastatranslate enabled us to establish the number of aminoacids of the protein studied, which in this case was 182. T - coffee showed a high score, exactly 1000 and this led to the conclusion that there is a considerable degree of conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict. No variations of amino acids were observed between the sequences studied. Besides, T-Coffee enabled us to determine that SelOIV protein does not start with Methionine which means that this part of the protein has not been as properly predicted as we would have wanted.
Employing Seblastian we have detected one selenoprotein. As far as SECIS are concerned, employing the SECISearch3 program we have been able to determine a grade A SECIS element and a B SECIS element.
Thus, since SECIS elements have been found as well as selenocysteines, this suggests that SelO IV protein in Centrocercus is a selenoprotein.
SelH
Selenoprotein H (SelH) is a 14-kDa mammalian nuclear protein involved in redox sensing and transcription[17][18].
The scaffold that we analyzed for this protein was JAHKSY010000033.1. More precisely, the region studied was between the positions 535736 - 535804. Considering the start and the end of this region of the genome and the query, we determined the location in the positive strand.
By using exonerate we were able to determine that the gene is made up of 2 exons. Also, fastatranslate enabled us to establish the number of aminoacids of the protein studied, which in this case was 73. T - coffee showed a high score, exactly 785 and this led to the conclusion that there is a low conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict. Nevertheless, some aminoacid variations could be observed in some positions between these proteins.T-Coffee showed a gap at the first part of the predicted protein. The explanation to this could be related to the fact that there has been an indel (deletion or insertion) on the genome of our species or also because the protein may not be well annotated. In the output of the protein predicted we could observe a ‘*’ in the position of an aminoacid. This, in the T-Coffee, corresponded to an Indel. Nevertheless, taking into account that both selenocysteines and indels are encoded by a STOP codon, the indel shown could have been a selenocysteine. So as to obtain a solution to this question we needed to use Seblastian. Besides, T-Coffee enabled us to determine that SelOH protein does not start with Methionine. This shows us that the initial part of the protein has not been correctly predicted.
Using Seblastian we have not detected any selenoprotein. As far as SECIS are concerned, by using the SECISearch3 program we have been able to determine a grade B two SECIS elements.
Therefore, bearing in mind that SECIS elements have been found but not selenocysteine, this suggests that currently Centrocercus urophasianus SelH is not a selenoprotein. Selenocysteine loss may be due to evolutionary forces.
SelN
Selenoprotein N (SelN) is involved in muscle development and maintenance. It also contributes in the regulation of oxidative stress and calcium homeostasis. It is located in the membrane of the endoplasmic reticulum[19]. Its deficiency causes several inherited neuromuscular disorders (SEPN1-related myopathies)[20].
The scaffold that was considered in the study of this protein was JAHKSY010000043.1. Specifically, the region studied was between the positions 3479082 - 3492054. Considering the start and the end of this region of the genome and the query, we determined the location in the positive strand.
By using exonerate we were able to determine that the gene is made up of 12 exons. Also, fastatranslate enabled us to establish the number of aminoacids of the protein studied, which in this case was 530. T - coffee showed a high score, exactly 998, which is close to 1000 and this led to the conclusion that there is a considerable degree of conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict. Nevertheless, some aminoacid variations could be observed in some positions between these proteins. In the output of the protein predicted we could observe a ‘*’ in the position of an aminoacid. This, in the T-Coffee, corresponded to an Indel. Nevertheless, taking into account that both selenocysteines and indels are encoded by a STOP codon, the indel shown could have been a selenocysteine. So as to obtain a solution to this question we needed to use Seblastian. Besides, T-Coffee enabled us to determine that SelN protein does start with Methionine which indicates a good prediction in this initial part of the protein.
Using Seblastian we have detected one selenoprotein. As far as SECIS are concerned, employing the SECISearch3 program we have been able to determine a grade A SECIS element and a two B SECIS element.
Thus, since SECIS elements have been found as well as selenocysteines, this suggests that SelN protein in Centrocercus is a selenoprotein.
SelT
Selenoprotein T (SelT) is an oxidoreductase localized to the Golgi complex and ER. It manifests a thioredoxin-like fold and it is involved in redox regulation and cell anchorage[21].
The scaffold that we analyzed for this protein was JAHKSY010001038.1. More precisely, the region studied was between the positions 22471 - 18570. Considering the start and the end of this region of the genome and the query, we determined the location in the negative strand.
By using exonerate we were able to determine that the gene is made up of 5 exons.Also, fastatranslate enabled us to establish the number of aminoacids of the protein studied, which in this case was 199. T - coffee showed a high score, exactly 997, which is close to 1000 and this led to the conclusion that there is a considerable degree of conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict. Nevertheless, some aminoacid variations could be observed in some positions between these proteins. In the output of the protein predicted we could observe a ‘*’ in the position of an aminoacid. This, in the T-Coffee, corresponded to an Indel. Nevertheless, taking into account that both selenocysteines and indels are encoded by a STOP codon, the indel shown could have been a selenocysteine. So as to obtain a solution to this question we needed to use Seblastian. Besides, T-Coffee enabled us to determine that SelT protein does start with Methionine which indicates a good prediction in this initial part of the protein.
Applying Seblastian we have detected one selenoprotein. As far as SECIS are concerned, employing the SECISearch3 program we have been able to determine a grade A SECIS element.
Thus, since SECIS elements have been found as well as selenocysteines, this suggests that SelT protein in Centrocercus is a selenoprotein.
Moreover, this protein has had to be analysed manually as the program does not filter tblastn positions’ by e-value, which can lead to fastasubseq errors.
Sel15
Selenoprotein 15 (Sel15) is a thiol-disulfide oxidoreductase, as it is SEl M. This protein is expressed in the Endoplasmic reticulum and is involved in controlling that protein folding takes place correctly [1].
The scaffold that we analyzed for this protein was JAHKSY010000018.1. More precisely, the region studied was between the positions 15344034 - 15360438. Considering the start and the end of this region of the genome and the query, we determined the location in the positive strand.
By using exonerate we were able to determine that the gene is made up of 4 exons. Also, fastatranslate enabled us to establish the number of aminoacids of the protein studied, which in this case was 137. T - coffee showed a high score, exactly 995, which is close to 1000 and this led to the conclusion that there is a considerable degree of conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict. Nevertheless, some aminoacid variations could be observed in some positions between these proteins. In the output of the protein predicted we could observe a ‘*’ in the position of an aminoacid. This, in the T-Coffee, corresponded to an Indel. Nevertheless, taking into account that both selenocysteines and indels are encoded by a STOP codon, the indel shown could have been a selenocysteine. So as to obtain a solution to this question we needed to use Seblastian. Besides, T-Coffee enabled us to determine that Sel15 protein does not start with Methionine which means that this part of the protein has not been as properly predicted as we would have wanted.
Applying Seblastian we have detected one selenoprotein. As far as SECIS are concerned, employing the SECISearch3 program we have been able to determine a grade A SECIS element.
Thus, since SECIS elements have been found as well as selenocysteines, this suggests that Sel15 protein in Centrocercus is a selenoprotein.
MACHINERY
SPS1
The scaffold that we analyzed for this protein was JAHKSY010000015.1. More precisely, the region studied was between the positions 5641485 - 5621879. Considering the start and the end of this region of the genome and the query, we determined the location in the negative strand.
By using exonerate we were able to determine that the gene is made up of 8 exons. Also, fastatranslate enabled us to establish the number of aminoacids of the protein studied, which in this case was 397. T - coffee showed a high score, exactly 1000 and this led to the conclusion that there is a completely conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict. No variations of amino acids were observed between the sequences studied. Besides, T-Coffee enabled us to determine that SPS1 protein does start with Methionine which indicates a good prediction in this initial part of the protein.
As we expected, it does not contain a Sec since it is a machinery protein and not a selenoprotein itself. In contrast, Seblastian was able to predict a grade B two SECIS elements and grade C two SECIS elements. Even so, the score of T-coffee was good enough to afirm that SPS1 protein is a Cys-homolog conserved and well-aligned in C. urophasianus.
SBP2 I
The scaffold that we analyzed for this protein was JAHKSY010000023.1. More precisely, the region studied was between the positions 9506913 - 9520272. Considering the start and the end of this region of the genome and the query, we determined the location in the positive strand.
By using exonerate we were able to determine that the gene is made up of 16 exons. Also, fastatranslate enabled us to establish the number of aminoacids of the protein studied, which in this case was 1090. T - coffee showed a high score, exactly 1000, and this led to the conclusion that there is a considerable degree of conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict. No variations of amino acids were observed between the sequences studied. Besides, T-Coffee enabled us to determine that SBP2 I protein does not start with Methionine which means that this part of the protein has not been as properly predicted as we would have wanted.
As expected, it has no SECIS elements neither selenoprotein predicted with Seblatian, because it is part of the machinery and it is not a selenoprotein itself.
SBP2 II
The scaffold that we analyzed for this protein was JAHKSY010000021.1.More precisely, the region studied was between the positions 21378408 - 21405747. Considering the start and the end of this region of the genome and the query, we determined the location in the positive strand.
By using exonerate we were able to determine that the gene is made up of 18 exons. Also, fastatranslate enabled us to establish the number of aminoacids of the protein studied, which in this case was 877. T - coffee showed a high score, exactly 997, which is close to 1000 and this led to the conclusion that there is a considerable degree of conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict. Nevertheless, some aminoacid variations could be observed in some positions between these proteins. T-Coffee showed some gaps at the end of the predicted protein. The explanation to this could be related to the fact that there has been a deletion on the genome of our species or also because the protein may not be well annotated. Besides, T-Coffee enabled us to determine that SBP2II protein does not start with Methionine. This shows us that the initial part of the protein has not been correctly predicted.
As we expected, it does not contain a Sec since it is a machinery protein and not a selenoprotein itself. In contrast, Seblastian was able to predict a grade B SECIS element and grade A SECIS element. Even so, the score of T-coffee was good enough to afirm that SBP2II protein is a Cys-homolog conserved and well-aligned in C. urophasianus.
SBP2 III
The scaffold that was chosen in our project of this protein was JAHKSY010000023.1. Specifically, the region studied was between the positions 9518933 - 9519151. Taking into consideration the start and the end of this region of the genome and the query, we determined the location in the positive strand.
Exonerate enabled us to establish that the gene is made up of 1 exon. Also, fastatranslate enabled us to establish the number of aminoacids of the protein studied, which in this case was 73. T - coffee showed a high score, exactly 1000 and this led to the conclusion that there is a considerable degree of conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict. No variations of amino acids were observed between the sequences studied. Besides, T-Coffee enabled us to determine that SBP2III protein does not start with Methionine which means that this part of the protein has not been as properly predicted as we would have wanted.
As expected, it has no SECIS elements neither selenoprotein predicted with Seblatian, because it is part of the machinery and it is not a selenoprotein itself.
SECp43
The scaffold that was taken into consideration in the project was JAHKSY010000043.1. Precisely, the region studied was between the positions 3209233- 3221322. Considering the start and the end of this region of the genome and the query, we determined the location in the positive strand.
By using exonerate we were able to determine that the gene is made up of 9 exons. Also, fastatranslate enabled us to establish the number of aminoacids of the protein studied, which in this case was 353. T - coffee showed a high score, exactly 1000 and this led to the conclusion that there is a considerable degree of conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict. No variations of amino acids were observed between the sequences studied. Besides, T-Coffee enabled us to determine that SECp43 protein does not start with Methionine. This shows us that the initial part of the protein has not been correctly predicted.
As we expected, it does not contain a Sec since it is a machinery protein and not a selenoprotein itself. In contrast, Seblastian was able to predict a grade B seventeen SECIS elements, a grade A SECIS element and a grade C two SECIS elements. Even so, the score of T-coffee was good enough to afirm that SECp43 protein is a Cys-homolog conserved and well-aligned in C. urophasianus.
SecS I
The scaffold taken into account for SecSI protein was JAHKSY010000013.1.More precisely, the region studied was between the positions 16884856 - 16877546. Considering the start and the end of this region of the genome and the query, we determined the location in the negative strand.
By using exonerate we were able to determine that the gene is made up of 4 exons. Also, fastatranslate enabled us to establish the number of aminoacids of the protein studied, which in this case was 165. T - coffee showed a high score, exactly 1000 and this led to the conclusion that there is a considerable degree of conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict. No variations of amino acids were observed between the sequences studied. Besides, T-Coffee enabled us to determine that SecSI protein does not start with Methionine which means that this part of the protein has not been as properly predicted as we would have wanted.
As we expected, it does not contain a Sec since it is a machinery protein and not a selenoprotein itself. In contrast, Seblastian was able to predict a grade B SECIS element and grade A SECIS element. Even so, the score of T-coffee was good enough to afirm that SecSI protein is a Cys-homolog conserved and well-aligned in C. urophasianus.
SecS II
The scaffold that we analyzed for this protein was JAHKSY010000013.1. More precisely, the region studied was between the positions 16887429 - 16866106. Considering the start and the end of this region of the genome and the query, we determined the location in the negative strand.
By using exonerate we were able to determine that the gene is made up of 11 exons. Also, fastatranslate enabled us to establish the number of aminoacids of the protein studied, which in this case was 466. T - coffee showed a high score, exactly 1000 and this led to the conclusion that there is a considerable degree of conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict. No variations of amino acids were observed between the sequences studied. Besides, T-Coffee enabled us to determine that SecSII protein does start with Methionine which indicates a good prediction in this initial part of the protein.
As we expected, it does not contain a Sec since it is a machinery protein and not a selenoprotein itself. In contrast, Seblastian was able to predict a grade B SECIS element.Even so, the score of T-coffee was good enough to afirm that SecSII protein is a Cys-homolog conserved and well-aligned in C. urophasianus.
Pstk
The scaffold taken into consideration in our project was JAHKSY010000017.1.More precisely, the region studied was between the positions 3962201 - 3959660. Considering the start and the end of this region of the genome and the query, we determined the location in the positive strand.
By using exonerate we were able to determine that the gene is made up of 6 exons. Also, fastatranslate enabled us to establish the number of aminoacids of the protein studied, which in this case was 353. T - coffee showed a high score, exactly 996, which is close to 1000 and this led to the conclusion that there is a considerable degree of conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict. Nevertheless, some aminoacid variations could be observed in some positions between these proteins. T-Coffee showed some gaps at predicted protein. The explanation to this could be related to the fact that there has been a deletion on the genome of our species or also because the protein may not be well annotated. Besides, T-Coffee enabled us to determine that Pstk protein does start with Methionine which indicates a good prediction in this initial part of the protein.
As expected, it has no SECIS elements neither selenoprotein predicted with Seblatian, because it is part of the machinery and it is not a selenoprotein itself.
Furthermore, we have had to analyse this protein manually, as the program does not filter positions in the tblastn output by e-value, which can lead to fastasubseq errors as it cannot precisely determine $start nor $length values.
Eefsec
The scaffold that we analyzed for this protein was JAHKSY010000022.1. More precisely, the region studied was between the positions 10330087 - 10442583. Considering the start and the end of this region of the genome and the query, we determined the location in the positive strand.
By using exonerate we were able to determine that the gene is made up of 8 exons. Also, fastatranslate enabled us to establish the number of aminoacids of the protein studied, which in this case was 532. T - coffee showed a high score, exactly 990, which is close to 1000 and this led to the conclusion that there is a considerable degree of conservation between the protein of our reference organism (Gallus gallus) and the protein that we manage to predict. Nevertheless, some aminoacid variations could be observed in some positions between these proteins. T-Coffee showed some gaps at the end of the predicted protein. The explanation to this could be related to the fact that there has been a deletion on the genome of our species or also because the protein may not be well annotated. Besides, T-Coffee enabled us to determine that eEFsec protein does not start with Methionine which means that this part of the protein has not been as properly predicted as we would have wanted.
As we expected, it does not contain a Sec since it is a machinery protein and not a selenoprotein itself. In contrast, Seblastian was able to predict a grade B three SECIS element. Even so, the score of T-coffee was good enough to afirm that eEFsec protein is a Cys-homolog conserved and well-aligned in C. urophasianus.
Conclusions
In general, our program has been able to predict the most part of our proteins and we have obtained good alignments. However, it does not fit well for small scaffolds, as it just considers three possibilities when giving a value to the $start and $lenght variables in the fastasubseq command:
The protein's DNA sequence has 50000 nucleotides upstream the start and downstream the end.
The protein's DNA sequence does not have 50000 nucleotides upstream the start but it has 50000 nucleotides downstream the end.
The protein's DNA sequence has 50000 nucleotides upstream the start but not downstream the end.
In fact, Gpx8 is the only protein that does not fit in any of these situations, as it does not have 50000 nucleotides upstream nor downstream the start and the end, respectively.
In addition, when we have to give a value to $start and $lenght variables in the fastasubseq command, the script does not sort the positions by e-value. So, the most part of the proteins that have had to be analysed manually could be analysed automatically if the program had somehow taken the e-value into account.
In conclusion, we could add in the script an “if” statement that can work for short scaffolds, even if the protein’s DNA sequence does not have 50000 nucleotides upstream and downstream. Also, we could add a sorting command for e-values to get the best positions to perform the fastasubseq command propertly.
Lastly, our program works well when we work in “~/Documents” at our university computers, but we could have asked the user where to run the program by adding the command “read $variable”. Even so, we can manually change all the paths by replacing “~/Documents” for our path, which can be easily done with the “replace” tool, present in many text editors.
Roman M, Jitaru P, Barbante C. Selenium biochemistry and its role for human health. Metallomics. 2014;6(1):25–54.
Hatfield, D. L., Tsuji, P. A., Carlson, B. A., et al. Selenium and selenocysteine: roles in cancer, health, and development. Trends in biochemical sciences. 2014; 39(3), 112–120.
Shchedrina, V. A., Novoselov, S. V., Malinouski, M. Y., et al. Identification and characterization of a selenoprotein family containing a diselenide bond in a redox motif. Proceedings of the National Academy of Sciences of the United States of America. 2007; 104(35), 13919–13924.
Alexey V. Lobanov, Dolph L et al. Eukaryotic selenoproteins and selenoproteomes. Biochimica et Biophysica Acta (BBA) - General Subjects. 2009; 1790 (11), 1424-1428.
Zhang Y, Roh YJ, Han S-J, et al. Role of Selenoproteins in Redox Regulation of Signaling and the Antioxidant System: A Review. Antioxidants. 2020; 9(5):383.
Lee, B. C., Dikiy, A., Kim, H. Y., et al. Functions and evolution of selenoprotein methionine sulfoxide reductases. Biochimica et biophysica acta. 20091790(11), 1471–1477.
Hamid S., Yang J., Zhao X. et al. Selenoprotein-U (SelU) knockdown triggers autophagy through PI3K–Akt–mTOR pathway inhibition in rooster Sertoli cells. Metallomics. 2018; 10(7), 929-940.
Shetty S, Copeland PR. Molecular mechanism of selenoprotein P synthesis. Biochim Biophys Acta - Gen Subj. 2018;1862(11):2506–2510.
Turanov AA, Xu XM, Carlson BA, et al. Biosynthesis of selenocysteine, the 21st amino acid in the genetic code, and a novel pathway for cysteine biosynthesis. Adv Nutr. 2011;2(2):122-128.
Turanov, A.A., Xu, X., Carlson, B.A., Yoo, et al. Biosynthesis of selenocysteine, the 21st amino acid in the genetic code, and a novel pathway for cysteine biosynthesis. Advances in nutrition. 2011; 2 2, 122-128.
Greater Sage-Grouse | Species Information [Internet]. [cited 2021 Dec 2]. Available from: https://www.fws.gov/greatersagegrouse/speciesinfo.php
Greater Sage-Grouse | Audubon Field Guide [Internet]. [cited 2021 Dec 2]. Available from: https://www.audubon.org/field-guide/bird/greater-sage-grouse
Greater Sage-Grouse Range Map, All About Birds, Cornell Lab of Ornithology [Internet]. [cited 2021 Dec 2]. Available from: https://www.allaboutbirds.org/guide/Greater_Sage-Grouse/maps-range
Verma S, Hoffmann FW, Kumar M, Huang Z, Roe K, Nguyen-Wu E, Hashimoto AS, Hoffmann PR. Selenoprotein K knockout mice exhibit deficient calcium flux in immune cells and impaired immune responses. J Immunol 2011;186(4):2127-37.
Sreelatha A, Yee SS, Lopez VA, Park BC, Kinch LN, Pilch S, et al. Protein AMPylation by an Evolutionarily Conserved Pseudokinase. Cell 2018; 175(3):809-821.
Han SJ, Lee BC, Yim SH, Gladyshev VN, Lee SR. Characterization of mammalian selenoprotein o: a redox-active mitochondrial protein. PLoS One 2014; 9(4):e95518.
Novoselov SV, Kryukov GV, Xu XM, Carlson BA, Hatfield DL, Gladyshev VN. Selenoprotein H is a nucleolar thioredoxin-like protein with a unique expression pattern. J Biol Chem 2007;282(16):11960-8.
Panee J, Stoytcheva ZR, Liu W, Berry MJ. Selenoprotein H is a redox-sensing high mobility group family DNA-binding protein that up-regulates genes involved in glutathione synthesis and phase II detoxification. J Biol Chem 2007;282(33):23759-65.
Lescure A, Rederstorff M, Krol A, Guicheney P, Allamand V. Selenoprotein function and muscle disease. Biochim Biophys Acta 2009;1790(11):1569-74.
Castets P, Lescure A, Guicheney P, Allamand V. Selenoprotein N in skeletal muscle: from diseases to function. J Mol Med 2012;90(10):1095-107.
Boukhzar L, Hamieh A, Cartier D, Tanguy Y, Alsharif I, Castex M, et al. Selenoprotein T Exerts an Essential Oxidoreductase Activity That Protects Dopaminergic Neurons in Mouse Models of Parkinson's Disease. Antioxid Redox Signal 2016; 24(11): 557-74.
Firstly, we would like to thank all the professors that have taught and helped us in this subject and, above all, in this project.
We would also like to thank our colleague Júlia Terzulli, since she has helped us without hesitation when we got stuck on many occasions.
Finally, we could not finish this project without thanking our tutor Marina Ruiz-Romero, as she has showed us how to really work with programs and how to deal with syntax errors, unknown paths, empty folders and invalid residues.

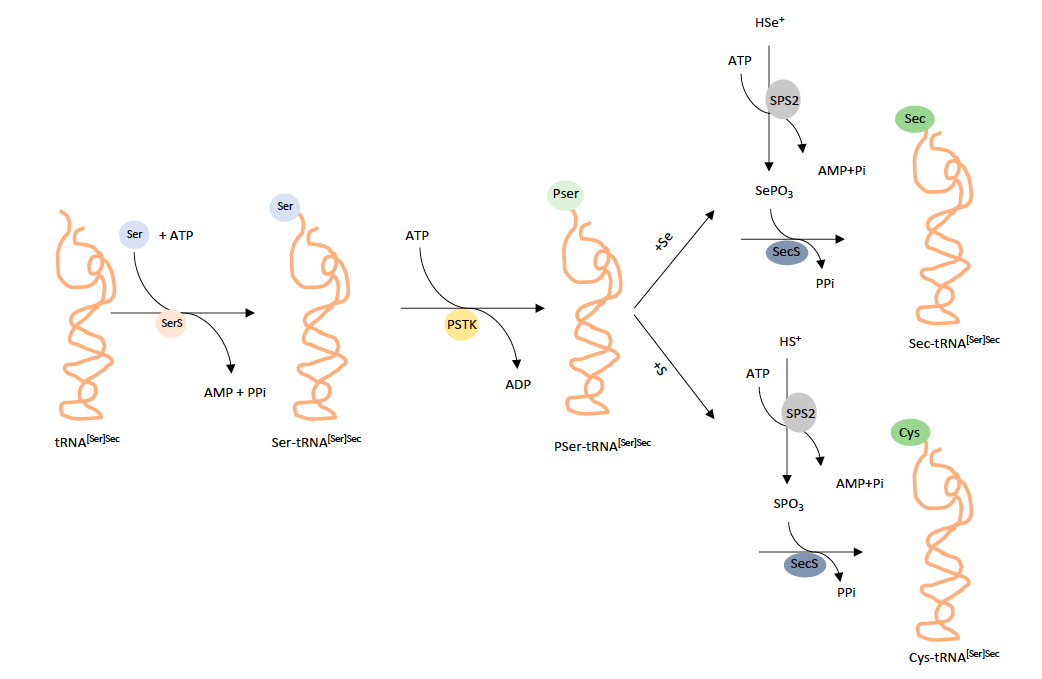

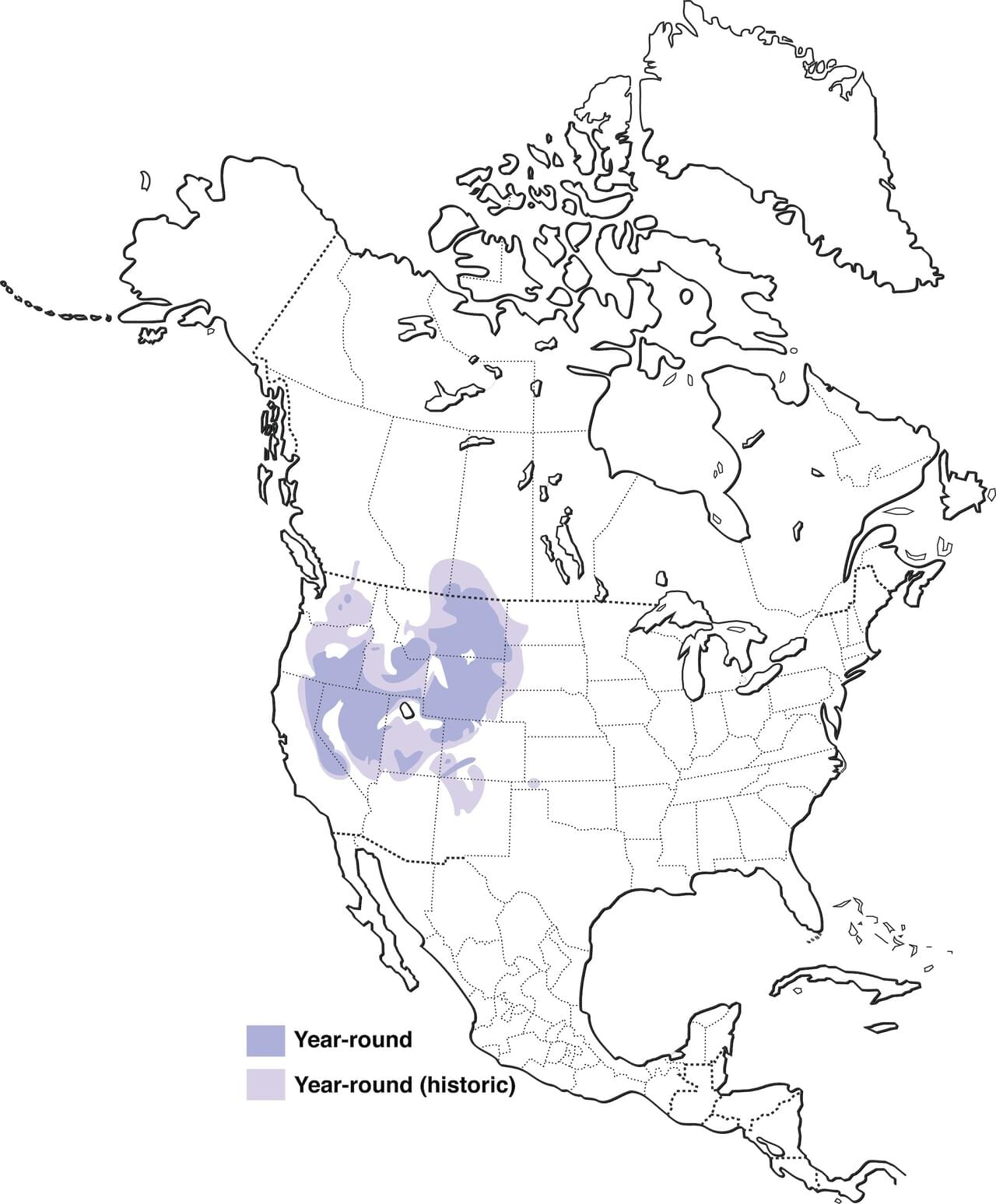 Figure 3:Centrocercus urophasianus distribution [13]
Figure 3:Centrocercus urophasianus distribution [13]
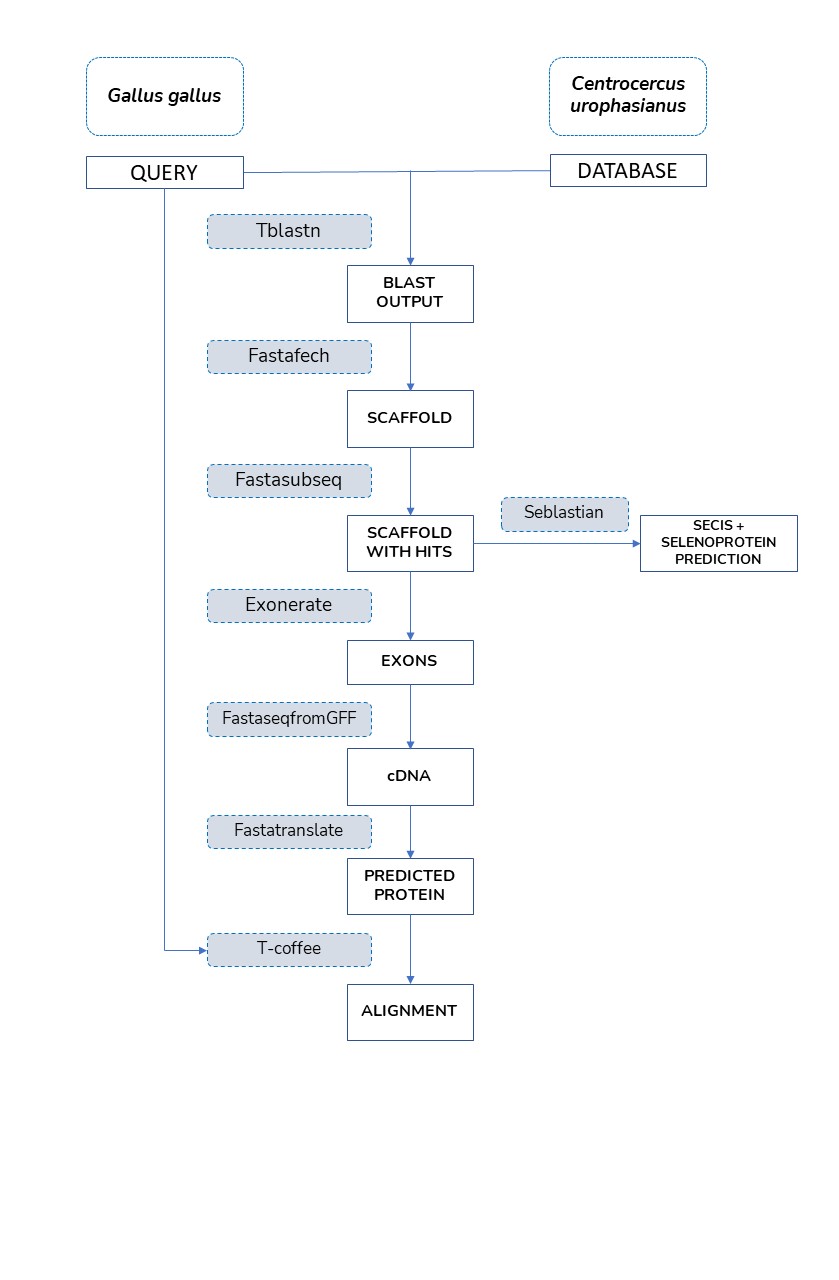



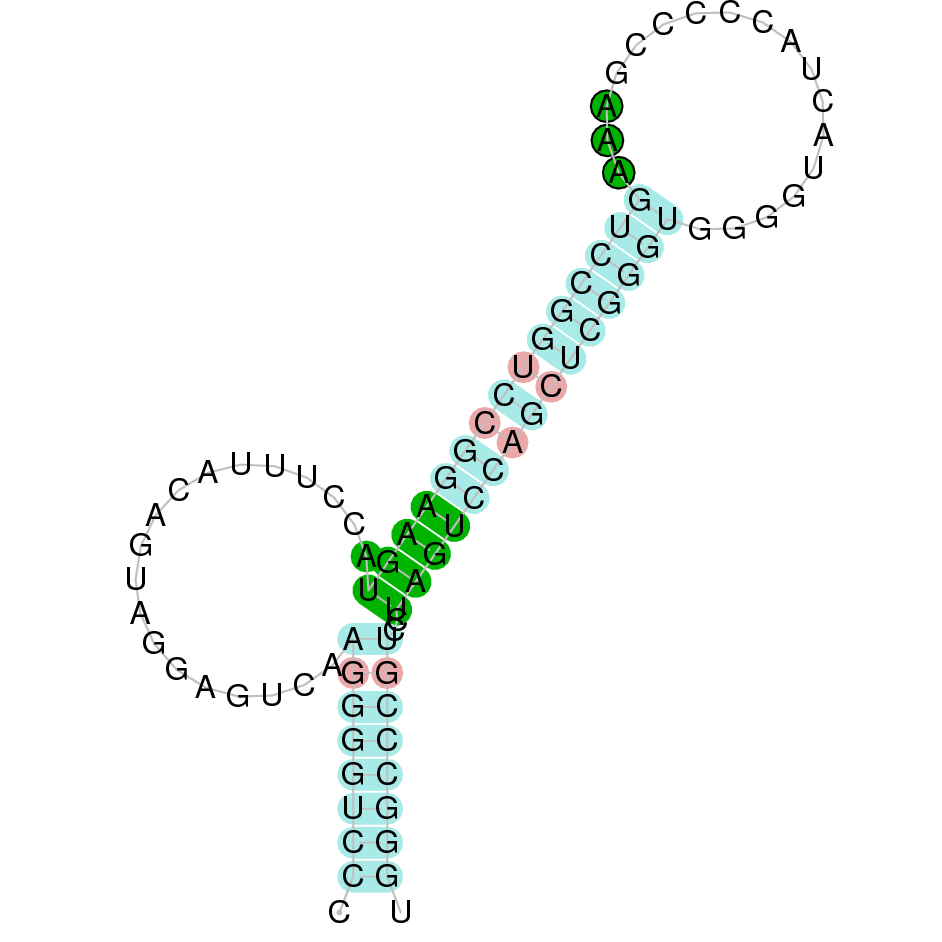{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
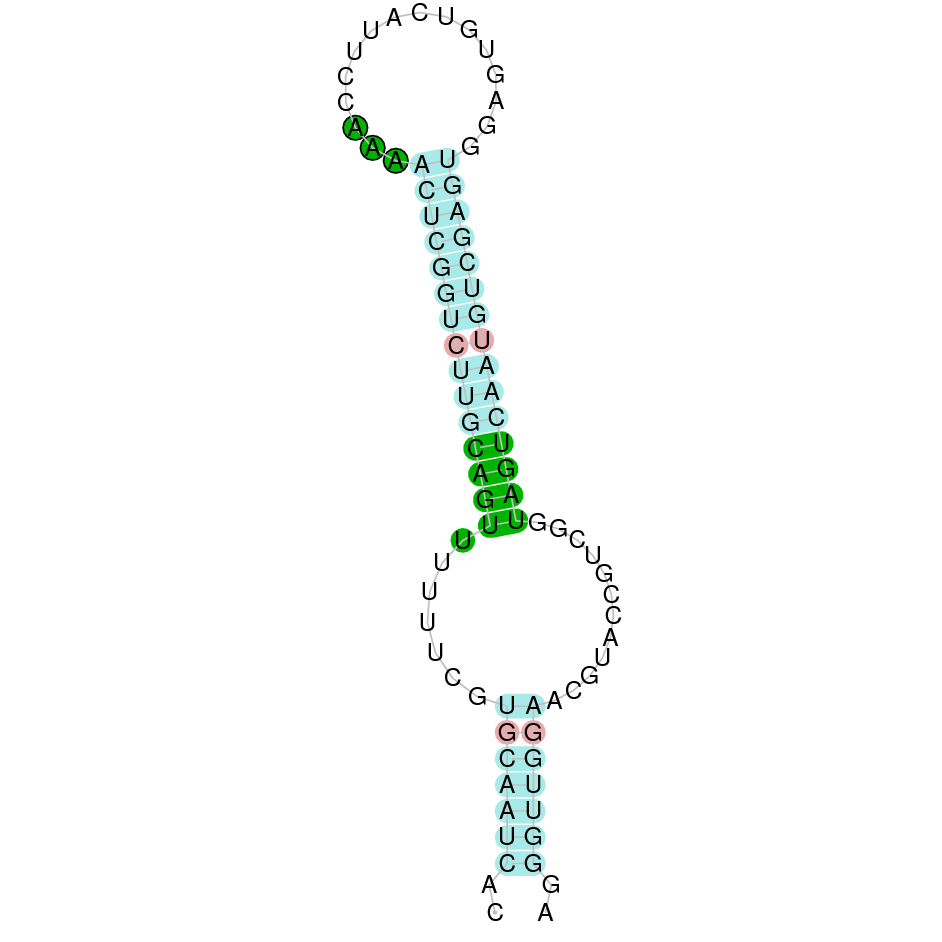{kind=link}
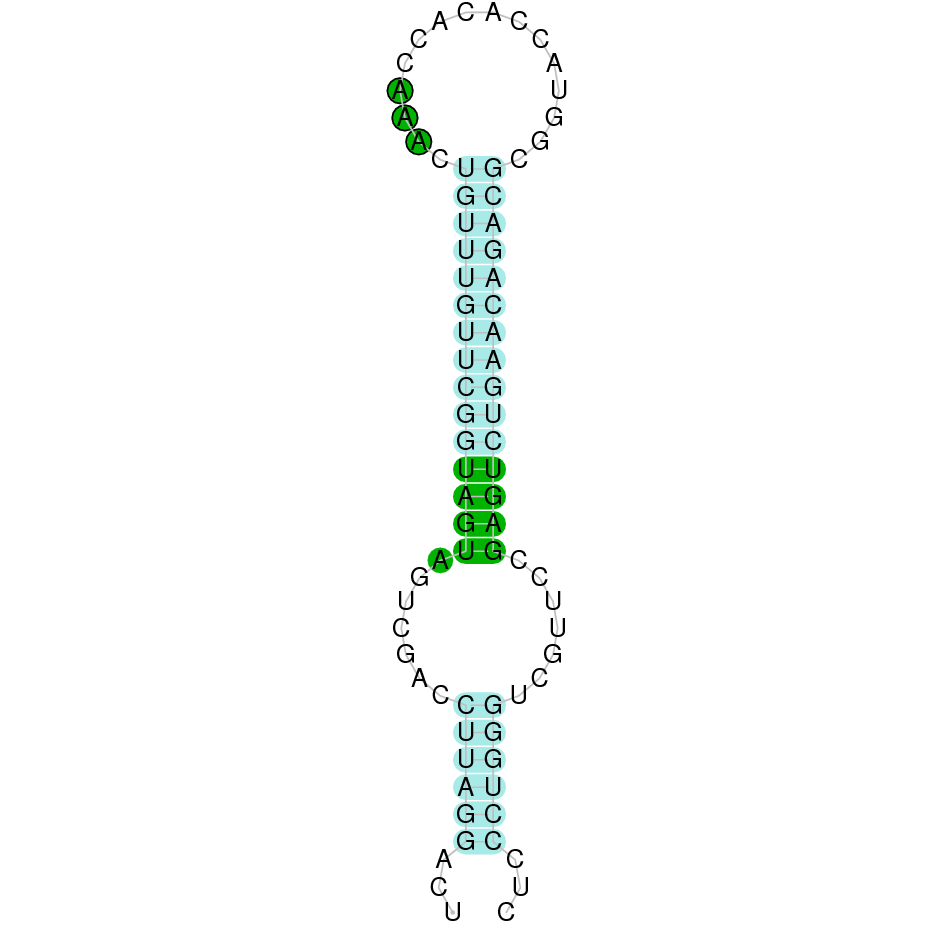{kind=link}
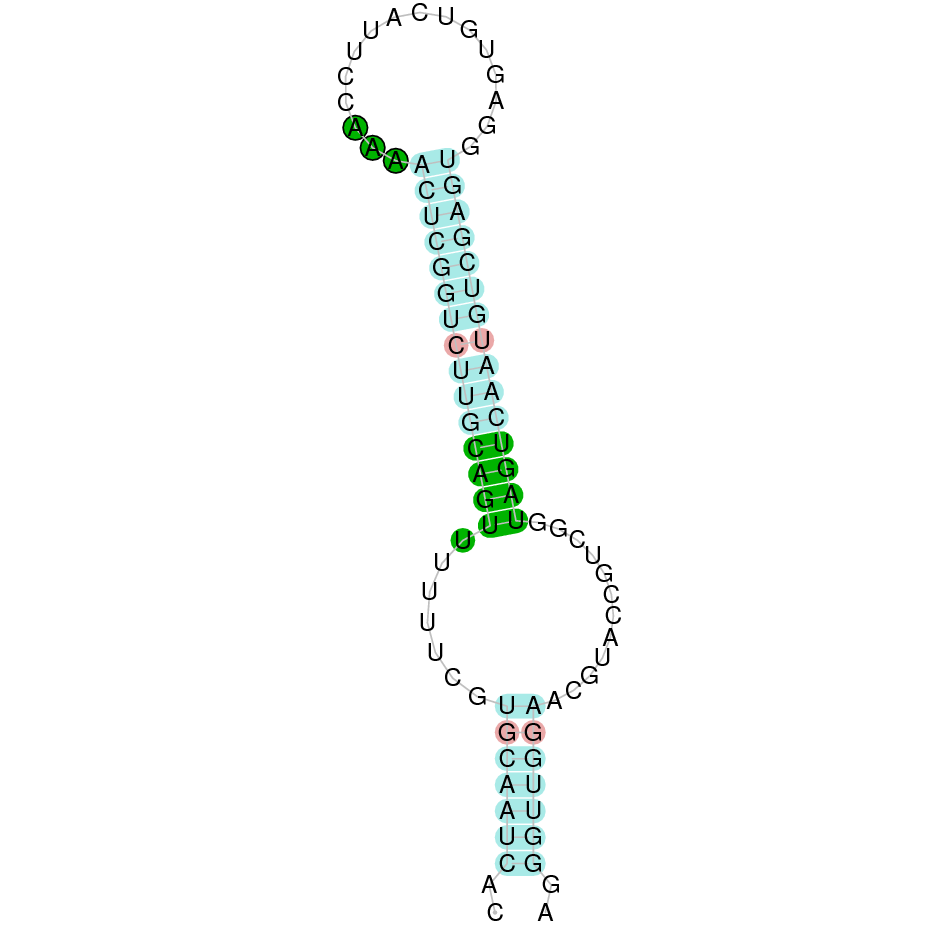{kind=link}
{kind=link}
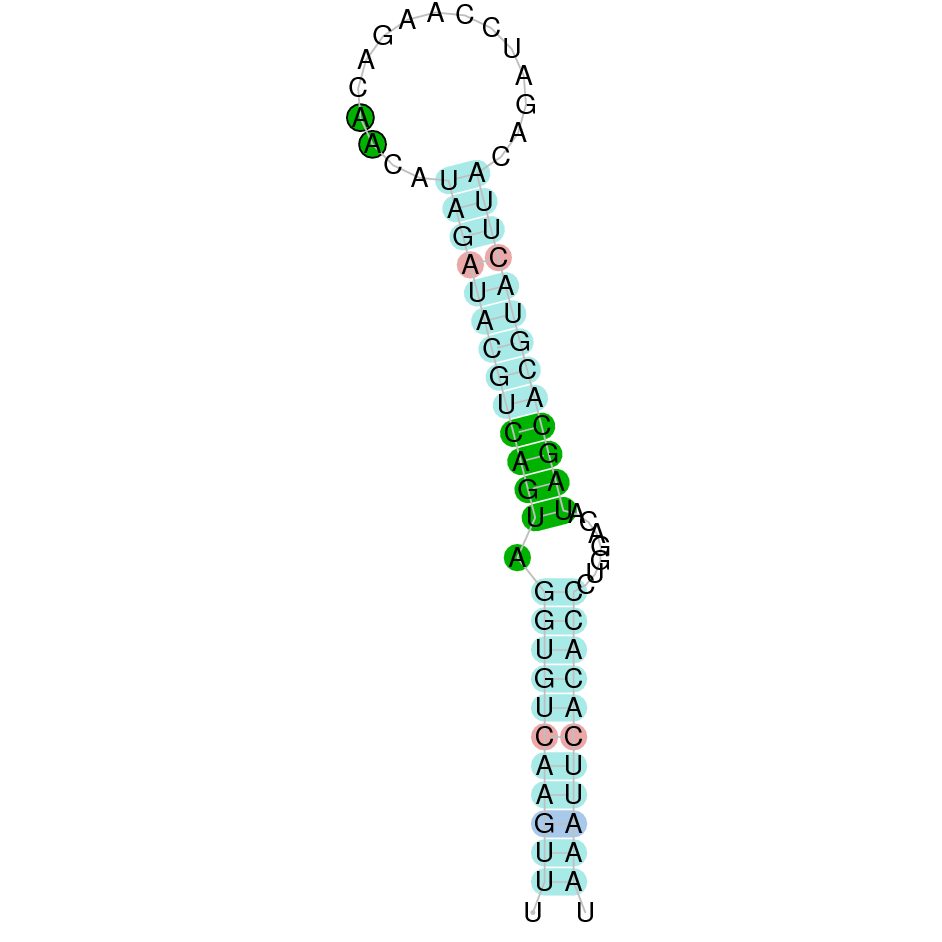{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
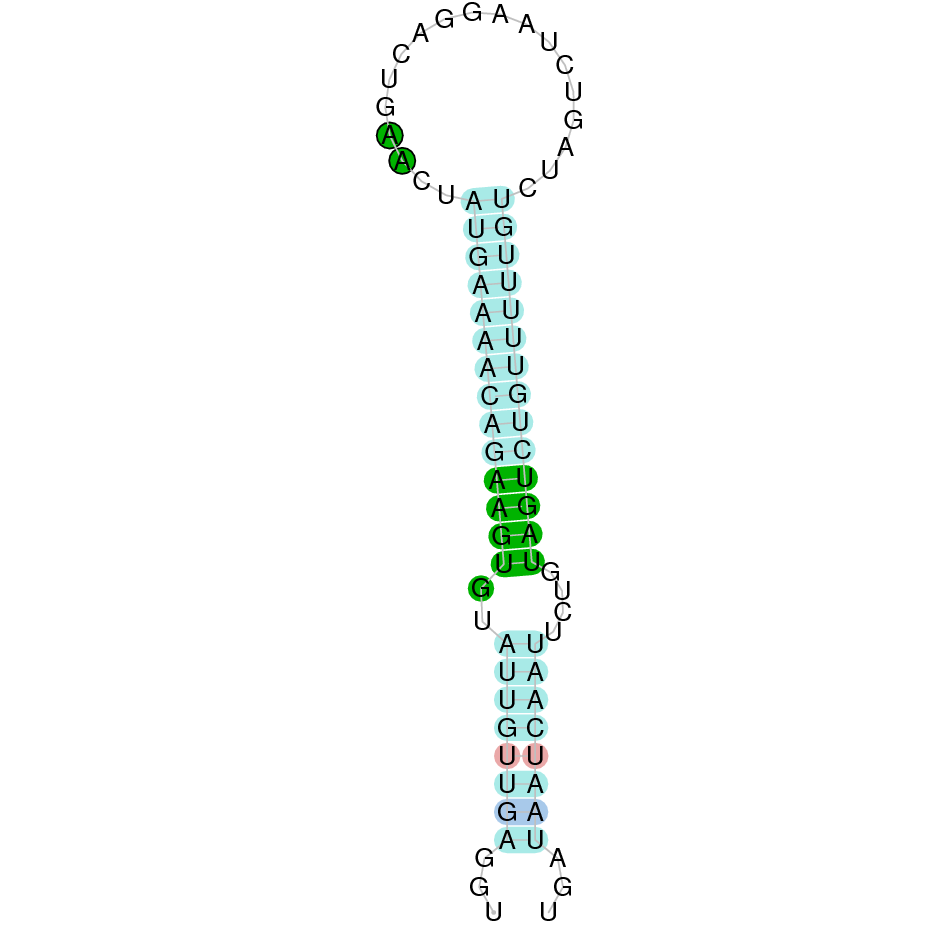{kind=link}
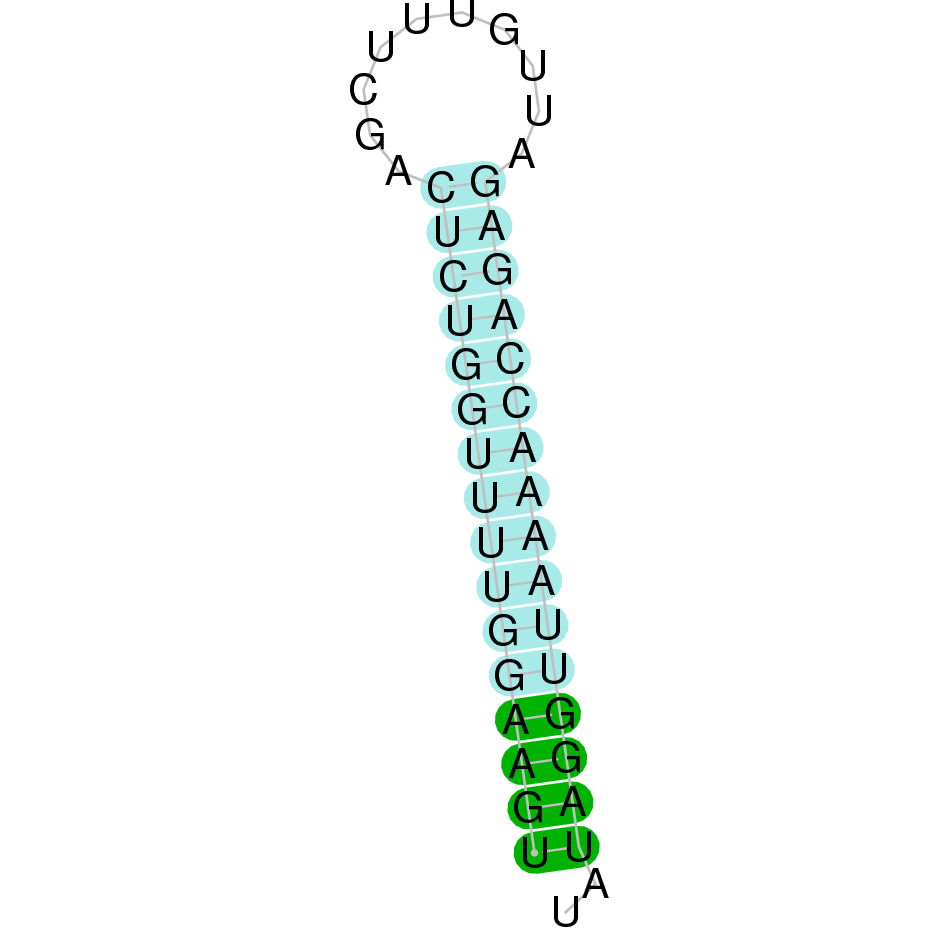{kind=link}
{kind=link}
{kind=link}
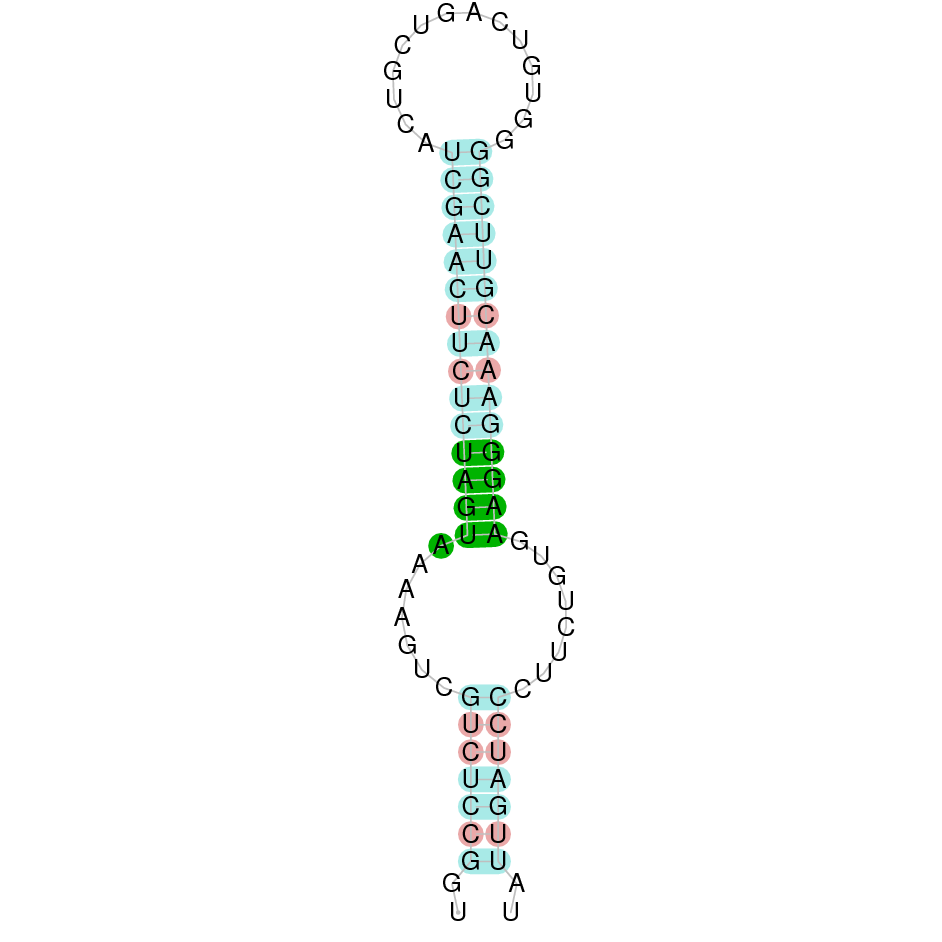{kind=link}
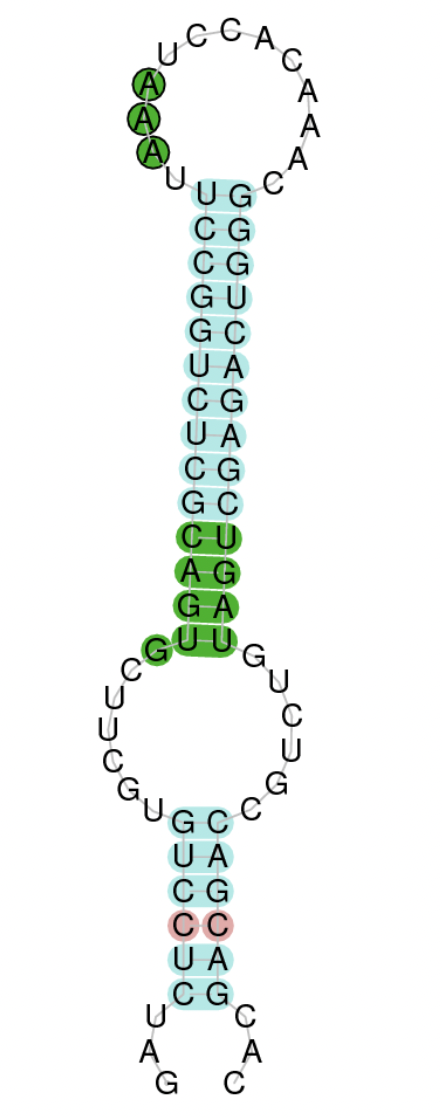{kind=link}
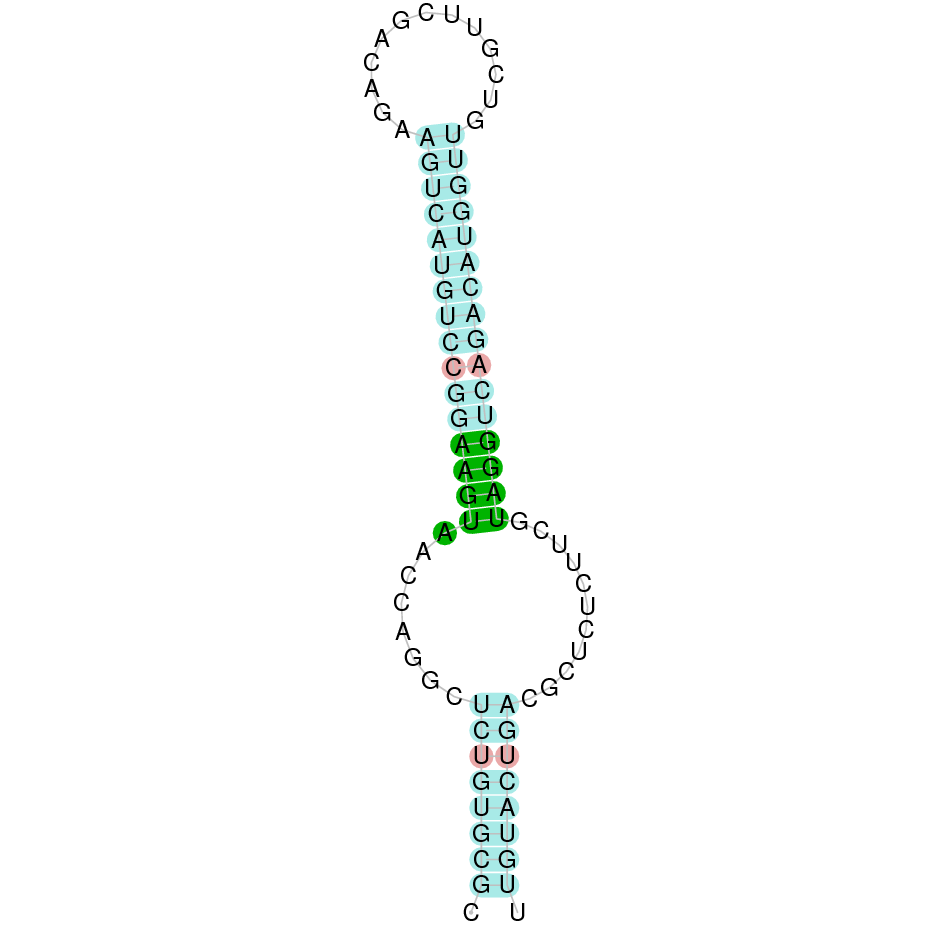{kind=link}
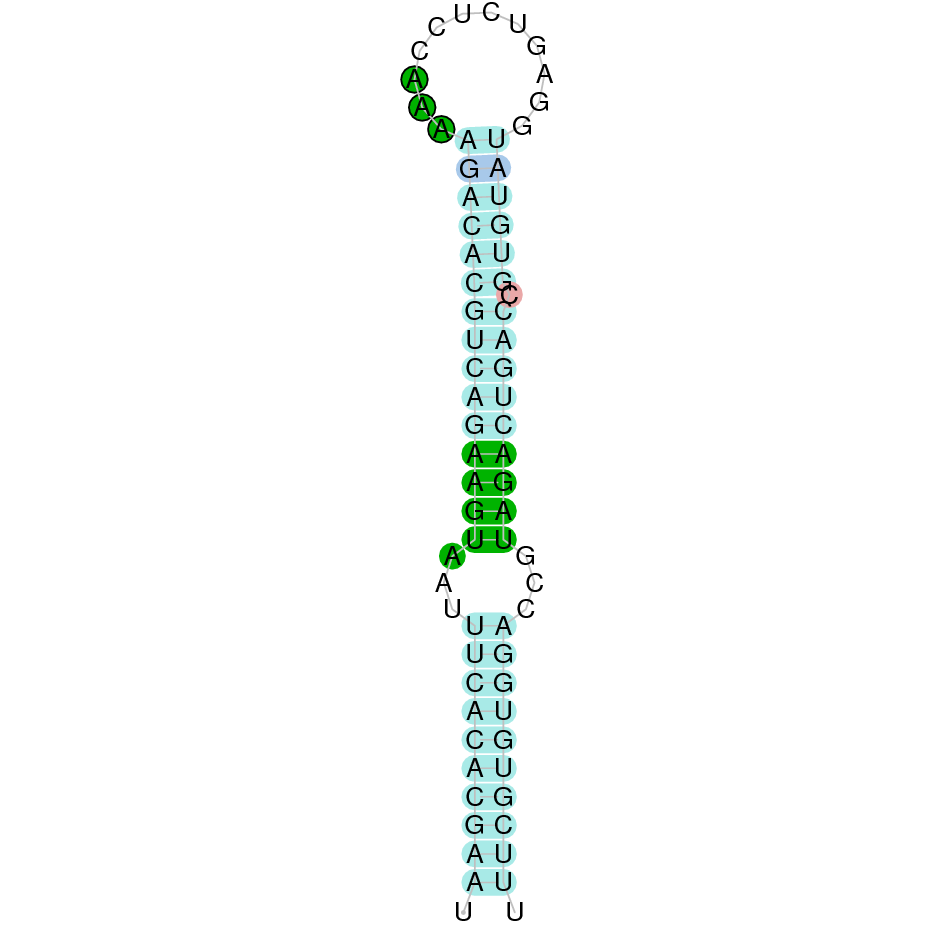{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}