
|
|
|
|
|
|
|
|
|
| |
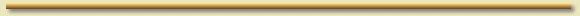
L'objectiu d'aquest treball és revisar els conceptes claus de l'estructura genòmica i dels gens eucariotes, per tal d'entendre l'anotació dels genomes.
L'anotació consisteix en una descripció i localització dels gens, així com altres característiques biològicament rellevants de les seqüències genòmiques. Es tracta de definir les coordenades genòmiques (posició dels nucleòtids al llarg de la seqüències d'ADN) d'elements biològics d'interès, com per exemple gens o elements promotors.
L'objectiu és doncs, intentar comprendre què ens aporta el projecte d'anotació genòmica, i el que és més important, el què encara no ofereix.

Abans de començar, cal fer un breu repàs dels conceptes que aniran sortint. Podrà ser d'utilitat per entendre el treball i lligar els diferents mètodes informàtics que s'aniran utilitzant amb la biologia subjacent.
Per passar de l'informació continguda a la seqüència nucleotídica d'un genoma fins a la seqüència aminoacídica de la proteïna per la qual codifica, el material genètic ha de patir una sèrie de processos.
En primer lloc, es fa la transcripció. És el procés mitjançant el qual es passa de la seqüència de DNA genòmic fins l'mRNA. El primer pas consisteix en la transcripció de l'anomenat transcrit primari. Aquest, que encara conté els introns, haurà de patir una sèrie de modificacions, abans de passar a transcrit secundari o mRNA per d'aquí poder ser traduït a la seqüència proteica. Aquests passos són:
En aquest punt, doncs, l'estructura del transcrit consta de:
Els UTRs (untranslated regions) són seqüències no codificants que flanquegen la regió gčnica pròpiament dita. Aquestes regions contenen seqüències senyal que seran necessàries per la correcta traducció proteica. Els UTRs són presents a l'mRNA, i per tant també es trobaran, o els esperaríem trobar en la seqüència genòmica inicial.
A partir de l'mRNA, l'últim pas consistirà en la traducció. Serà el pas de la seqüència nucleotídica a la seqüència aminoacídica final. S'ha d'apuntar també, que després de la traducció, la proteïna sofrirà modificacions post-traduccionals que la faran activa del tot.
Sens dubte, la recent seqüenciació del genoma humà, així com de les d'altres espècies, ha obert tot un camp de la recerca biomèdica que fins ara era desconegut. Ha permès que, a hores d'ara, la bioinformàtica es converteixi en l'àrea estrella de les investigacions del segle XXI. Aquesta permetrà, entre moltes d'altres coses, comprendre com funcionen processos genòmics fins ara impossibles de predir al laboratori com la regulació de l'splicing alternatiu, el control de la transcripció, el rol del material intergènic i la funció dels RNAs no codificants, etc. Al capdavall, doncs, la utilització d'eines computacionals permetran un gran avenç de la ciència.
Entre moltes d'altres opcions, una de les eines mes útils que a hores d'ara s'està treballant és la creació de diferents bases de dades a on es van anotant tots els genomes i totes les proteïnes que, de mica en mica, es van descobrint. La idea és acabar amb una base de dades que reculli la seqüència, tant parcial (amb l'anotació proteica) com global (genoma sencer) de diferents organismes. Un cop això estigui fet, el treball que es podrà fer en base aquestes dades serà infinit.
S'ha de pensar que la seqüenciació genòmica és una font d'informació que fins ara cap biòleg hi havia tingut accés. Però el valor d'aquest genoma només serà bo si la seva annotació és bona. Les eines i els recursos per anotar s'estan desenvolpant ràpidament i la comunitat científica cada cop es torna més dependent d'aquesta informació. Cal doncs que sigui fidedigne.
L'anotació purament dita és el procés d'agafar la seqüència d'ADN produïda pels projectes de seqüenciació genòmica i, afegint l'anàlisi i la interpretació necessària, extreure'n la seva significància biològica i col.locar-la en el context dels processos biològics que coneixem. Per tant, no es tracta de trobar la col.locació dels nucleòtids A, C, G o T, sinó el significat de trobar-los en un ordre determinat.
El procés d'anotació comença amb la seqüenciació per part d'un investigador d'un genoma. És un FASTA FILE de tres mil milions de parell de bases enregistrades en l'espai equivalent a 5 CD-ROMS. Per tal d'anotar-l'ho, hi han moltes eines informàtiques que poden ser de gran utilitat per treure la màxima informació possible a la seqüència. Per bé que no hi ha un ordre establert, en el procés d'anotació, convé començar pels trets més bàsics i anar recopilant informació a mesura que avança la investigació. Per exemple, passos obligats serien:
De totes maneres, els programes informàtics no deixen de ser programes i per tant no utilitzaran tots els recursos encara desconeguts de que disposen les cèl.lules. Això vol dir que la seva utilització és necessària però sempre s'haurà de ser molt crític amb els resultats obtinguts.
Un dels objectius del treball que es presenta a continuació és la de precisament, partint d'un tros de seqüència del genoma d'una espècie, aconseguir anotar, o si més no delimitar, l'estructura d'un gen que s'hi troba camuflat. S'utilitzaran diversos programes informàtics i així mica en mica s'aniran analitzant els resultats i citant tots els problemes i avantatges que aquests presenten.
Les selenoproteïnes són proteïnes que es caracteritzen per incorporar l'aminoàcid selenocisteïna (Sec) a la seva seqüència. Aquest aminoàcid, considerat el 21è del codi genètic, ve codificat pel codó UGA. Aquest fet dificulta el seu estudi degut a que en la major part de les proteïnes aquest codó és alhora un codó STOP.
El fet que aquest codó tingui una doble funcionalitat (codó STOP i codificant de l'aminoàcid selenocisteïna) implica que la cèl.lula ha de tenir mecanismes per tal de diferenciar entre ambdues situacions. En el cas de tractar-se de la traducció d'una selenoproteïna, es veu que l'ARN missatger de la mateixa es caracteritza per presentar dues propietats que el diferencien de la resta:
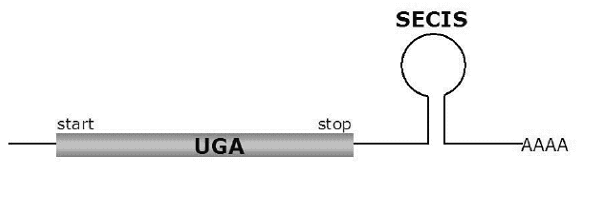 Fig.2 Esquema de l'mRNA d'una selenoproteïna eucariota
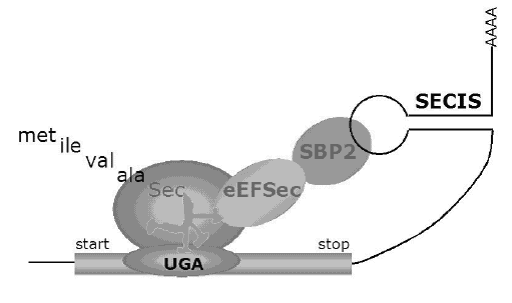
Fig.2 Esquema de l'mRNA d'una selenoproteïna eucariota És precisament a través de l'element SECIS que es pot donar la recodificació del codó UGA. Aquest element és reconegut per la proteïna SBP2 (SECIS binding protein 2), que interacciona amb un factor d'elongació específic de Sec, l'EFsec. Aquesta interacció permetrà la reclusió del Sec-tARNSec, que incorporarà l'aminoàcid selenocisteïna a la cadena polipeptídica.
Les selenoproteïnes no representen pròpiament una família funcional, sinó que la seva classificació dins d'aquest grup és únicament pel fet de presentar la particularitat de tenir l'aminoàcid selenocisteïna. De totes maneres, malgrat que les seves funcions poden ser molt diverses, la major part d'elles s'ha vist que són enzims REDOX, amb una funionalitat clarament antioxidant. El que s'ha vist també és que en eucariotes, la disrupció del gen que codifica pel tRNAs-Sec és letal, cosa que fa pensar que les selenoproteïnes desenvolupen una funció essencial pel correcte funcionament de l'organisme (Hatfiled L et al., 2002).
Aquest grup proteic s'ha identificat tant en organismes procariotes com en eucariotes i d'aquest últim de moment se n'han classificat 19 famílies.
Tot i que, com ja s'ha vist a la part anterior, les selenoproteïnes presenten dues característiques que les diferencien de la resta de proteïnes, no existeix cap motiu específic que permeti la seva identificació fiable mitjançant mètodes computacionals.
Aquest problema ve per dos motius:
Això dificulta molt la tasca de l'anotació genòmica de les selenoproteïnes i la correcte predicció de l'estructura proteica. Conseqüentment aquesta família està pobrement caracteritzada.
En el nostre treball, tractarem d'abordar tots aquests problemes utilitzant diverses eines computacionals i evaluant els seus pros i contres a l'hora d'identificar les selenoproteïnes.
