PREDICCIÓ DE GENS
A PARTIR D'UN CONJUNT D'EXONS
A PARTIR D'UN CONJUNT D'EXONS
Introducció
El programa
Baixar-se el programa
Glossari (recomanem la seva consulta)
El servidor (accés directe NeuVidServer)
Condicions d'ús del programa
Conclusions i resultats
Referències
Introducció
IniciLa identificació computacional de gens ha esdevingut en els últims temps un important camp de recerca; el desenvolupament del Projecte del Genoma Humà i altres projectes genòmics ha fet necessari crear eines computacionals per tal de localitzar regions rellevants en un ampli i no-caracteritzat conjunt de seqüències gèniques.
El problema d'identificació de gens es pot formular com la deducció de la seqüència d'aminoàcids codificada per una seqüència gènica donada. Cal considerar diverses característiques del genoma humà alhora de dissenyar aquests tipus de programes: en primer lloc, els gens no es troben continus en el genoma sinó que estan separats per grans regions intergèniques no codificants; en segon lloc els gens estan dividits en un número (que pot ser gran o petit) de fragments codificants anomenats exons separats per uns fragments no codificants, els introns.
La resolució d'aquest problema implica tres passos principals:
- Predicció d'elements gènics a partir d'un conjunt de seqüències de DNA no caracteritzades.
- Predicció de gens a partir d'un conjunt d'exons.
- Identificació del gen i caracterització de la proteïna que codifica.
Cal que els programes de predicció de gens incorporin algorismes que permetin un ensamblatge de complexitat lineal i no quadràtica, ja que si tots els exons interns que s'ensamblen no es sobreposen i tenen pauta de lectura i remainder compatibles, el nombre de gens potencials que pot predir el programa creix exponencialment respecte el nombre d'exons que formen el conjunt i això suposa un increment del temps de càlcul.
El NeuVid es un programa de predicció de gens a partir d'un conjunt d'exons. L'algorisme utilitzat es basa en la tècnica de programació dinàmica i té una complexitat no lineal. Els exons utilitzats hauran estat predits prèviament per un programa de predicció d'exons (Genscan, Geneid o Predictor) i enregistrats en un fitxer en format GFF. Cada vegada que s'executa el programa es prediu un únic gen en funció de les restriccions que l'usuari imposa. Aquest gen predit serà el gen de màxima puntuació resultat de l'ensamblatge dels exons predits. Únicament treballarem sobre els exons d'strand positiu, ja que és excessivament complex tenir en compte els d'strand negatiu.
Prediu gens tenint en compte:
- La compatibilitat de pauta de lectura.
- Que els exons siguin consecutius en ordre creixent d'acceptor
- Model de gen especificat per l'usuari
- Distància mínima i màxima especificada per l'usuari (nombre de nucleòtids
entre cada parell d'exons consecutius)
______________COM CONSTRUÏM EL MILLOR GEN?______________
A causa de la dificultat conceptual del procés de construcció o ensamblatge d'un gen utilitzem un exemple senzill per tal d'il.lustrar els passos a seguir.
Donat un conjunt d'exons E={A,B,C,D} ordenats en ordre creixent d'acceptor, farem totes les construccions possibles que acaben amb cada un dels elements del conjunt, escollint després la construcció de major puntuació, que correspondrà al millor gen. La puntuació d'un gen s'obté sumant la puntuació de cada un dels exons que el formen.
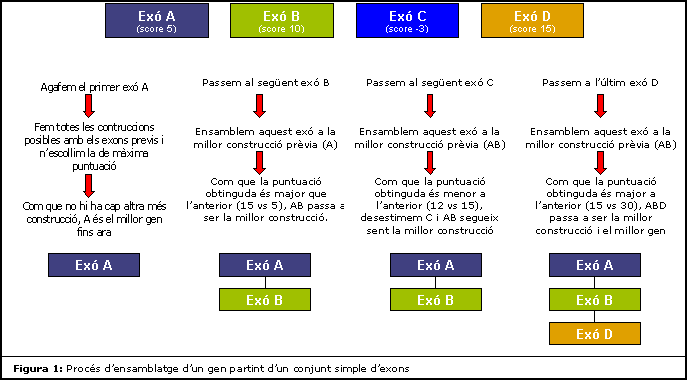
Un cop vist l'exemple pràctic, detallem el procès de construcció del millor gen de manera teòrica:
El que volem és trobar l'ensamblatge del gen g* que maximitzi la puntuació dins un conjunt G = {gi,..., gk}que conté tots els ensamblatges compatibles amb el model de gen i restriccions (imposades per l'usuari) generats a partir del conjunt d'exons donats. El gen g* que maximitza la puntuació dins el conjunt G es trobarà forçosament dins el subconjunt G* de gens que maximitzen la puntuació al llarg de diferents subconjunts de gens amb un mateix exó final. El que farà el programa serà generar el subconjunt G* i escollir després el gen amb la puntuació més alta.
El programa
IniciEn aquest apartat expliquem els passos que hem seguit per dissenyar el nostre programa. En primer lloc es mostra l'algorisme bàsic i seguidament les implementacions corresponents
Vam partir de l'aplicació de l'algorisme central sobre un conjunt de dades senzill: quatre exons dels que sabíem les posicions d'acceptor i donnor i les seves puntacions. Posteriorment, vam dissenyar l'entrada de dades a partir de fitxers externs i l'obtenció dels resultats.
Pas 1: algorisme central
Inici
$i=0;
while ($i < (scalar @acc)) {
$S[$i]=0;
$G[$i]=-1;
$j= 0;
while ($j <= $i-1) {
if ($don[$j] < $acc[$i]) {
if ($S[$j] > $S[$i]) {
$S[$i]=$S[$j];
$G[$i]=$j;
}
}
$j=$j+1;
}
$S[$i]=$S[$i] + $pun[$i];
$i=$i+1;
}
Aquest algorisme obté totes les combinacions d'exons possibles del conjunt d'exons donat i d'aquestes en prediu el millor gen (el de màxima puntuació). El vector @S acumula la puntuació del millor gen acabat amb cada exó i.
La variable $i correspon a l'exó que tractem a cada iteració, i la variable $j correspon a la millor contrucció prèvia.
El vector @G conté les posicions que ocupen els exons que formen el millor gen en el vector inicial (que és el que conté tots els exons de partida).
La predicció obtinguda amb aquest algorisme és molt poc fiable ja que no té en compte cap mena de restricció, per tant el següent pas és implementar-lo amb les restriccions necessàries.
Pas 2: Implementacions de restricció
A l'hora d'ensamblar un gen, hem de tenir en compte un conjunt donat de restriccions que ens indicaran com podem concatenar els diferents tipus d'exons.
a) Compatibilitat de pauta de lectura
Inici
$i=0;
while ($i < (scalar @acc)) {
$S[$i]=0;
$G[$i]=-1;
$j = 0;
while ($j <= $i-1) {
if ($don[$j] < $acc[$i] && $rem[$j] == $frame[$i]) {
if ($S[$j] > $S[$i]) {
$S[$i]=$S[$j];
$G[$i]=$j;
}
}
$j=$j+1;
}
$S[$i]=$S[$i] + $pun[$i];
$i=$i+1;
}
Aquesta restricció obliga a que només s'ensamblin els exons que presenten compatibilitat de pauta de lectura. Això vol dir que el remainder de l'exó j és igual al frame de l'exó i.
b) Model de gen i distància entre exons
Inici
$i=0;
while ($i < (scalar @acc)) {
$S[$i]=0;
$G[$i]=-1;
$j = 0;
while ($j <= $i-1) {
if ($don[$j] < $acc[$i] && $rem[$j] == $frame[$i] &&
model ($tipus[$j], $tipus[$i], \@rest, $dist[$i])) {
if ($S[$j] > $S[$i]) {
$S[$i]=$S[$j];
$G[$i]=$j;
}
}
$j=$j+1;
}
$S[$i]=$S[$i] + $pun[$i];
$i=$i+1;
}
Aquesta nova restricció imposada obliga a que en cada iteració, cada parell d'exons que s'ensambla compleixi el model de gen (tipus d'exó -first, internal, terminal- i distància mínima i màxima entre exons) imposat per l'usuari. Aquestes condicions venen determinades per la funció model, que necessita quatre paràmetres per executar-se:
- $tipus[$j]: tipus d'exó amb que acaba la construcció j que ensamblarem amb l'exó i
- $tipus[$i]: tipus d'exó i que ensamblarem amb l'exó i
- @rest: matriu on tenim les restriccions imposades (contingudes en un fitxer creat per l'usuari)
- $dist[$i]: distància entre cada parell d'exons que ensamblem a cada moment
A cada iteració es mira si es poden concatenar els dos exons (i i j) segons el conjunt de restriccions donat.
Pas 3: Entrada de dades
Inici-
- Obrir el fitxer gff d'exons
- Lectura del fitxer i emmagatzematge de les dades en forma de matriu.
En aquest punt desestimem els exons d'strand negatiu
- Ordenar la matriu en ordre creixent d'acceptor
- Fem correspondre cada columna de la matriu amb els vectors que utilitzarem durant l'execució del programa, que són:
@acc: vector que conté la posició acceptor de tots els exons
@don: vector que conté la posició donnor de tots els exons
@pun: vector que conté l'score de cada un dels exons
@strand: vector que conté la cadena de cada exň
@frame: vector que conté el frame de tots els exons
@rem: vector que conté el remainder de tots els exons
@tipus: tipus d'exó: first/internal/terminal
@codi: referència de GenBank
@ppred: programa de predicció dels exons utilitzat
Aquest conjunt d'exons l'anomenarem conjunt característiques, per facilitar l'explicació posterior.
Pas 4: Obtenció de dades
Inici-
- Localitzem la posició, que anomenarem per exemple x, del @S on es troba el valor màxim (corresponent a la puntuació del millor gen ensamblat)
- Ens situem en la posició x de @G i en totes les posicions x dels vectors del conjunt característiques. Aquesta posició determina les diferents característiques de l'últim exó del millor gen. El contingut d'aquestes posicions s'enmagatzema en noves variables, que són:
@ag: vector que conté els acceptors dels exons del millor gen (provinent de @acc)
@dg: vector que conté els donors dels exons del millor gen (@don)
@cg: vector que conté la referencia de GenBank dels exons del millor gen (@codi)
@ppg: vector que conté el nom del programa utilitzat per predir els exons (@ppred)
@tg: vector que el tipus de cada un dels exons del millor gen (@tipus)
@pg: vector que conté la puntuació de cada exó del millor gen (@pun)
@sg: vector que conté l'estrand de cada exó del millor gen (@strand)
@fg: vector que conté el frame de cada exó del millor gen (@frame)
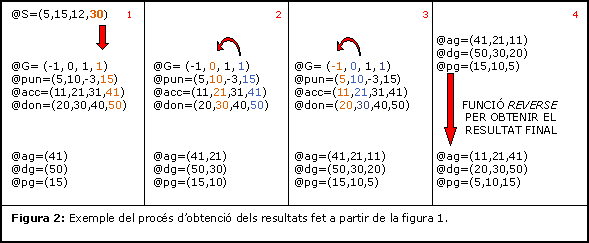
- El contingut de la posició x de @G ens indica la posició del següent exó a ensamblar; ens desplacem a aquesta posició (tant en @G com en els vectors del conjunt característiques) i tornem a extraure la informació que hi és continguda enmagatzemant-la en els vectors presentats anteriorment. (figura 2: 1)
- Aquest procés es repeteix per tots els exons que formen el millor gen; anem construint el gen des des de l'últim exó fins al primerf(figura 2: 2,3).
- Com que hem començat per l'últim exó apliquem la funció reverse sobre tots els vecotrs per tenir la seqüència d'exons en sentit 5' a 3' (figura 2: 4) .
- Els resultats es mostren per pantalla en format gff.
Condicions d'ús del programa
Inici
- Aquest programa ha estat realitzat amb l'editor de text EMACS de Linux 2.4 en llenguatge Perl de programació
- Entrada de dades:
- Fitxer de text creat per l'usuari que contingui les restriccions de model de gen ( consultar glossari )d'interès. El format ha de ser el següent:
first internal 40 10000 first terminal 50 10000 internal internal 33 8000 internal terminal 455 7777
- Fitxer GFF que conté el conjunt d'exons predits per un altre programa (consultar glossari)
Conclusions i resultats
Inici
El NeuVid és doncs, un programa de predicció de gens a partir d'un conjunt d'exons donat (els quals hauran estat predits prèviament amb un programa de predicció d'exons) que utilitza un algorisme basat en PROGRAMACIÓ DINÀMICA de complexitat no lineal.
Prediu gens tenint en compte la compatibilitat de pauta de lectura, que els exons siguin consecutius en ordre creixent d'acceptor, que es compleixi el model de gen especificat per l'usuari i que es compleixi també la distància mínima i màxima (nombre de nucleòtids entre cada parell d'exons consecutius que especifica l'usuari).
Així mateix podem dir que prediu gens amb força exactitud, ja que en comparar les prediccions obtingudes amb el NeuVid amb les obtingudes amb un altre programa de predicció de gens (Geneid, Genscan,...) els resultats són idèntics.
A continuació posem un exemple dels resultats que es poden obtenir amb el NeuVid:
-
- Fitxer d'exons predits per geneid_v1.1
- Fitxer de les restriccions que l'usuari pot imposar (model de gen i distància mínima i màxima entre cada parell d'exons consecutiu)
first internal 40 10000
first terminal 50 10000
internal internal 33 8000
internal terminal 455 7777
- Resultat després de córrer el programa NeuVid amb els fitxers anteriors:
La puntuacio del millor gen es: 12.16
NM_006533 geneid_v1.1 Internal 65 197 2.08 +
NM_006533 geneid_v1.1 Internal 280 413 4.67 +
NM_006533 geneid_v1.1 Internal 1497 1607 5.39 +
NM_006533 geneid_v1.1 Internal 1925 1944 0.02 +
Referències
Inici
- Guigó, R., 1998. Assembling Genes from Predicted Exons in Linear Time with Dynamic Programming. J. Comput. Biol.; 5(4): 681-702.