GEKKO JAPONICUS
Discovering all the selenoprotein sequences in Gekko japonicus genome
ABSTRACT
Selenoproteins are proteins containing the uncommon amino acid known as selenocysteine (Sec), which includes a selenium atom and is encoded by the UGA codon. Since this nucleotide triplet usually signals for the termination of translation, computational tools are needed in order to distinguish between stop codons and selenocystein codons. Sec is inserted by a specific translational machinery that recognizes a cis stem-loop structure known as SECIS element at the mRNA 3'UTR region of selenoproteins.
The aim of this study was to characterize all the selenoproteins and proteins involved in their biosynthesis, in the organism Gekko japonicus, performing an homology study between our organism of interest and a species with its selenoproteins previously annotated, Anolis carolinensis.
The prediction of the selenoproteins was achieved using different bioinformatic resources (including Blast, Exonerate, GeneWise, T-coffee) that were automatized. The obtained alignments were analyzed, and its SECIS structures characterized executing an online prediction program (SECISearch3).
Twenty-two selenoproteins and seven associated machinery has been found along with seven homologues with cysteine, providing new insight in the Gekko japonicus genome characterization. The results shed light on the study of evolutionary changes in this type of proteins.
INTRODUCTION
Selenoproteins
Selenium is a chemical element essential for most of the eukaryotic organisms. As a trace element, it has the properties of many known micronutrients: high levels of selenium leads to toxicity, but deficiency of this element is responsible for several dysfunctions.(1)
Selenium is incorporated through water and food consumption in selenite and selenate forms. These and other diet and tissue selenium forms are converted to selenide through different processes such as the glutathione-glutaredoxin and thioredoxin system or the lyase action. Later, SPSH2 (Selenophosphate Synthetase 2) transforms selenide into selenophosphate, which is the active selenium donor in the conversion from seryl-tRNAsec to Sec-tRNAsec. When charged, this transference RNA carries the amino acid selenocysteine. (2) (3)
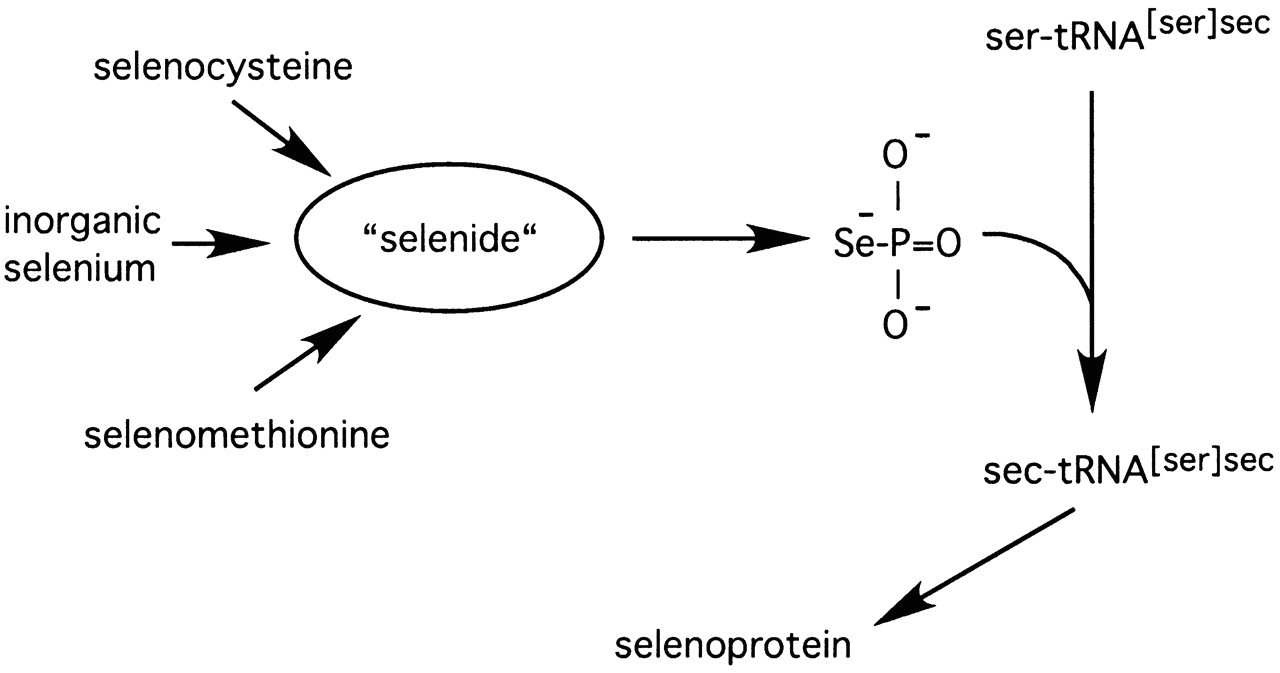
Selenocysteine (Sec) is a proteinogenic amino acid, known as the 21st one. It shares structural similarities with cysteine but containing a selenium instead of a sulfur atom . Selenocysteine is encoded by the UGA codon found in mRNA and it is inserted in the polypeptide chains of selenoproteins by the tRNAsec. (4)
Selenoproteins are proteins that include selenocysteine in their amino acidic chain. Proteins involved in the biosynthesis of selenoproteins are also considered as such. They are found in many species of archaea, bacteria and eukarya domains. Even though their functions depend on the family protein, most of selenoproteins are involved in redox-related processes. (5)
Selenoproteins can be classified according to different criteria: the position of its selenocysteine and their relevance and function. Depending on the position of the selenocysteine in the peptidic chain, two types of selenoproteins can be distinguished: the ones with the Sec near the C-terminal end (TrxRs and selenoproteins S, R, I, O, K) and the ones with the Sec near the N-terminal end (GPxs, DIOs, Sep15, SPS2 and selenoproteins H, M, N, T, V, W). Another criteria used to classify selenoproteins is related to their essentiality for cell survival and function: housekeeping proteins (which are poorly affected by dietary selenium status due to its importance in cell viablity) and stress-related proteins (which are not essential for survival an therefore less expressed in selenium-deficient conditions). (6)
Biosynthesis of selenoproteins
The codon that specifies for selenocysteine (Sec) is usually a STOP codon (UGA). Therefore, translation machinery needs special mechanisms in order to distinguish between the termination of translation and the addition of the Sec residue. This redefinition of UGA is induced by the presence of a stem-loop structure called Selenocysteine Insertion Sequence or SECIS. This element is located far away from the UGA codon in the 3’-UTR of the selenoprotein mRNA, beyond the end of the coding sequence of the mRNA. (4) Two defined regions of the SECIS element are essential for its function: a quartet of non-Watson-Crick interacting bases (which include GA/GA pairs and is located in the loop base) and an apical loop, formed by two unpaired bases mostly AA. (6)
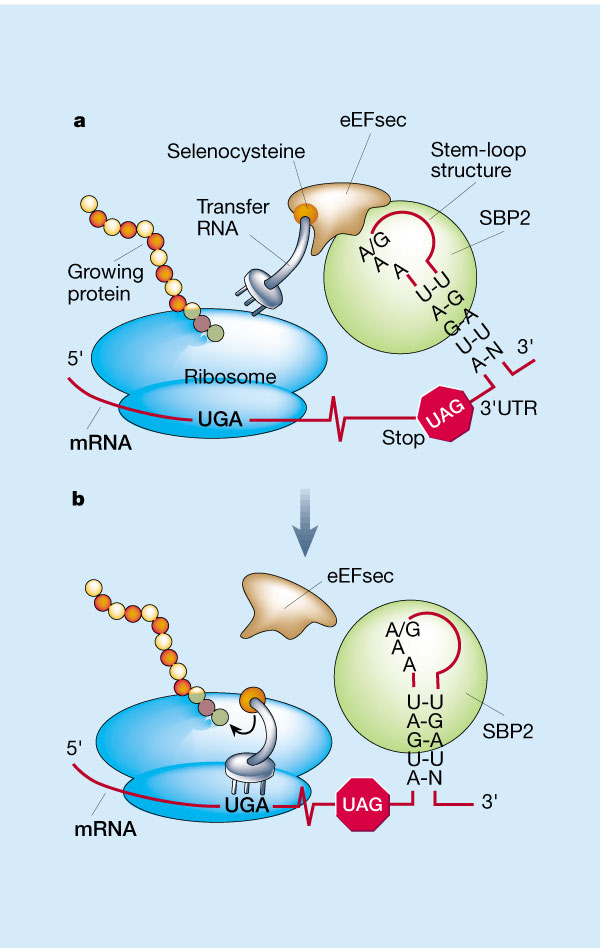
The SECIS-binding protein 2 (SBP2) binds to the SECIS element, preventing termination at the UGA/Sec codon. Another protein, eEFsec, binds to SBP2 and to the Sec-tRNAsec . (7) This tRNA charged with Sec is delivered to the UGA codon and then Sec is incorporated into the growing amino acid chain creating the selenoprotein. (4)
Selenoprotein Families
Selenoproteins are grouped in different families according to their function and structure similarities. Several families have been characterized, but it is believed that some of them remain undocumented. Most of the available information about selenoprotein families has been obtained from human and other mammal studies. The following information describes all the mammal selenoprotein families found in other reptiles.
Thioredoxin Reductases (TrxRs)
In mammals, selenoproteins belonging to this family are included in the pyridine nucleotide-disulfide oxidoreductase group. Similarities in the three-dimensional crystal structure are found between TrxRs and glutathione reductases, both containing FAD- and NADPH-binding domains and an interface domain.
Thioredoxin reductases are homodimers formed by two subunits with a head-to-tail disposition. These selenoproteins are the only enzymes capable of reducing oxidized Trx (Thioredoxin). This function is essential because Trx provides electrons to the ribonucleotide reductase enzyme, an indispensable protein for DNA synthesis as it converts ribonucleotides to deoxyrinonucleotides.
TrxRs also participate in many cellular signaling pathways. Their role is to control the activity of transcriptional factors that contain cysteines in their DNA-binding domains, such as AP-1, NF-kB or p53. Cellular proliferation, cell viability and apoptosis are other cell functions in which TrxRs are involved. (3)
Glutathione Peroxidases (GPxs)
The incorporation of selenium in the form of selenocysteine was first reported in proteins of the GPx family. They are the major components of the human antioxidant defense system, as they reduce hydrogen peroxide and organic hydroperoxides, amongst other compounds. GPx family is the largest selenoprotein family in vertebrates, containing 8 different proteins in mammals:
- GPx1 is an ubiquitous cytosolic GPx. The main role of metabolize only hydrogen peroxide and certain organic hydroperoxides. Mutations in the GPX1 locus have been reported as a potential causal factor in the development of cancer: loss of heterozygosity on the previously mentioned locus has been detected in lung, breast and colon cancer.
- GPx2 is a gastrointestinal-specific GPx. High levels of GPx2 expression have been reported in many breast cancer cell lines. GPx2 is a homotetrameric protein, and so are GPx1 and GPx3.
- GPx3 is a plasma GPx. As many other peroxidases, these proteins catalyze the reduction of hydrogen peroxide and organic hydroperoxides. It is believed that GPx3 is also involved in the distribution of selenium together with Selenoprotein P. This will be further explained in the “Selenoprotein P” section.
- GPx4 is an ubiquitous monomeric GPx. Its function is to reduce phospholipid and cholesterol hydroperoxides. GPx4 is also found in mature spermatozoa as the main structural component of the mitochondrial capsule, having a significant role in sperm maturation and male fertility.
- GPx5 is an epididymal androgen-related protein. It is not considered a selenoprotein as it has no Sec in its sequence.
- GPx6 is an olfactory epithelium GPx. This peroxidase is also found in embryonic tissues.
- GPx7 and GPx8 are neither considered selenoproteins, due to the lack of Sec residues in their sequences.
Both cysteine-containing GPx7 and GPx8 evolved from GPx4 selenoprotein ancestors. GPx5 and GPx6 are the most recently evolved GPxs, and they are believed to be the result of a tandem duplication of GPx3. (3)(8)(9)
Iodothyronine Deiodinases (DIOs)
The iodothyronine deiodinase family consists of three proteins involved in the regulation of activation and inactivation of thyroid hormones. These oxidoreductases are classified according to their location:
- DIO1 is found mainly in the liver, the kidney and the thyroid and pituitary glands.
- DIO2 is found in the brain, the pituitary and thyroid glands, skeletal muscle and brown adipose tissue.
- DIO3 is located in the cerebral cortex and skin. It is also expressed at a very high level in the placenta, pregnant uterus, embryonic liver, embryonic and neonatal brain and neonatal skin.
All DIOs share structural similarities (thioredoxin-fold) and are integral membrane proteins: DIO1 and DIO3 are attached to the plasma membrane, while DIO2 is located at the endoplasmic reticulum membrane. DIO1 and DIO2 catalyze the deiodination of T4 secreted by the thyroid gland into the active hormone T3. Oppositely, DIO3 inactivates the thyroid hormone catalyzing the conversion of T4 into reverse T3 and T3 into T2 . (3) (8)
Selenoprotein P (SELENOP)
The characteristics of the proteins grouped in the SELENOP family differ from other selenoproteins. SELENOP contains multiple selenium particles in its structure in the form of selenocysteine residues: 10 Sec residues in human and 17 in the zebrafish homologue. However, the only two reptiles with its selenoproteins characterized (Anolis carolinensis and Pelodiscus sinensis) show only one Sec residue in its SELENOP proteins.
In humans, the liver secrets this protein to the plasma in its glycosylated form and its expression is ubiquitous.
As mentioned previously in the GPx section, both GPx3 and SelP play an important role in selenium transport and distribution, as these proteins account for over 90% of plasma selenium. The broad expression of SELENOP suggests that this protein may have other functions such as antioxidant protection. (2)(8)(9)
Seleno-phosphate synthetase (SEPSH)
Dietary selenium is available in organic forms, such as a selenomethionine or selenocysteine. This organic selenium must be converted into seleno-phosphate, the inorganic form of selenium that will be incorporated in a serine-charged transference RNA in order to obtain a selenocysteine-charged tRNA. SEPSH proteins, also known as SPS proteins, are involved in the synthesis of seleno-phosphate molecules. Therefore, besides the fact that these selenoproteins allow the synthesis of Sec-tRNA, it is believed that they act as regulators of selenium bioavailability and prevent excessive incorporation of this element.(2)(9)
Seleprotein W (SELENOW)
SELENOW are small and ubiquitous cytoplasmic selenoproteins with the Sec residue located in its N-terminal end. According to the selenoprotein classification criteria described in the Selenoproteins section, SELENOW is catalogued as a stress-related protein as its expression depends on selenium levels. Along with SELENOT and SELENOH, these proteins belong to the Rdx super-family. Selenoproteins grouped in this family are structurally similar to GPx proteins, both with a redox motif and affinity to glutathione. These shared characteristics and SELENOW induced expression in response to oxidative stress suggest that these proteins are mainly involved in antioxidative processes. It has also been related to muscle development and metabolism and is believed to have a potential specific function in brain, where it is constitutively expressed. Selenium deficiency drives to reduction of SELENOW levels in skeletal muscle, heart, prostate, skin, esophagus and intestine. (1)(8)
Selenoprotein S (SELENOS)
Selenoprotein S -also known as SELENOS or SEPS- is located in the endoplasmic reticulum (ER), where it plays an important role in the removing of misfolded proteins from this organelle to the cytosol for degradation. Its expression is induced in response to ER stress signals. SELENOS has also been proposed as a regulatory factor of the inflammatory response via controlling the proinflammatory cytokines levels in macrophages. (1) (8)
Selenoprotein 15 (Sel 15)
Sel 15, as SELENOM, is a thioredoxin-like fold ER-resident protein. This protein has a thiol-disulfide isomerase activity and is possibly involved in disulfide bond formation. Sel 15 is highly expressed in prostate, liver, kidney and testis.
This protein presents a signal peptide at N-terminus required for their ER localization, but it lacks an ER retention signal. This suggests that its localization in the endoplasmic reticulum may be maintained through other bindings. Near to this signal peptide the protein presents a cysteine-rich domain, which is required for interaction with other proteins. Due to the fact that loss of heterozygosity at Sel15 locus has been associated with cancer, it has been suggested that this protein may be a mediator of the cancer prevention effect of dietary selenium. Another proposed function for Sel 15 is the regulation of redox homeostasis in ER.(10)
Selenoprotein M (SELENOM)
This protein presents functional and structural homology with Sel 15, with a thiol-disulfide activity and a signal peptide at the N-terminal end. Thus, it has also been proposed as a protein with an important role in disulfide bond formation in the ER.(10)
Redox-active motifs observed in SELENOM structure indicate that this protein has a redox function. SELENOM may catalyze the rearrangement or reduction of disulfide bonds located in the ER.
SELENOM presents a highly flexible retention signal in its C-terminal end, and it is mainly expressed in brain. Its location suggests that this protein may be involved in neuroprotection in front of oxidative damage. In fact, overexpression of SELENOM in neuronal cells has been found as a preventive factor against oxidative damage, whereas in vitro studies of cells knocked-out for the SELENOM gene have shown decrased cell viability and strong apoptotic effects. Moreover, SELENOM has been demonstrated to have a role in the prevention of Alzheimer’s disease, by inhibiting aggregation of β-amyloid peptide in brain neurons. (10)(11)
Methionine-R-Sulfoxide Reductase (MSRB)
Methionine-R-Sulfoxide Reductase family includes three proteins, one of them containing selenocysteine (MSRB1) and two of them being homologues with cysteine (MSRB2 and 3).
MSRB1 contains zinc and functions as a stereospecific methionine-R-sulfoxide reductase, catalyzing the reparation of oxidized R methionine enantiomers. It has functional similarity with Methionine-S-Sulfoxide Reductase A (MSRA), each of them acting only in one stereoisomer of the target protein. MSRB1 is located both in nucleus and cytoplasm of the liver and kidney cells.
The catalytic mechanism of MSRB1 involves three steps: (1) the catalytic Sec residue attacks the sulfur atom of methionine-R-sulfoxide and forms selenic acid as an intermediate product, (2) Sec selenic acid forms a selenoylsulfide bond with the resolving Cys and (3) the selenylsulfide is reduced by Trx or Grx proteins restoring the activity of the catalytic site.
As mentioned before, the two additional MSRB homologues (MSRB2 and 3) contain a Cys residue instead of Sec in their catalytic site. MSRB2 is located in the mitochondria and MSRB3 in the ER. MSRB1 is the homologue with highest activity, though the three enzymes have similar catalytic efficiencies. Methionine-R-Sulfoxide Reductase (MSRB) (11)(12)
Methionine-S-Sulfoxide Reductase A (MSRA)
MSRA cysteine-homologue protein is expressed obiquitously, with the highest levels in kidney and nervous tissue.(13) The function of MSRA consists in a stereo-specific reduction of both free and protein-linked methionine-S-sulfoxide residues. It contains a mitochondrial signal peptide. Although MSRB and MSRA proteins are structurally different, their active-site configurations present mirror symmetry. This reflects the fact that these enzymes catalyze the reduction of the two methionine sulfoxide stereoisomers. (11)
Calcium/calmodulin-dependent protein kinase II (CaMKII) has been shown to be activated by oxidation of its methionine residue in the regulatory domain in absence of calcium/calmoduline, and this activation is thought to be reversed by MSRA.(12)
Selenoprotein U (SELENOU)
The function and structure of this family remain unknown.(8)
Selenoprotein T (SELENOT)
This thioredoxin-like protein is predominantly located in ER and Golgi, and is ubiquitously expressed during embryonic development and in adult tissues. It belongs to the Rdx family of selenoproteins, along with SELENOW and SELENOH, and was one first selenoproteins discovered using bioinformatic tools. This protein may be involved in the regulation of Ca2+ homeostasis and neuroendocrine function. It has also been related to the regulation of pancreatic beta-cell function and glucose homeostasis, and in the expression of extracellular matrix genes involved in cell structure organization and adhesion. (10)(11)
Recent studies indicate that selenoproteins such as SELENOT exert a neuroprotective role, specifically in dopaminergic neurons, against oxidative stress and cell death. These findings provide insight into the molecular mechanisms of oxidative stress in Parkinson’s disease.(14)(15)
Selenoprotein H (SELENOH)
SELENOH belongs to the Rdx family of selenoproteins and has a conserved nuclear targeting RKRK motif in the N-terminal sequence. This nuclear oxidoreductase contains a unique subcellular localization pattern. Although it is barely expressed in adult tissues, its expression is very elevated during embryonic development.(11)
SELENOH binds specifically to sequences that contain heat shock and stress response elements. Furthermore, SELENOH possesses an intrinsic glutathione peroxidase activity and can increase glutathione levels. In response to stress, this proteins may up-regulate other selenoproteins involved in the regulation of oxidative stress such as GPx. (1)(11)
Deficiencies of SELENOH induce an inflammatory response and activate the p53 pahtway, generating oxidative stress and DNA damage. This indicates that SELENOH deficiencies may contribute to increased cancer risk.(16)
Selenoprotein I (SELENOI)
This protein is only found in vertebrates, indicating a recent appearance in the phylogenetic line. It is a transmembrane protein containing seven transmembrane domains and three conserved aspartic residues, which are required for SELENOI catalytic activity. It also presents a highly conserved CDP-alcohol phosphatidyltransferase domain and a Sec residue at the C-terminal end. SELENOI is one of the less studied selenoproteins, and its physiological function and role is still unknown. (6)(11)
Selenoprotein K (SELENOK)
SELENOK proteins have a transmembrane domain in the N-terminal end, a glycine-rich segment and a Sec residue at the C-terminus. These proteins interact with SELENOS proteins through their transmembrane domains and share structural and functional similarities: they are located in the ER membrane and they belong to type III group of transmembrane proteins. SELENOK are also characterized by containing only one single transmembrane domain and the C-terminal end exposed to the cytosol.
This protein is implicated in ER-associated degradation of misfolded proteins, and has been implicated in inflammation and the immune response. (11) SELENOK is expressed mainly in the ER and plasma membrane of heart cells, and it has been suggested to play an important role in redox regulation and decrease of ROS levels in cardiomyocytes. It is also expressed in other tissues such as skeletal muscle and the pancreas. (8)(12)
Selenoprotein O (SELENOO)
This protein is one of the less characterized selenoproteins. It has one single Sec residue located at C-terminus and analysis on its sequence revealed a mitochondrial targeting peptide. Its function remains still unknown. (12). It is widely distributed.(1)
Recent studies showed that this protein may be involved in the pathological process of ostearthropathy caused by selenium deficiencies. (17)
Selenoprotein N (SELENON)
SELENON is an ER-resident transmembrane glycoprotein highly expressed during embryonic development. It is ubiquitously expressed in all tissues, but in adult skeletal muscle tissue is believed to have an important role in the maintaining of satellite cells and reparation of muscles after injury or stress. It also has been found that Ryanodine Receptor (RyR), the receptor that mediates the release of Ca2+ from the sarcoplasmic reticulum during muscle contraction, may be a binding partner of SELENON. This interaction suggests that this protein might serve as a cofactor, therefore it might be involved in regulation of intracellular calcium mobilization. (12)
Although the biologic function of SELENON remains unknown, it is clear that it plays a role in muscle tissue. In fact, several forms of early-onset myopathies have been linked to the SELENON gene locus. Mutations in ryanodine receptors and SELENON have been identified as causes of these disorders. (1)(8)
Translation machinery families
It is necessary to briefly describe the proteins involved in the synthesis of Sec transference RNA and its attachment to the growing selenoprotein chain in order to achieve an optimal understanding of how selenoproteins are synthesized. These proteins, formally known as translation machinery, do not include selenocysteine residues in their peptidic chain: therefore, they are not considered as selenoproteins.
Selenocysteine-specific elongation factor (eEFsec)
eEFsec is a GTP-binding protein that delivers the Sec-tRNAsec to the ribosome. Besides its involvement in Sec-incorporation, it is also implicated in Sec-biosynthesis. Its structure contains three different domain types, (I, II and III). Domain I is required for its GTPase activity and ribosome interaction; domain II is responsible for the aminoacyl-tRNA binding and domain III may be involved in interactions with the T arm of aminoacyl-tRNAs. There is also a single fourth domain separated from the first three, and it is involved in Sec-tRNAsec binding, GTPase regulation and interactions with SECIS binding protein 2 (SBP2). (8, 18)
Sec-tRNAsec is necessary for SBP2-eEFSec complex formation. On its C-terminal region it presents a functional NLS (Nuclear Localization Sequence). This sequence overlaps with the SBP2-binding motif, suggesting that both interactions may be mutually exclusive. Therefore, if the SBP2-eEFSec union takes place inside the nucleus, this binding may help transporting eEFsec from nucleus to the ribosomal sites in the cytoplasm. On the other hand, if the complex is formed in the ribosomes (where SBP2 is usually located) this may imply that SBP2 promotes the retention of eEFSec at the ribosomes, facilitating the delivery of Sec-tRNAsec at UGA-Sec codons. Because SBP2-eEFsec complex is found both in the nucleus and the cytoplasm, these two mentioned statements may seem to be plausible. (8)
The SECIS-binding protein 2 (SBP2)
SBP2 is ubiquitously expressed in all body tissues in multiple isoforms formed by alternative splicing.
It is a very large protein with a sequence of around 854 amino acids that plays a role in the selenoprotein biosynthesis. The SBP2 binds to the SECIS element in the selenoprotein mRNA, preventing the reading of the UGA codon as a stop codon. It also binds to the eEFsec, the protein that brings the Sec-tRNAsec to the UGA codon. (4)(8)
It has a nuclear localization signal (NLS) in the N-terminal region, a potential NLS at C-terminus, two nuclear export signals (NES) in C-terminal, a functional SECIS binding domain and a ribosomal interaction domain. SBP2 is a very large protein (854 amino acids). (8)
Phosphoseryl t-RNA kinase (PSTK)
PSTK is a kinase which phosphorylates the seryl-tRNAsec complex in the presence of ATP and Mg2+. This pSer-tRNAsec intermediate serves as a substrate for the Sec synthetase (SecS). (11)(19)
tRNA Sec 1 associated protein 1 (SECp43)
This protein has two ribonucleoprotein-binding domains (RNP) which constitute an RNA-recognition motif (RRM), and is usually located in the nuclear compartment. Its expression regulates the levels of GPx1 and methylated Sec tRNA[Ser]Sec, which in turn controls the synthesis of stress-related selenoproteins. SECp43 also plays a role in the formation or stabilization of the EFSec-SBP2-Sec tRNA[Ser]Sec complex. SECp43 may also assist in the decoding of multiple UGA-Sec codons in selenoprotein P, and to prevent degradation of selenoprotein mRNAs. (8)
Selenocystein Synthase (SecS)
SecS protein is a member of the pyridoxal phosphate-dependent transferase superfamily. This protein mediates Sec incorporation into selenoproteins by dephosphorylating O-phosphoseryl tRNA[Ser]Sec and transfers monoselenophosphate to the tRNA. SecS solely depletion has no described effects. (8)(11)(20)
Gekko japonicus
| Gekko japonicus taxonomy | |
|---|---|
| Kingdom | Animalia |
| Phylum | Chordata |
| Class | Reptilia |
| Order | Squamata |
| Suborder | Lacertilia |
| Infraorder | Gekkota |
| Family | Gekkonidae |
| Genus | Gekko |
| Species | japonicus |
Gekko japonicus is a reptile of the Gekko genus and the Gekkonidae family.(21) It can be found mainly in urban areas and some rocky coastal habitats in eastern Asia (Japan, east China and South Korea).(22)(23)
Gekko japonicus is a terrestrial animal with small body size (a few centimeters), high agility and nocturnal habits, similar to other Gekko species. The Gekko japonicus group is the most diverse group within the Gekko genus, including a total of 19 recognized species distributed along eastern Asia, from Japan throughout eastern China southward to Vietnam. (24)(25)
Its capacity of tail regeneration has been studied in projects about regeneration processes, and its adhesive mechanism has been examined for the development of bioinspired technologies.(25)
Selenoproteins in Gekko japonicus had never been characterized before, and that is the main reason why this species was chosen in the present study.
More information about this species can be found in catalan in this wikipedia page written by the authors of this study.
METHODS
The aim of this project was to identify all the sequences codifying for selenoproteins and its machinery in Gekko japonicus genome. To do so, we compared selenoprotein sequences previously notated in another species, Anole carolinensis.
The choice of this species for the comparison was made based on its similarity with Gekko japonicus, as these two species are phylogenetically close. The comparison was performed using different bioinformatic resources, following a procedure that can be performed entering the data manually or automating the orders.
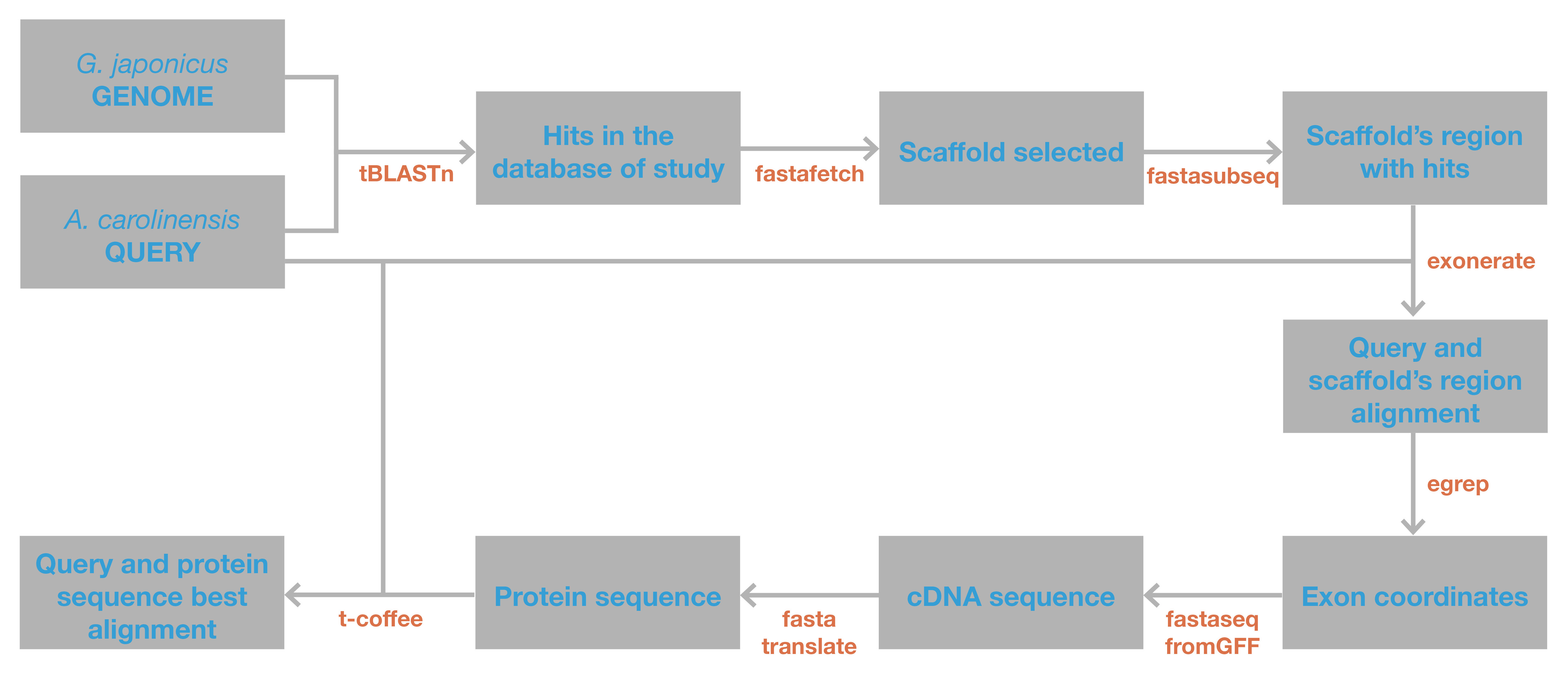
The following scheme presents a summary of the bioinformatic protocol:
Query
The query represents the sequence of the Anole carolinensi’s protein. These sequences were obtained from the online database SelenoDB.(26) Those sequences containing a selenocysteine (U) were modified replacing the U for an X as the bioinformatic resources used for the analysis do not recognize this character. Each query was saved in a file named after the contained selenoprotein sequence and ending with “.anole.fa”, as these sequences were written in FASTA format (Example: Sel15.anole.fa).
Genome (Gekko japonicus)
We were provided with the genome of Gekko japonicus, which was saved in the following directory in the Universitat Pompeu Fabra’s computer:
| /cursos/20428/BI/genomes/2016/Gekko_japonicus/genome.fa” |
Exportation of programs
The programs needed were exported using the following commands in shell:
| $ module load modulepath/goolf-1.7.20 |
| $ module load Exonerate/2.2.0-goolf-1.7.20 |
| $ module load T-Coffee/11.00.8cbe486-goolf-1.7.20 |
| $ export PATH=/cursos/20428/BI/bin:$PATH |
| $ export WISECONFIGDIR=/cursos/20428/BI/soft/genewise/x86_64/wise2.2.0/wisecfg/ |
| $ export PATH=/cursos/20428/BI/soft/genewise/x86_64/bin:$PATH |
Manual prediction of selenoproteins
a. BLAST (Basic Local Alignment Search Tool)(27) is a program that finds regions of similarity between biological sequences. The program compares nucleotide or protein sequences to sequence databases and calculates the statistical significance. As previously explained, the database used was the genome of Anole carolinensis.
The command needed to execute this step is the following:
| tblastn -query selenoprotein.anole.fa -db /cursos/20428/BI/genomes/2016/Gekko_japonicus/genome.fa -outfmt 7 -out selenoprotein.blast |
The specific blast program used was TBLASTN, a program that compares a protein query sequence against a nucleotide sequence or a database dynamically translated in all open reading frames.
The option “-outfmt 7” was required in order to obtain the blast result in a tabulated format.
The output was saved in a file named after the protein name and ended with “.blast”
b. BLAST output is a list of hits in the database of study. Each hit indicates a region of the reference genome (Anole carolinesis) very similar to the query analized. Since BLAST performs a statistical analysis, this similarity is represented in the e-value.
All hits showing an e-value of 0.001 or lower were selected for further analysis.
c. At this point, next step should be to index the genome. In this study this step was not necessary since the genome provided was already indexed.
d. EXONERATE (28) is a software working as a generic tool for parwise sequence comparison. It allows users to align sequences using a many alignement models, either exhaustive dynamic programming (the one used in the present study) or a variety of heuristics. The software contains many programs to perform the steps required for a proper alignement. The first one used is fastafetch, a program that separates the scaffold required for the analysis from the genome. This scaffold is selected according to the e-value, as explained in section (b). It is important to take in mind that, although each scaffold may have multiple hits, only one analysis was performed for each scaffold and not one for each hit.
The command needed to execute this program is the following:
| fastafetch /cursos/20428/BI/genomes/2016/Gekko_japonicus/genome.fa /cursos/20428/BI/genomes/2016/Gekko_japonicus/genome.index "scaffold name” > scaffold.fa |
The output was saved in a file named after the scaffold extracted and ended with “.fa”
e. After, the region containing the hits was extracted from the scaffold. The start point of this region was selected according to the smallest nucleotide position among the hits with an e-value equal or lower than 0.001. The final point was selected the same way, but this time according to the largest nucleotide position. In order to extract the whole gene sequence, the region extracted was extended 20000 nucleotides on each end.
As an exception to this, in those cases in which the length between one of the region ends and the end of the scaffold was smaller than 20000 positions, this number was adjusted to ensure that the region extracted was within the scaffold. This step was necessary for the program to work.
The extraction was performed using the program fastasubseq, with the following command:
| fastasubseq scaffold.fa start length > selenoprotein.extraction.scaffold.fa |
The output was saved in a file named after the protein and the scaffold analyzed, and ending with “.extraction.fa”
f. The query was compared with the extraction using exonerate program. The output obtained for each analysis showed an exhaustive alignment.
The command used to execute this program was the following:
| exonerate --exhaustive yes -m p2g --showtargetgff -q selenoprotein.anole.fa -t selenoprotein.extraction.scaffold.fa > selenoprotein.scaffold.exonerate |
The option “--exhaustive yes” was added in order to obtain a more accurate alignment.
The output of the program was saved in a file named after the protein and the scaffold analyzed, and ending with “.exonerate”.
g. Exon coordinates were extracted from the exonerate file using the shell command “egrep”, tipping the following command:
| egrep -w exon selenoprotein.scaffold.exonerate > selenoprotein.scaffold.exons.exonerate |
The output was saved in a file named after the protein and the scaffold analyzed, and ending with “.exons.exonerate”.
h. Since the exonerate results were saved in GFF (General Feature Format), which simply describes the locations and the attributes of gene and transcript features on the genome, cDNA sequence was obtained using the program fastaseqfromGFF.
The command used to execute this program was the following:
| fastaseqfromGFF.pl selenoprotein.extraction.scaffold.fa selenoprotein.scaffold.exons.exonerate > selenoprotein.scaffold.nt |
The output was saved in a file named after the protein and the scaffold analyzed, and ending with “.nt”.
i. Protein sequence was translated from this cDNA uisng the program fastatranslate, typing the following comand:
| fastatranslate -f selenoprotein.scaffold.nt -F 1 > selenoprotein.scaffold.p |
The option -F 1 indicated the reading frame.
The output from the program was saved in a file named after the protein and the scaffold analyzed, and ending with “.p”.
j. T-coffee (Tree-based Consistency Objective Function For alignment Evaluation)(29), is a software used to predict alignments. The best possible alignment between the query and the protein predicted in step (i) was performed using T-coffee. Before that, the characters “*” in output files from fastatranslate were changed for X, as T-COFFEE can not work with this characters.
The command used to execute T-coffee was the following:
| t_coffee selenoprotein.anole.fa selenoprotein.scaffold.p > selenoprotein.scaffold.tcoffee |
The output of T-coffee was saved in a file named after the protein and the scaffold analyzed, and ending with “.tcoffee”.
Automatic prediction of selenoproteins
In order to automate the process, a perl program was created. The program had two parts divided into two separated files.
The first one executed the BLAST and showed the result in the screen, allowing the user to chose which hits to analyze. Its last command was to execute the second part of the program, which automatically performed the remaining steps of the protocol, ending with the T-coffee. All files generated during the process were automatically saved in a directory created by the program and named after the protein and the scaffold analyzed.
It is important to take into account that the two program files and the query file needed to be located in the same directory.
The two program scripts can be consulted here and here.
SECIS (SElenoCysteine Insertion Sequence) elements
Online software SECISearch3 (30) was used to predict the SECIS elements in the predicted selenoproteins. The file uploaded to the software was the output from fastasubseq command.
Occasionally, more than one SECIS was predicted for one protein. In these cases, the SECIS structures not predicted in the strand where the selenoprotein is located were dismissed, as well as SECIS located at the 5’ UTR. Therefore, the selected SECIS are in the 3’ UTR of the same strand as the selenoprotein of study: in case of more than one SECIS with these two characteristics, the one with the best score was chosen.
Predicted protein analysis
Among the different scaffolds containing significant hits, best alignment was determined according to the following criteria: least gaps, more conserved sequence and highest T-coffee score.
Unclear predictions
Some predictions were unclear, due to the presence of undetermined aminoacids not corresponding to selenocysteine or pooorly conserved regions in the middle of highly conserved ones. Genewise, (31) another pairwise sequence alignment software was performed in unclear prediction cases in order to look for a different alignment.
The command used to execute Genewise was the following:
| genewise -pep -pretty -cdna -gff selenoprotein.anole.fa selenoprotein.extraction.scaffold.fa > selenoprotein.scaffold.genewise |
The output from the program was saved in a file named after the protein and the scaffold, and ending with “.genewise”.
Besides Genewise, in these unclear prediction cases the previously described protocol was repeated using a different query, the same protein from Pelodiscus sinensis and from Homo sapiens.
The first organism was chosen because it is the only other reptile whose selenoproteins were previously described in the database used.(26)
The Homo sapiens sequences were used in the unclear prediction cases because this is the organism where selenoproteins were more exhaustively described.
The unclear cases were resolved using one of these three new alignments.
RESULTS
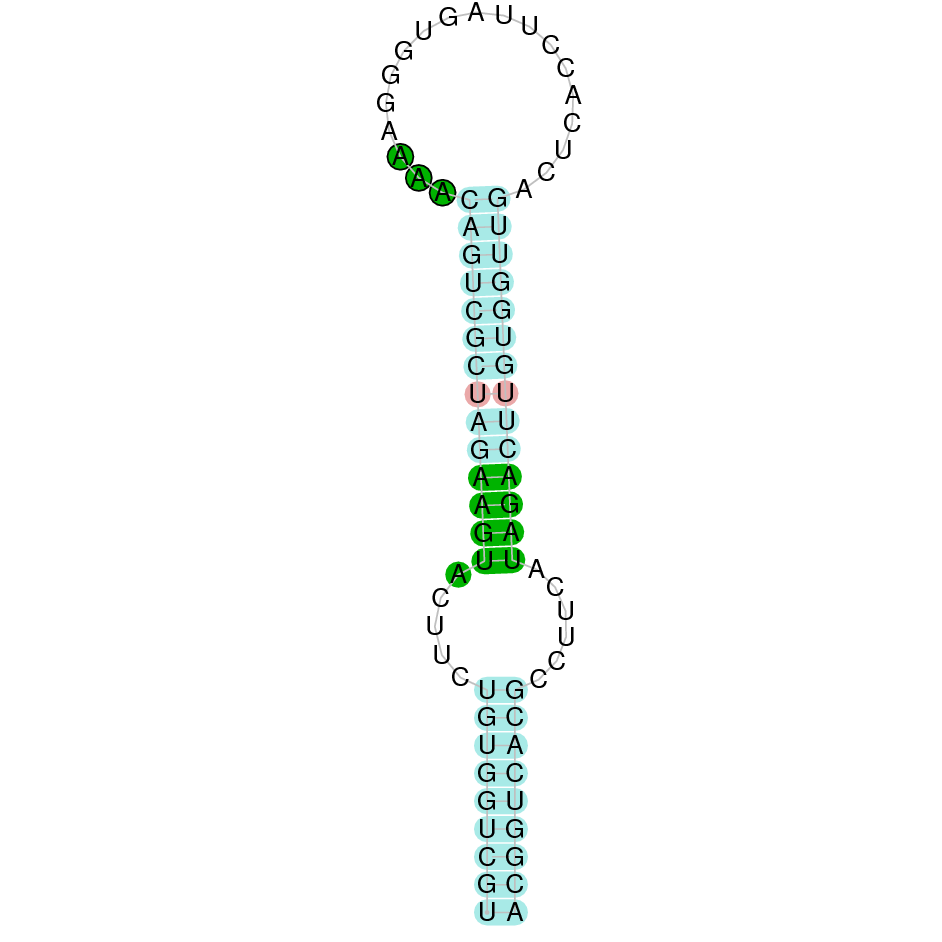
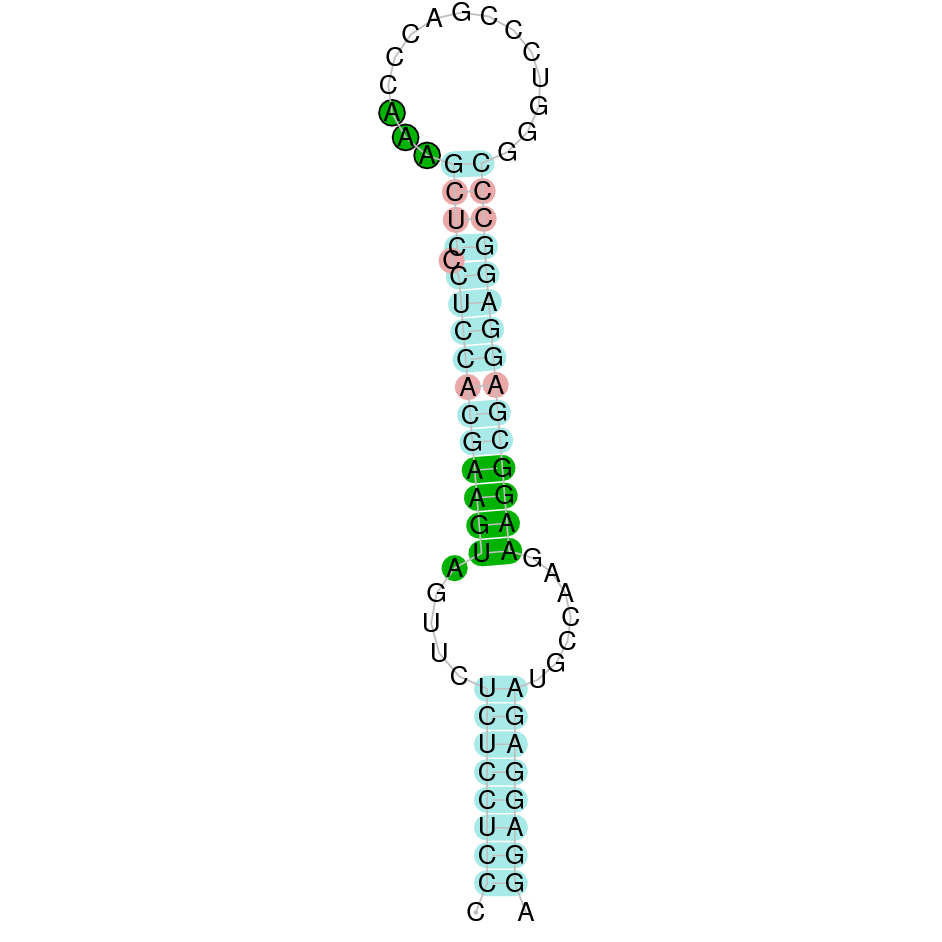
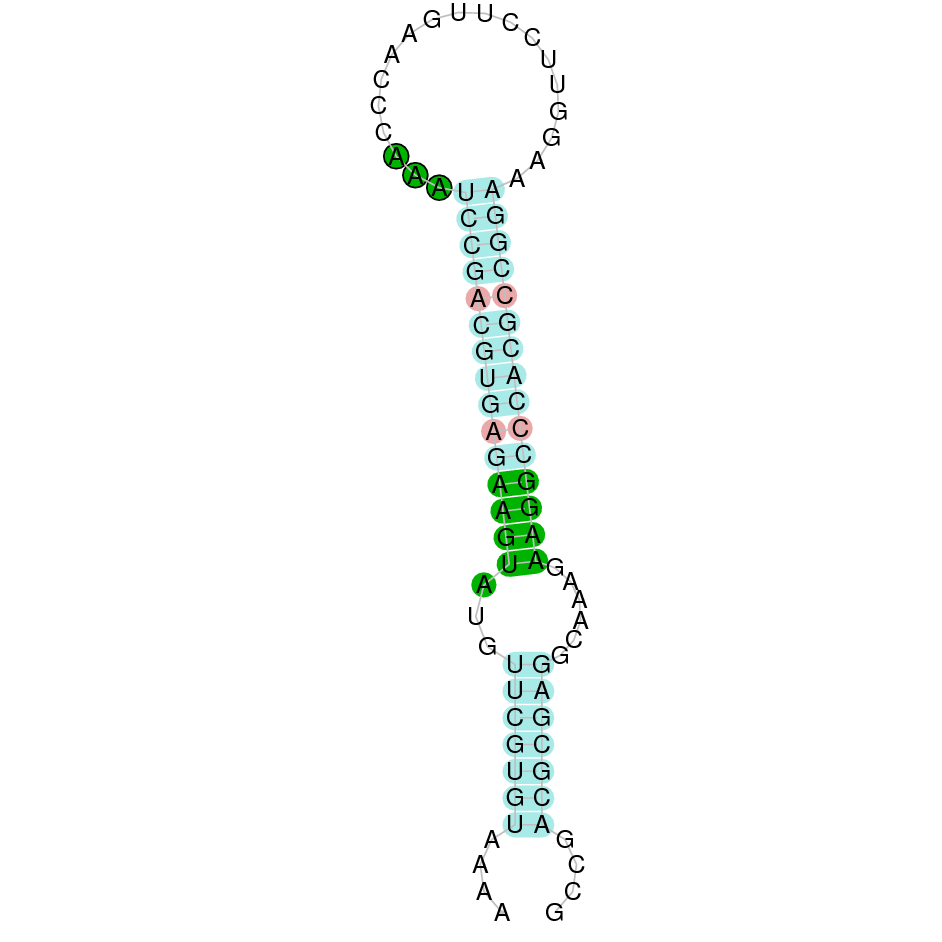
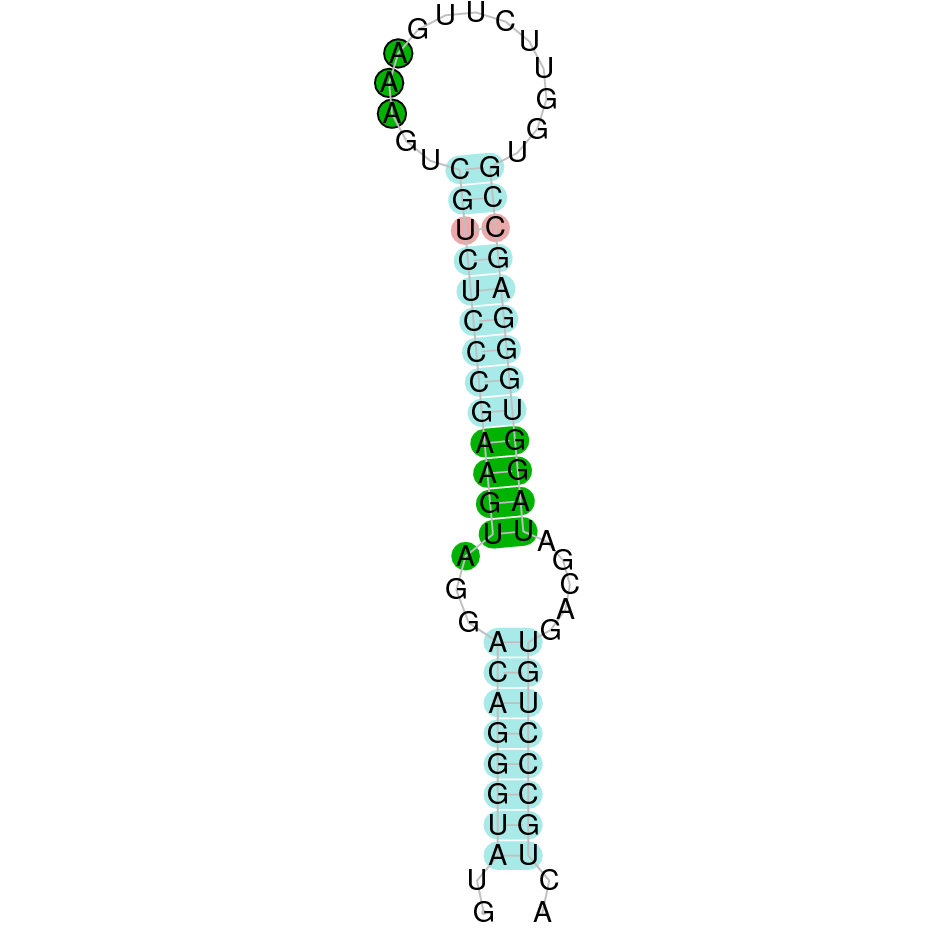
The results of the analysis are shown in the following table. It includes the scaffold where the alignment is found, the blast and exonerate analysis performed, the final alignment (T-coffee), its localization in Gekko japonicus genome and information about the SECIS elements found. Results are graphically represented in order to synthesize the process and ease the access to information and its comprehension.
| Final results show a selenocysteine of the query aligned with a selenocysteine of Gekko japonicus | Available file for this field | |||
| Final alignment may or may not contain selenocysteins in the query or/and the studied genome, but alignment between selenocysteins is not found. | Not available file for this field |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
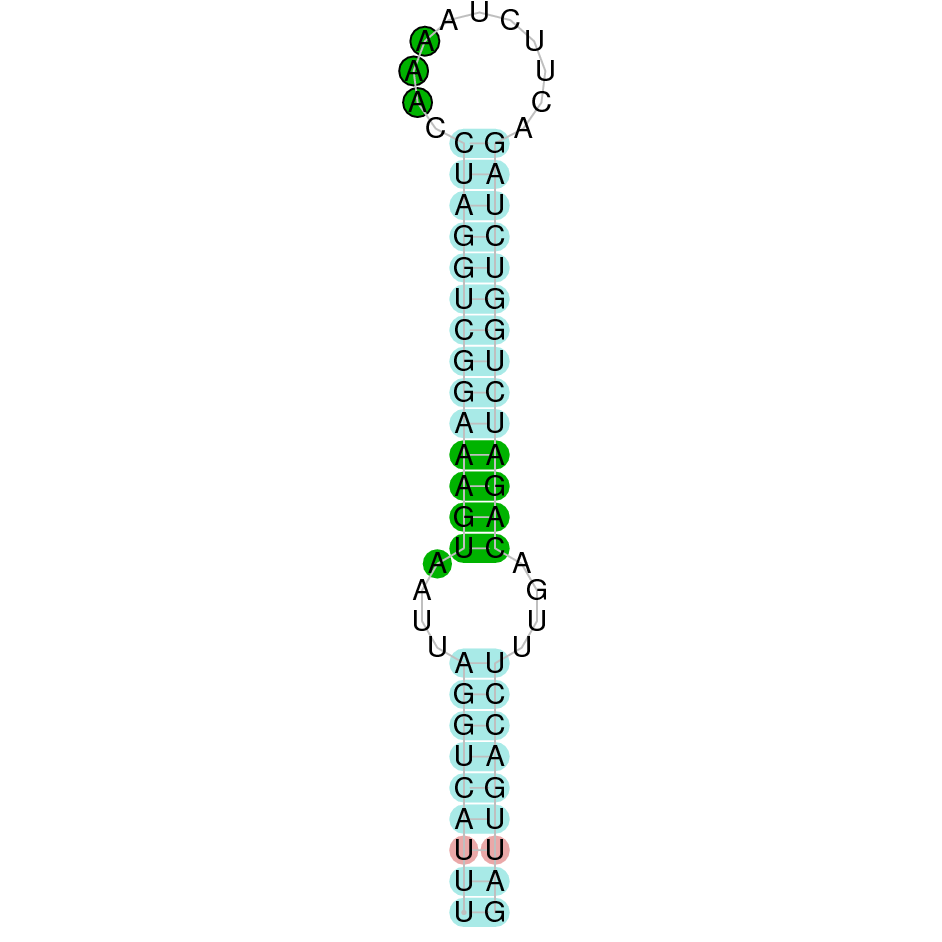{kind=link}
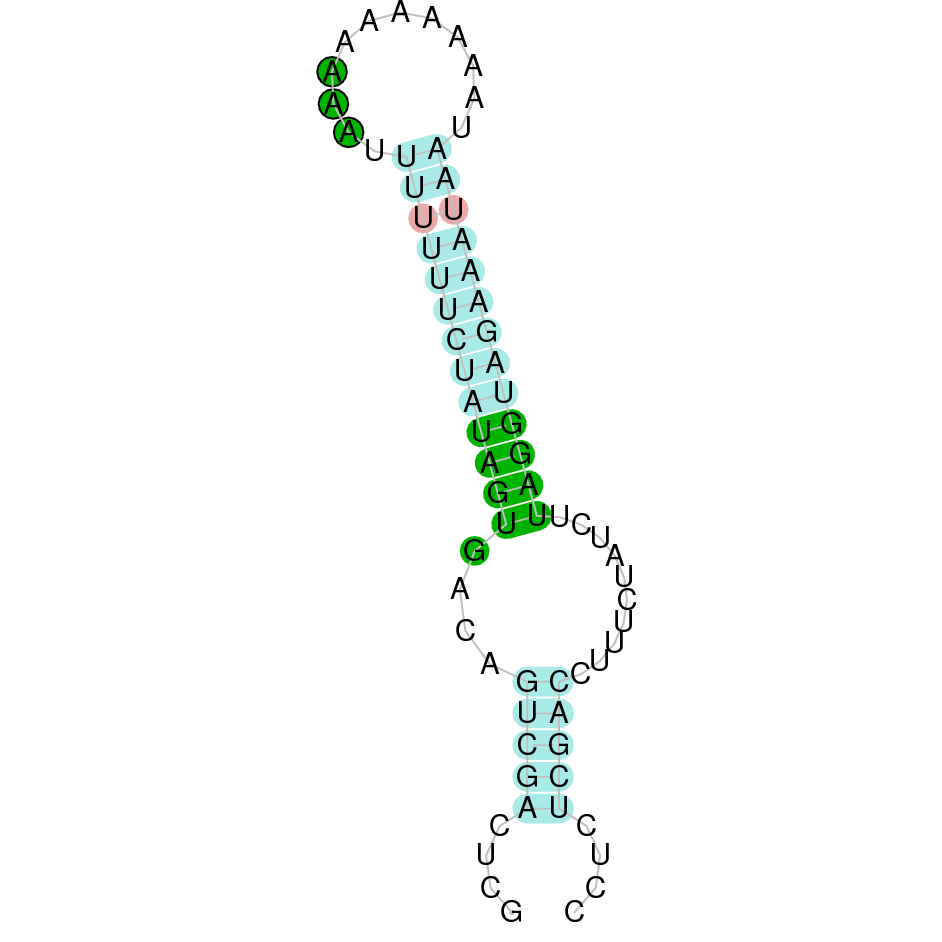{kind=link}
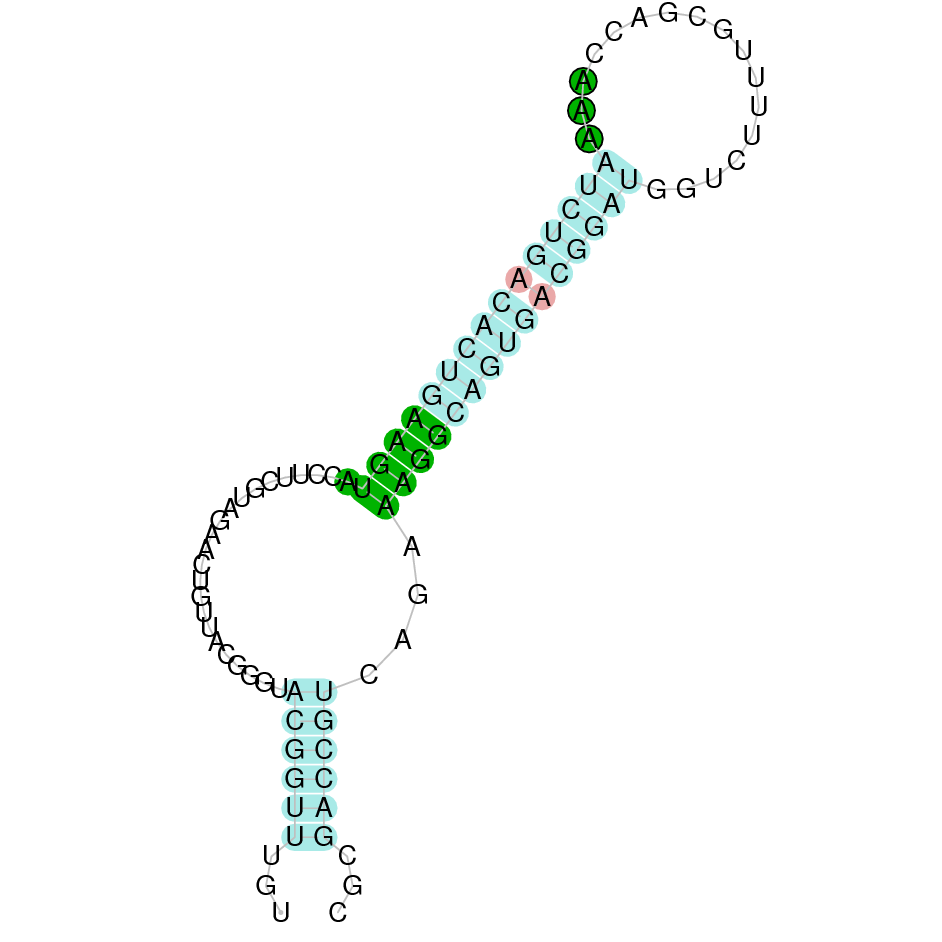{kind=link}
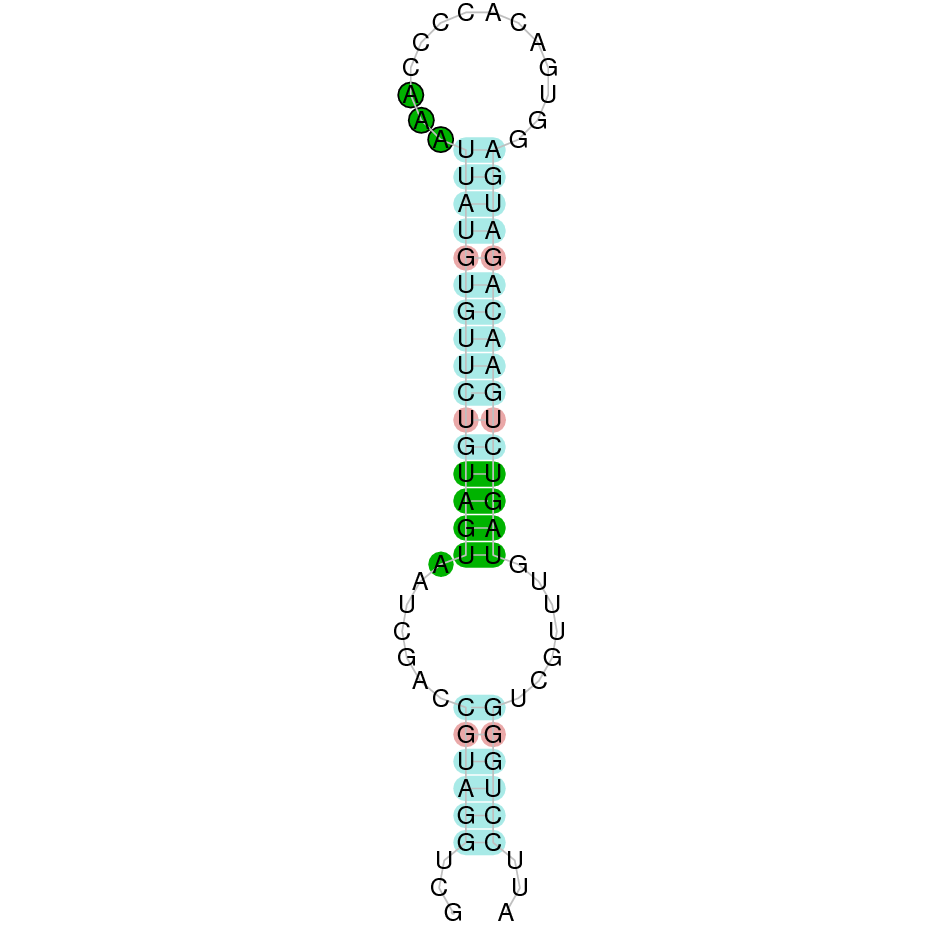{kind=link}
{kind=link}
All proteins predicted were also uploaded to the online database Selenodb
DISCUSSION
All the results obtained for every protein were analysed and discussed individually, paying special attention to the T-coffee outputs and SECIS predictions.
The following section presents the analysis of every protein results along with the predicted protein image extracted from Selenodb.
Legend of all the predicted protein images:

Selenoproteins
Sel15 family
Sel15
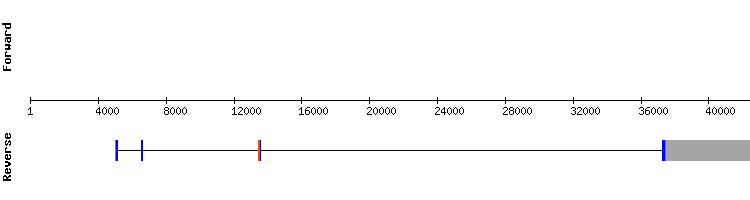
For this protein, significant hits were all found in the same scaffold. T-coffee results show an almost perfectly conserved alignment between the Anole carolinensis query and the studied sequence, with only a few punctual amino acid changes. Selenocysteine has been conserved, found in scaffold position 2256019-2256021, and aligning with the same residue in the reference sequence. No SECIS structure has been found. This result was unexpected since the SECIS structure should be found in all selenoprotein sequences, as it happens in the Anolis carolinensis sequence. Sel 15 is resolved to be a selenoprotein present in Gekko japonicus genome in scaffold KQ752576.1, It is encoded by a gene with four exons, same number as Anolis carolinensis Sel15 gene.
GPx family
GPx2
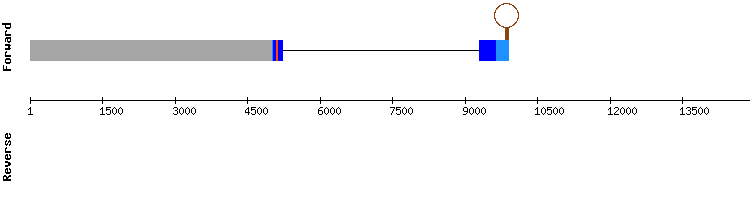
Significant hits were found in four different scaffolds, all containing a similar number of hits. Scaffold KQ751320.1 alignment results indicate the correct selenoprotein sequence, since T-coffee output shows the highest score (1000), no gaps and almost a perfectly conserved alignment. The selenocysteine residue is conserved and is found in scaffold position 44027-44029, aligned with the same residue of the reference sequence. Moreover, a possible SECIS structure is predicted. Therefore GPx2 is determined as a selenoprotein present in Gekko japonicus genome, encoded by a gene with two exons, same number as Anolis carolinensis GPx2 gene.
GPx3
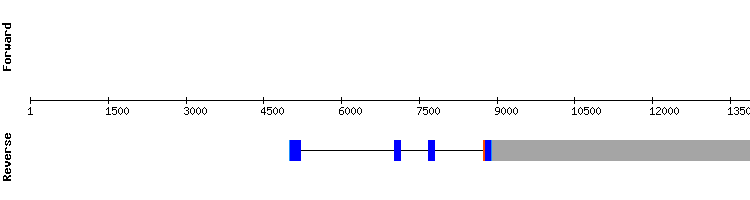
For GPx3 five scaffolds had significant hits, being scaffold KQ756805.1 the one selected. In this scaffold is where the sequence studied is believed to be located, since T-coffee output shows a very high score, no gaps and a small number of amino acid changes. A conserved selenocysteine is detected in scaffold position 201123-201125, aligning with the query’s selenocysteine. A SECIS structure is predicted, but since it is located at 5’ end of the sequence, it is dismissed.
However, since the selenocysteine is conserved GPx3 is likely to be a selenoprotein in Gekko japonicus encoded by a four exon gene, same number as the reference gene sequence. (Anolis carolinensis). Regarding the error in the predicted SECIS localization, we hypothesized that it could be consequence of a possible exon order change generated by one of the programs used in our analysis, since this type of error has also been observed in other selenoprotein predictions in the reverse chain.
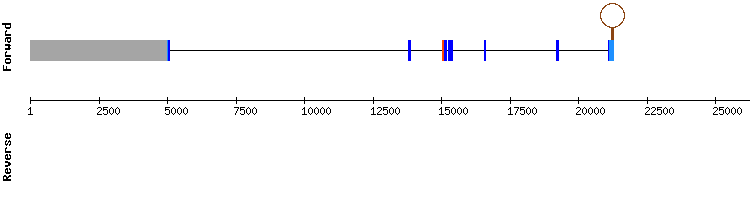
GPx4
The results obtained aligning Anolis carolinensis and Gekko japonicus sequences were not conclusive, due to the short amino acidic chain and lack of selenocysteines and cysteines. The study was then performed using Homo sapiens GPx4 sequence, and the results were much more decisive, as they showed a very high score, a small number of amino acid changes and two aligned selenocysteines. A SECIS structure was also predicted.
GPx4 is a selenoprotein that seems to be highly conserved during evolution, since almost the same sequence is found in Homo sapiens and Gekko japonicus, two relatively phylogenetically distant species. Its gene has seven exons.
GPx8
Three different scaffolds with similar number of significant hits appeared in this protein blast. The alignment results of scaffold KQ755490.1 were the most promising, with the highest score, no gaps and a small number of amino acid changes. None of the obtained results presented a selenocysteine in the reference nor studied sequence, and no selenocysteine is neither found in the human GPx8 sequence. This is consistent with the available information about GPx8, which indicates that this protein is an homologue with cysteine and not a truly selenoprotein, as previously explained in the introduction. As expected, no SECIS structure could be predicted. Thus, it is concluded that GPx8 is conserved in Gekko japonicus genome.
In the analysis results three exons appear, but the first one is only three nucleotide long and it is located very distant from the other two. Due to its length and distance it is concluded that this is a prediction error. ´This statement is compatible with the fact that reference gene is encoded by two exons.
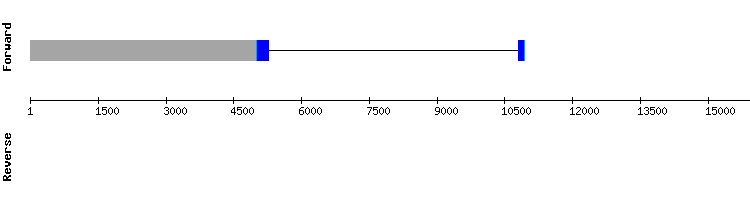
GPxa
Analysing this protein significant hits were found in six different scaffolds. The results involving scaffold KQ747955.1 were the most promising, with no gaps, the highest possible score and only a few amino acid changes. A selenocysteine alignment between sequences was also found in scaffold position 1142040-1142040, along with a correct SECIS prediction.
It is concluded that GPxa is a selenoprotein encoded by a two exon gene, as in Anolis carolinensis reference sequence. This protein may be an homologous of mammal GPx1 or 6, as both have a selenocysteine and were not previously predicted.
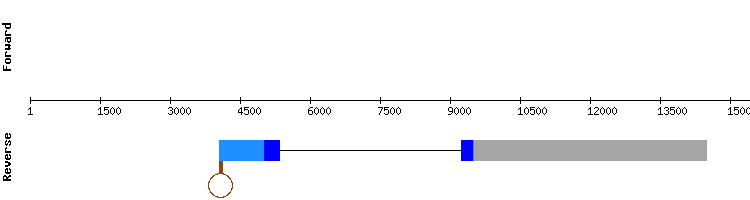
GPxb
The results showed significant hits in four scaffolds. The ones from scaffold KQ755490.1 had the best alignment, with no gaps and only a few amino acid changes. GPx8 is found in this same scaffold, but distantly located from the GPxb sequence. The possible protein predicted is encoded by a one exon gene. No selenocysteines appear in the reference or studied sequence, and, as expected, no SECIS structure could be predicted. Thus, is concluded that GPxb is not a selenoprotein. As some cysteine were aligned in T-coffee output, GPxb may be an homologous of mammal GPx5 or 7, two homologous in cysteine. Regarding the error in the predicted SECIS localization, we hypothesized that it could be consequence of a possible exon order change generated by one of the programs used in our analysis, since this type of error has also been observed in other selenoprotein predictions in the reverse chain.
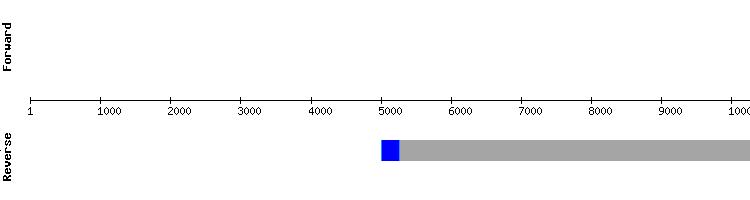
DIO family
DIO1
For DIO1 the analysis was firstly performed comparing the studied genome with Anolis carolinensis protein sequence. The results were not satisfying, since the output showed an alignment between two very short sequences (only one exon long in the studied genome). It was assumed that the Anolis carolinensis sequence was mistakenly described and truncated, thence the study was repeated with two other reference sequences (Homo sapiens and Pelodiscus sinensis).
From these second analysis Pelodiscus sinensis sequence presented the best alignment. This result was more encouraging than the first one, with a very conserved alignment at the first half segment of the protein and selenocysteines aligned between sequences. As explained in the results table tooltip four more X appeared at the last segment of the studied sequence, two of them corresponding to TGA codons. These X are believed to be stop codons as they do not correspond to any selenocysteine in the query, and their presence is believed to be the result of an error in the predicted alignement. The region where these X are found appear to be poorly conserved.
Both the alignment and the predicted SECIS structure resolve DIO1 as a selenoprotein present in Gekko japonicus genome codified by a four exon long gene. The results obtained for this protein could not be uploaded to Selenodb, since the sequence obtained was not multiple to 3 (probably due to the presence of a frameshift in the sequence).
DIO2
In this case hits are found in four significant scaffolds, though the correct prediction is very clear. Results from scaffold KQ757544.1 show an almost perfect alignment between sequences, a very high score and only a three nucleotide gap. Selenocysteine alignment is found, located at scaffold position 1080237-1080239 of the studied sequence.
SECIS element was also predicted. This SECIS may not be correct, as SelenoDB indicates that its position (1086660-1086735) is too distant from the last nucleotide coding for the protein (position 1080239). It is deduced that DIO2 is a selenoprotein encoded by a two exon gene in Gekko japonicus genome, differing from the Anolis carolinensis same protein, encoded by a three exon gene.
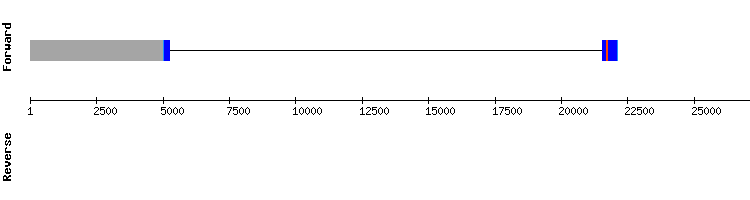
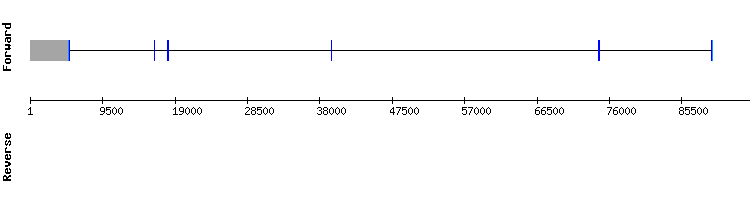
MsrA family
MsrA
Blast output displays a similar amount of hits in two different scaffolds. Scaffold KQ745055.1. results were selected, due to the less amount of gaps shown and the small number of amino acid changes between sequences. There are no selenocysteines either in Anolis carolinesis or Gekko japonicus sequence, and since four aligned cysteines are found, MSRA appears to be a selenoprotein homologue with cysteines. This is consistent with the mammal available literature, where MSRA appears as a cysteine-containing homologue.
The gene encoding this protein has seven exons, being distinct from Anolis carolinensis protein gene, that has five of them.
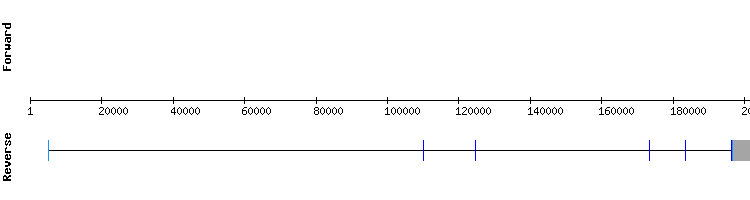
MSRB family
MSRB1
Blast output displays only one significant hit. T-Coffee results show only one gap, and small number of amino acid changes between sequences. There is a selenocysteine alignment at target sequence position 103833-103835.
The SECIS structure obtained from SECISearch3 was ambiguous, since it was positioned in between the two last exons of the predicted sequence (target sequence positions 107881 to 107965). In order to compare this results, the analysis was redone using Homo sapiens MSRB1 sequence as reference. The results were almost the same, with a less conserved alignment and an incorrect SECIS prediction. Therefore, the alignment obtained with Anolis carolinensis sequence was chosen as the valid one, even though it does not have a SECIS element predicted.
To conclude, MSRB1 is a selenoprotein encoded by a gene with four exons, contrasting from Anolis carolinensis protein gene, that has only two.
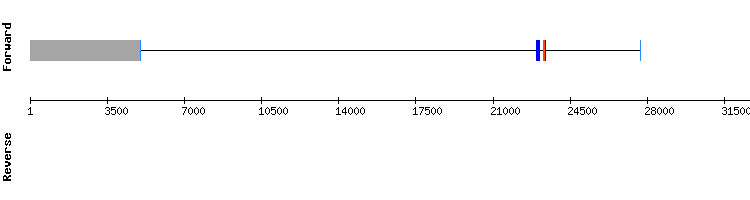
MSRB2
For MSRB2 hits in only one scaffold were found. The sequence studied is believed to be located in scaffold KQ747608.1, since T-coffee results show a very high score, no gaps and a small number of amino acid changes.
There are no selenocysteines detected neither in Gekko japonicus nor Anolis carolinensis sequences, and, consistently, no SECIS structures could be predicted. As in Anolis carolinensis, MSRB2 is not a selenoprotein. It is predicted as a protein encoded by a four exon gene, same as the reference Anolis carolinensis gene.
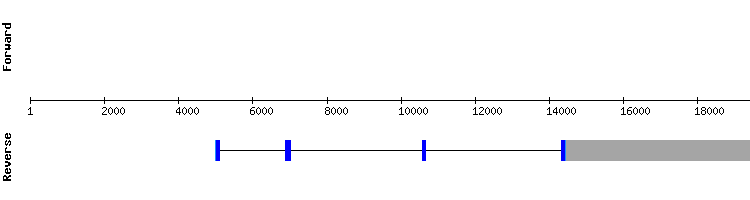
MSRB3
For MSRB2 hits in only one scaffold were found. The sequence studied is believed to be located in scaffold KQ747608.1, since T-coffee results show a very high score, no gaps and a small number of amino acid changes.
There are no selenocysteines detected neither in Gekko japonicus nor Anolis carolinensis sequences, and, consistently, no SECIS structures could be predicted. As in Anolis carolinensis, MSRB2 is not a selenoprotein. It is predicted as a protein encoded by a four exon gene, same as the reference Anolis carolinensis gene.
SEPHS family
SEPHS1
When comparing the SEPHS1 of Anolis carolinensis and the Gekko japonicus genome, the query aligned with a segment of the Gekko japonicus genome that codifies for another selenoprotein (SEPHS2). This may be caused by sequence similarities between SEPHS1 and SEPHS2. Since the results obtained with this analysis were not satisfying the study was repeated using the Homo sapiens protein sequence.
The results of this second analysis were more promising, with few amino acid changes and the selenocysteine alignment present. Two gaps appear at the beginning and end of the alignment, but it is not surprising due to the great phylogenetic distance between species.
A SECIS structure was also predicted, so it is deduced that SEPHS1 is a selenoprotein present in Gekko japonicus genome in scaffold KQ751895.1 and encoded by a ten exon gene.
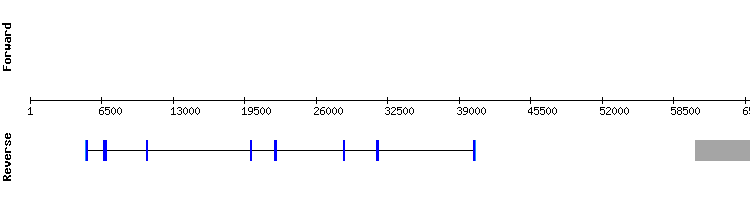
SEPHS2
For this protein significant hits were found in three different scaffolds. KQ752624.1 was selected as it has an almost perfect alignment. No selenocysteine residue was found either in the query sequence or in the target gene. Consequently, no SECIS structure was predicted. The presence of aligned cysteine residues may indicate that SEPHS2 is an homologous with cysteine.
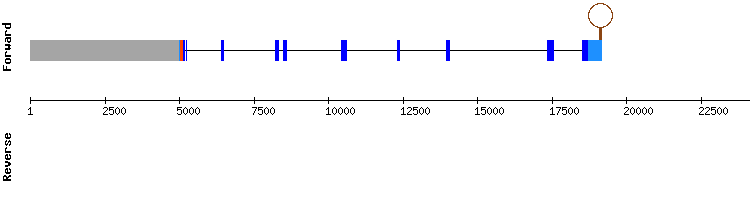
SELENOH family
SELENOH
For this protein two significant hits were found, both in the same scaffold. T-coffee results show some amino acid changes, but most of the residues that variate have similar properties. There is a conserved selenocysteine alignment at scaffold position 269825-269827.
No SECIS structure could be predicted, being unexpected due to the selenocysteine present. SELENOH is resolved to be a selenoprotein present in Gekko japonicus encoded by a two exon gene, same as in Anolis carolinensis protein. Despite the absence of a predicted SECIS structure, the presence of an aligned selenocysteine indicates that SELENOH is likely a selenoprotein.
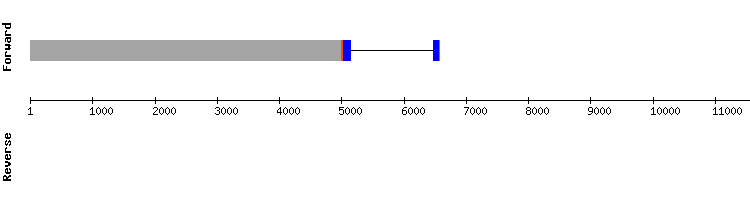
SELENOI family
SELENOI1
During the analysis of this protein four significant hits were found, three located in the same scaffold. Scaffold KQ751719.1 results presented a better alignment, with less gaps, best score and a selenocysteine alignment preserved at 567624-567626.
A SECIS element was also found. SELENOI1 is then resolved to be a selenoprotein encoded by a gene containing three exons, same as in Anolis carolinensis.
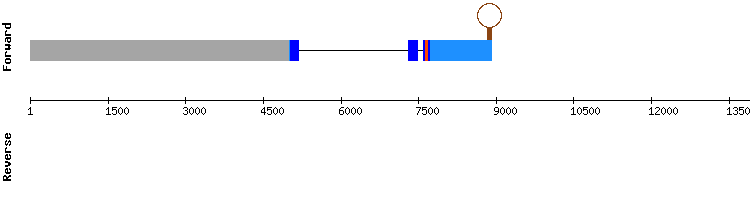
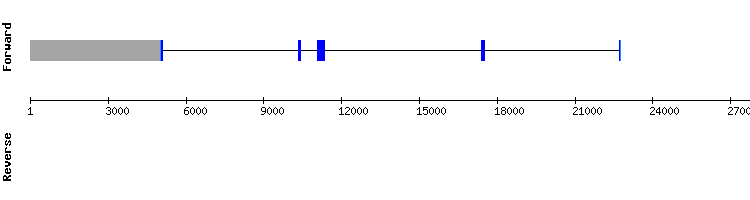
SELENOI2
During the analysis of this protein four significant hits were found, three located in the same scaffold. Scaffold KQ751719.1 results presented a better alignment, with less gaps, best score and a selenocysteine alignment preserved at 567624-567626.
A SECIS element was also found. SELENOI1 is then resolved to be a selenoprotein encoded by a gene containing three exons, same as in Anolis carolinensis.
SELENOK family
SELENOK
When analyzing this protein, no hits were found comparing the studied genome with Anolis carolinensis, Pelodiscus sinensis or Homo sapiens respective sequences.
SELENOK could not be found in Gekko japonicus genome. This might be the result of the loss of this protein in the studied genome, or an error in the genome annotation.
SELENOM family
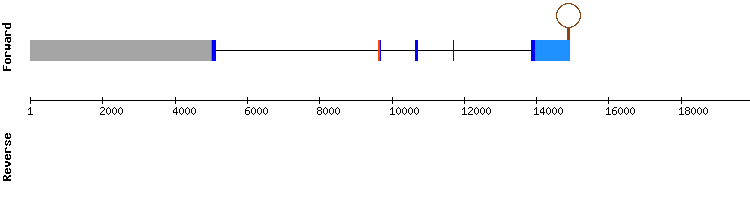
SELENOM
The analysis of this protein was performed using Homo sapiens protein sequence as reference, because the exons predicted using Anolis carolinensis sequence were not satisfying (an exon had only three nucleotides). Three hits were found in three different scaffolds, but the results obtained with scaffold KQ753014.1 were clearly the most promising, since in the results of the other two scaffolds only a small part of the sequence studied aligned.
The results showed a very conserved alignment near the selenocysteine position, and the two selenocysteines from both sequences were aligned. As previously noted in the results tooltip, another X appears in a poorly conserved region located in the middle of the sequence. Since this X corresponds to a non TGA stop codon, it does not affect the results or its veracity and its presence might be the result of the poor conservation of this region.
A SECIS structure was predicted. It is then concluded that SELENOM is a selenoprotein found in Gekko japonicus genome with a five exon gene, same as in Homo sapiens protein sequence.
SELENON family
SELENON
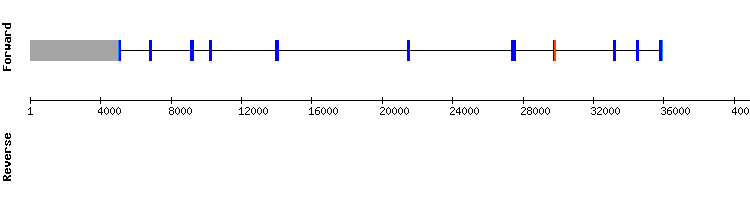
SELENON
For this protein, the blast output showed hits in two scaffolds. The results obtained with scaffold KQ750069.1 were selected due to the almost perfectly conserved alignment shown in the T-coffee output, with only a few amino acid changes. Moreover, the selenocysteine residue was conserved and aligned with the reference sequence at target scaffold position 1187202-1187204.
A SECIS structure was also predicted, but it may not be correct, as SelenoDB indicates that its position is too distant from the codifying region. SELENON is resolved to be a selenoprotein perfectly conserved between Anolis carolinensis and Gekko japonicus species, encoded by an eleven exon gene.
SELENOO family
SELENOO
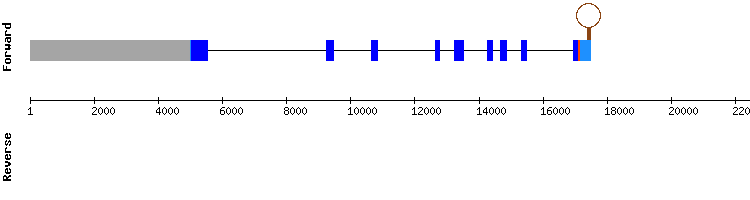
In the SELENOO analysis performed with the two different available Anolis carolinensis querys, the results were not satisfactory due to the presence of multiple non-TGA stop codons. Therefore, the procedure was redone with the corresponding Homo sapiens sequence.
For this second analysis eleven hits were found in two different scaffolds. Results from scaffold KQ750079.1 were selected taking into account the selenocysteine alignment present (target scaffold position 226858-226860) and the high score compared to the other alignments. The T-Coffee output reveals an almost perfect alignment, with only one gap at the beginning of the alignment and few amino acid changes.
A SECIS element was also predicted. It is concluded that SELENOO is a selenoprotein encoded by a gene with eleven exons, differing from the reference protein, encoded by a nine exon gene. In order to upload this found selenoprotein to SelenoDB, the Seblastian prediction was required since the exonerate prediction was not accepted due to its length (not multiple of three).
SELENOP family
SELENOP1
In this case five significant hits were found in two different scaffolds. The T-coffee data of the selected scaffold (KQ748396.1) showed a highly conserved alignment with a very high score. A selenocysteine residue is found in the target sequence position 672316-672318 aligned with the same residue in the query. A SECIS element was also predicted.
Our findings for SELENOP1 in the Gekko japonicus genome point out that this could be a selenoprotein encoded by a three exon gene, same as the reference sequence. These outcomes will be furtherly discussed after the SELENOP2 result description in the following section.
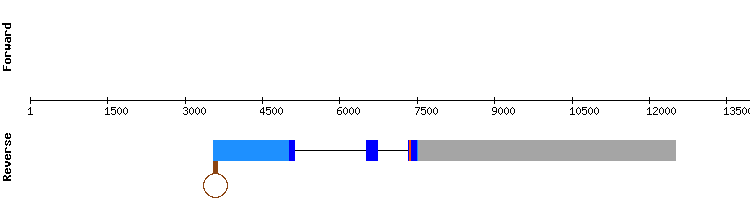
SELENOP2
For this protein the results involving scaffold KQ756314.1 were the most promising, with no gaps, the highest possible score and less amino acid changes. A selenocysteine alignment between sequences was also found in target scaffold position 1513886-1513888, and a correct SECIS element was predicted.
Our findings for SELENOP2 in the Gekko japonicus genome point out that this could also be a selenoprotein encoded by a three exon gene, same as Anolis carolinensis.
It is necessary to take into account that in mammals SELENOP family is formed by only one selenoprotein (SELENOP). Even so, the analysis was performed with two different protein sequences, since Anolis carolinensis had two different sequences annotated for SELENOP. Since both results appeared to be correct, it is not possible to know if these two predicted proteins correspond to a copy of the SELENOP gene, or if Gekko japonicus has two different SELENOP proteins.
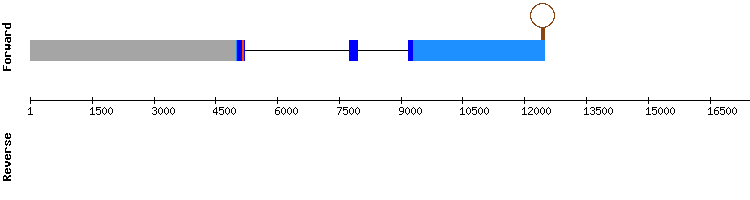
SELENOS family
SELENOS
For MSRB2 hits in only one scaffold were found. The sequence studied is believed to be located in scaffold KQ747608.1, since T-coffee results show a very high score, no gaps and a small number of amino acid changes.
There are no selenocysteines detected neither in Gekko japonicus nor Anolis carolinensis sequences, and, consistently, no SECIS structures could be predicted. As in Anolis carolinensis, MSRB2 is not a selenoprotein. It is predicted as a protein encoded by a four exon gene, same as the reference Anolis carolinensis gene.
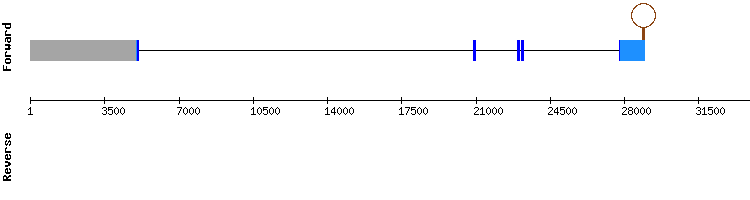
SELENOT family
SELENOT
For this protein, significant hits were all found in the same scaffold, KQ745070.1. T-coffee results show an almost perfectly conserved alignment between the Anolis carolinensis query and the studied sequence, with only few punctual amino acid changes.
Selenocysteine has been conserved at scaffold position 817556-817558, being aligned with the selenocisteyne of the reference SELENOT. A SECIS structure has been found.
SELENOT is resolved to be a selenoprotein present in Gekko japonicus. It is encoded by a gene with four exons, same number as the Anolis carolinensis SELENOT gene.
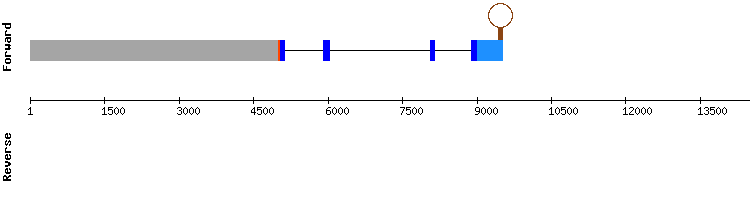
SELENOU family
SELENOU1
Two different scaffolds with significant hits appeared in this protein analysis. The alignment results of scaffold KQ752674.1 were the most promising, with the highest score, a short gap and some amino acid changes. One selenocysteine was found at position 43724-43726 in Gekko japonicus genome, and it is aligned with the query Sec residue. A SECIS structure could be predicted.
Thus, it is concluded that SELENOU1 in Gekko japonicus is a selenoprotein. The protein gene is encoded by five exons, same number as the reference gene.
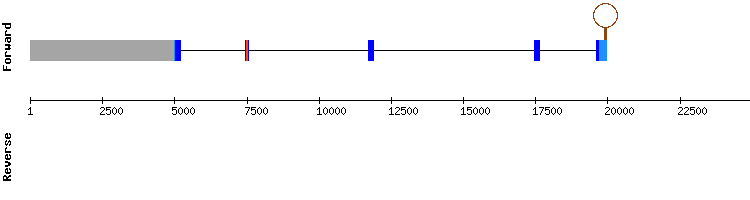
SELENOU2
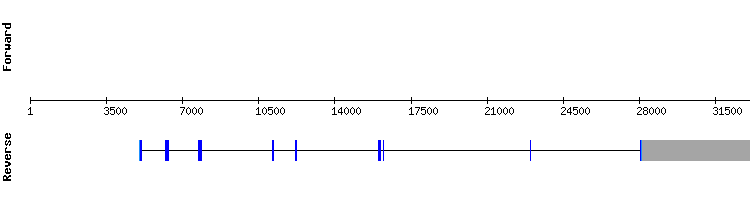
Analysing SELENOU2, significant hits were all detected in one single scaffold (KQ750554.1). The results of the T-coffee show a correct alignment, though it has one gap. There are no selenocysteines present in any of the two species sequences, and there is neither a SECIS element prediction.
It is concluded that SELENOU2 is not a selenoprotein, and is encoded by a nine exon gene, differing from the reference protein gene, that has six.
SELENOW family
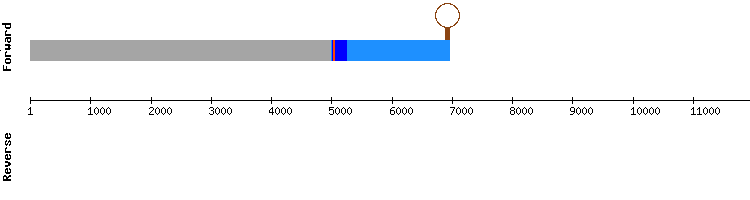
SELENOW1
For this protein blast output displays two significant hits in two different scaffolds. Scaffold KQ757562.1 hits were selected due to the less amount of gaps shown and the small number of amino acid changes between sequences. There is a selenocysteine alignment in the target sequence position 113115-113117.
As mentioned in the results tooltip, in Gekko japonicus sequence two extra X were found, corresponding to TGA and TAA codons. The first TGA codon in the Gekko japonicus sequence is aligned with a cysteine, which is compatible with the presence of a selenocysteine in this position. This possibility can not be dismissed: however, it is highly unlikely because these type of selenoproteins usually have only one selenocysteine. The other one is aligned with glutamate, indicating a sequentiation error or a pseudogene.
The presence of the aligned X may indicate SELENOW1 is a selenoprotein in Gekko japonicus genome. This is supported with a SECIS prediction. However, the presence of the third X does not allow to conclude this. The gene encoding this protein has one exon, same as in the Anolis carolinensis gene.
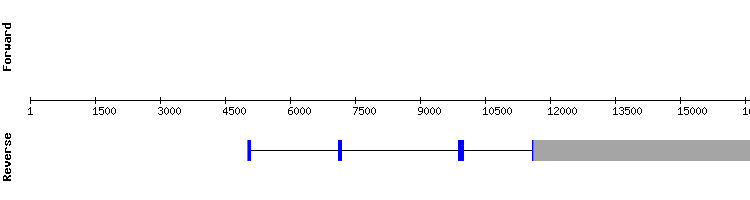
SELENOW2
Blast output displays three significant hits, all in the same scaffold (KQ752146.1). The T-coffee results show one gap and very few amino acid changes between sequences.
There are no selenocysteines neither in Anolis carolinesis nor Gekko japonicus sequence, and since three aligned cysteines are predicted, the possibility that SELENOW2 may be a selenoprotein homologue with cysteines exists. The gene encoding this protein has four exons, being distinct from Anolis carolinensis protein gene, that has only two. This gene has no SECIS structure predicted.
TXNRD family
TXNRD1
For TXNRD family predictions, Homo sapiens querys were needed due to the lack of some of the members of this family in the Anolis carolinensis anotated proteins.The results showed a conserved alignment with high score, but an almost forty amino acid long gap at the beginning of the sequence. Even the gap, the prediction is considered as correct, supported by a selenocysteine alignment found between sequences and the presence of a SECIS element.
TXNRD1 is resolved to be a selenoprotein found in Gekko japonicus genome encoded by a fifteen exon gene.
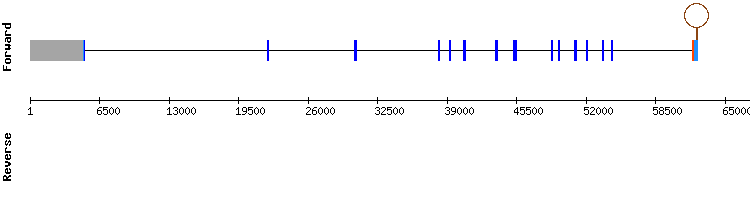
TXNRD2
As previously explained, the prediction of TXNRD2 was also performed using an Homo sapiens sequence as reference. The results in scaffold KQ749205.1 presented an almost perfectly conserved alignment, with no gaps and the highest score. Exonerate results presented a seventeen exon long sequence, but since the first exon was 23 nuclotide long and situated in a very distant position from the rest, it was believed to be a prediction error. A SECIS structure was predicted, but SelenoDB indicated that it was too distant from the coding sequence, so it is not clear if this is a suitable SECIS. The presence of the aligned selenocysteine makes it likely for the predicted TXNRD2 to be a selenoprotein present in Gekko japonicus genome, encoded by a sixteen exon gene.
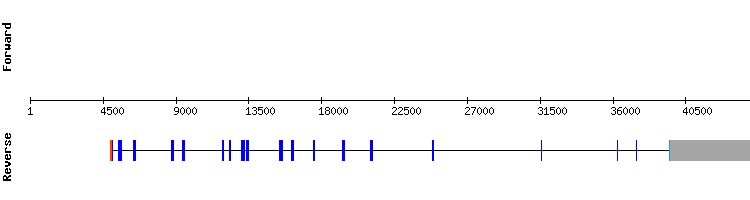
TXNRD3
In contrast with the other two proteins of the TXNRD family, the analysis of this protein was performed comparing the studied genome with the Anolis carolinensis sequence, as this species has its TXNRD3 annotated. The results obtained showed a conserved alignment, only a small gap and the presence of a selenocysteine aligning with the target sequence.
The predicted SECIS structure was located in the middle of the TXNRD3 sequence, and due to this result, the analysis was performed again using the Homo sapiens sequence as reference. The results were similar and the SECIS structure was still positioned in the middle of the sequence. Therefore, even not finding an adequate SECIS element, it is deduced that TXNRD3 is a selenoprotein found in Gekko japonicus encoded by a nineteen exon gene.
Translation machinery
Consistently with the available information of the proteins involved in the biosynthesis of selenoproteins (Translation Machinery), our results support the absence of selenocysteine and SECIS structure in these type of proteins.
eEFsec family
eEFsec1
For this protein only one significant hit was found. This hit was located in the scaffold KQ757173.1. T-coffee results showed a highly conserved sequence with no selenocysteines, being consistent consistent with the available information about eEFsec in mamals since this protein belongs to the transcription machinery and it is not a selenoprotein.
The predicted gene contains two exons and has no SECIS element. In Anole carolinensis there is only one exon and no SECIS element neither. Thus, it is concluded that the eEFsec family member known as eEFsec1 is conserved between Gekko japonicus and Anolis carolinensis genomes.
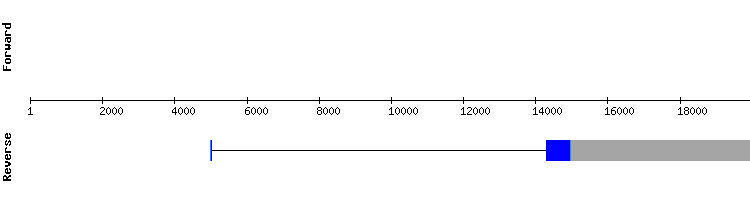
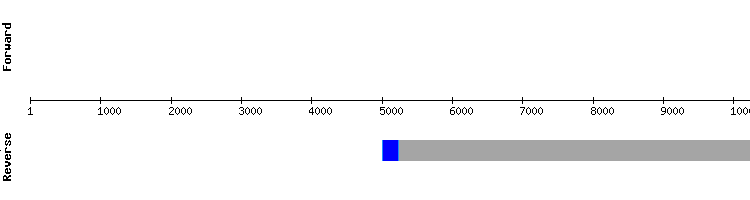
eEFsec2
For this protein there was only one significant hit in the same scaffold than eEFsec1, but in different positions. When analyzing this hit, it was observed that the first nucleotide of the target sequence was located very distant from the rest of the predicted sequence. Since a nucleotide long exon is highly unlikely, it is strongly believed that the nucleotide coded by this exon has been incorrectly aligned .
The eEFsec2 protein is predicted in Gekko japonicus genome as a one exon long gene, same as in Anolis carolinensis, with no SECIS structure nor selenocysteines present. However, as explained in the next section, the positions of this predicted gene match exactly one of the exons predicted for eEFsec3, suggesting that these proteins are product of alternative splicing processesor the fact that eEFsec2 does not really exists in Gekko japonicus genome.
eEFsec3
The results obtained for this protein showed a conserved alignment with a high score in the same scaffold as eEFsec1 and eEFsec2. It was noticed that one of the predicted exons of this protein matched the one-exon long gene predicted for eEFsec2. This may be due the result of an alternative splicing process or because eEFsec2 does not really exist in Gekko japonicus genome, and the protein predicted in eEFsec2 analysis is in fact a region of eEFsec3 very similar to the Anolis carolinensis query for eEFsec2.
eEFsec3 is predicted in the Gekko japonicus genome as a translation machinery protein encoded by three exons, same as in Anolis carolinensis.
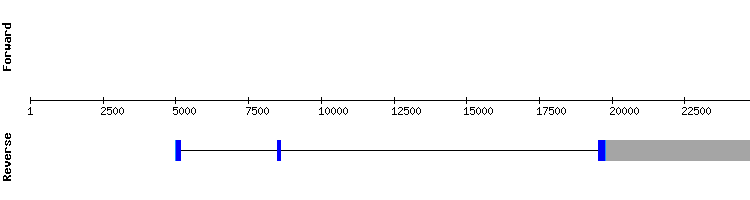
SecS family
SecS
Eleven significant hits were found for this protein, ten from the same scaffold (KQ752578.1). The results show a conserved alignment with one initial gap.
There is no selenocysteine or SECIS element. The target predicted gene contains twelve exons, while the reference gene has eleven. It is concluded that SecS is a protein involved in the selenoproteins translational machinery found in Gekko japonicus genome.
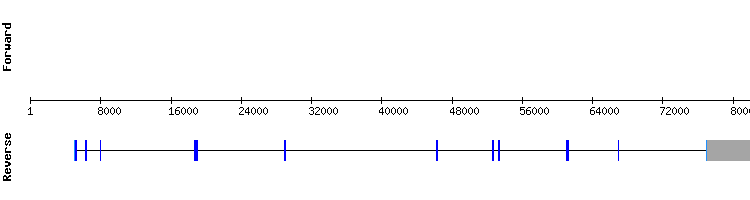
PSTK family
PSTK
Eleven hits in five different scaffolds were found when analysing this protein. The results of scaffold KQ753020.1 showed a conserved alignment and a high score, but also a 48 amino acid-long gap at the initial region of the sequence. In scaffold LNDG01243685.1 results, a conserved alignment appeared only within the first 63 amino acids.
Therefore, as explained in the results tooltip, it was deduced that the first segment of the PSTK sequence is found in Gekko japonicus LNDG01243685.1 scaffold, and the rest in scaffold KQ753020.1. These findings could be explained by the fact that PSTK gene was divided into two scaffolds when annotating the Gekko japonicus genome.
It is concluded that PSTK is a protein found in Gekko japonicus genome encoded by a seven exon gene found in two separate parts of the genome.
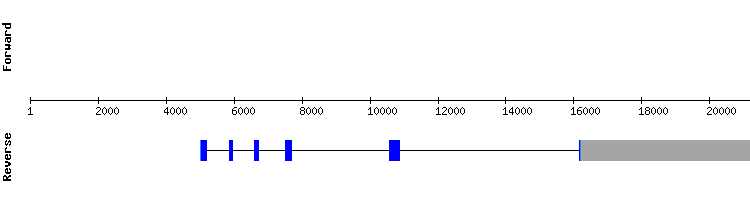
SBP2 family
SBP21
For this protein fifteen significant hits were found, all of them located in two different scaffolds. KQ757972.1 was selected: the alignment is correct and the gene has seventeen exons (the reference gene has sixteen). It has no SECIS element, and neither does the reference gene.
The nearly perfect alignment indicates the presence of SBP21 in Gekko japonicus genome, but this protein could not be uploaded to SelenoDB beacuse the sequence predicted was not multiple of three.
SBP22
In this protein fifteen significant hits were obtained. The scaffold selected was KQ748789.1. The T-coffee data reveal a correct alignment with no selenocysteines.
This gene has nineteen exons in Gekko japonicus, and seventeen in Anolis carolinensis. There are no SECIS elements. Again, the nearly perfect alignment indicates the presence of this protein in the Gekko japonicus genome.
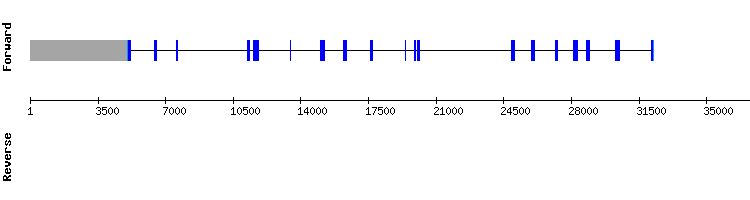
SECp43 family
SECp43
The analyisis of this protein using the query of Anolis carolinesis showed some prediction errors, and thus it was redone using the correspondent query of Pelodiscus sinensis.
Blast output displays a similar amount of hits in five different scaffolds. Scaffold KQ748792.1 results were selected, because they show very few amino acid changes. No SECIS element could be predicted for this protein. The predicted gene using this Pelodiscus sinensis sequence was highly conserved in Gekko japonicus genome, containing eight exons (the same number as the reference gene).
CONCLUSIONS
The aim of the present study was to characterize the presence of known selenoproteins in the Gekko japonicus genome. After all the analysis performed, we have been able to predict twenty-two selenoproteins and seven associated machinery proteins. Seven more proteins have been characterized as cyteine-containing.
The selenoproteins predicted in the studied genome are: Sel15, Gpx2, Gpx3, Gpx4, Gpxa, DIO1, DIO2, MSRB1, SEPHS2, SELENOH, SELENOI1, SELENOM, SELENON, SELENOO, SELENOP1, SELENOP2, SELENOT, SELENOU1, SELENOW1, TXNRD1, TXNRD2 and TXNRD3.
The translation machinery proteins found are: eEFsec1, eEFsec2, eEFsec3, SecS, PSTK, SBP21, SBP22 and SECp43.
The rest of the predicted proteins are either cysteine-containing homologous or special cases discussed in the previous section.
Overall, our findings point out that the selenoproteome of Gekko japonicus is fairly conserved in comparison to the described selenoproteins of other vertebrates, since proteins of almost all the families were successfully characterized. However, some unexpected features were found. For example, we observed repeatedly in different analysis that the initial amino acids of some Homo sapiens annotated proteins were absent in the Anolis carolinensis annotations and the Gekko japonicus genome.
As previously explained, there were some cases in which the outcome was not optimal, as some proteins could not be predicted or showed ambiguous results. A possible explanation for this is the fact that the Gekko japonicus genome seems to be presenting missanotation issues, and some sequences were repited in different scaffolds.
Gekko japonicus special properties, such as tail regeneration and adhesion ability, make this reptile an interesting model of study. (32)(33) The newly described information about selenoproteins in the Gekko japonicus broadens and complements the available information about the reptile, and provide a further insight in the complete characterization of this extraordinary organism.
ACKNOWLEDGEMENTS
We would like to thank all the people that helped in this project, either teaching us bioinformatics concepts or solving our doubts.
First, we would like to thank both Robert Castelo and Cedric Notredame since they taught us all Unix bases, which were necessary to start this project. We would like to thank also Toni Gabaldón, because he taught us the principles to develop a website. It is necessary to be grateful also with Roderic Guigó for initiate us in selenoproteins world with his magistral lessons. Finally we would like to thank Diego Garrido and Didac Santesmases for the help during the analysis process.
REFERENCES
(1) Bellinger FP, Raman AV, Reeves MA, Berry MJ. Regulation and function of selenoproteins in human disease. Biochem J. July 2009;422(1):11-22
(2) Burk RF, Hill KE, Motley AK. Selenoprotein Metabolism and Function: Evidence for More than One Function for Selenoprotein P. J Nutr. July 2003;133(5):1517-20
(3) Lu J, Holmgren A. Selenoproteins. The Journal of Biological Chemistry. January 2009;284(2):723-7
(4) Atkins JF, Gesteland RF. Translation: The twenty-fist amino acid. Nature 2000; 407: 463-465.
(5) Copeland PR, Fletcher JE, Carlson BA, Hatfield DL, Driscoll DM. A novel RNA binding protein, SBP2, is required for the translation of mammalian selenoprotein mRNAs. EMBO J. January 2000;19(2):306-314
(6) Mariotti M, Ridge PG, Zhang Y, Lobanov AV, Pringle TH, Guigó R, et al. Composition and Evolution of the Vertebrate and Mammalian Selenoproteomes. PLoS ONE. March 2012;7(3):e33066
(7) Copeland PR, Fletcher JE, Carlson BA, Hatfield DL, Driscoll DM. A novel RNA binding protein, SBP2, is required for the translation of mammalian selenoprotein mRNAs. The EMBO Journal. 2000;19(2):306-314.
(8) Papp LV, Lu J, Holmgren A, Khanna KK. From Selenium to Selenoproteins: Synthesis, Identitiy and Their Role in Human Health. Antioxid. Redox Signal [revista a Internet]. 2007; 9(7): 775-806. Disponible a: http://online.liebertpub.com/doi/pdf/10.1089/ars.2007.1528
(9) Brown KM, Arthur JR. Selenium, selenoproteins and human health: a review. Public Health Nutr. 2001; 4(2B): 593-599.
(10) Moghadaszadeh B, Beggs A. Selenoproteins and Their Impact on Human Health Through Diverse Physiological Pathways. APS. 2006; 21 (5): 307-315.
(11) Labunskyy VM, Hatfield DL, Gladyshev VN. Selenoproteins: Molecular Pathways and Physiological Roles. Physiol Rev. July 2014;94(3):739-777
(12) Lee BC, Dikiy A, Kim HY, Gladyshev VN. Functions and Evolution of Selenoprotein Methionine Sulfoxide Reductases. Biochim Biophys Acta. November 2009;1790(11):1471-1477
(13) MSRA (Methionine Sulfoxide Reductase A) [Internet]. NCBI. May 2014 [updated 26 November 2016: cited 6 December 2016]. Available from:
(14) Boukhzar L, Hamieh A, Cartier D, Tanguy Y, Alsharif I, Castex M, et al. Selenoprotein T Exerts an Essential Oxidoreductase Activity That Protects Dopaminergic Neurons in Mouse Models of Parkinson’s Disease. Antioxid Redox Signal. April 2016;24(11):557-74
(15) Castex MT, Arabo A, Bénard M, Roy V, Le Joncour V, Prévost G, et al. Selenoprotein T Deficiency Leads to Neurodevelopmental ABnormalities and Hyperactive Behavior in Mice. Mol Neurobiol. November 2016;53(9):5818-32
(16) Cox AG, Tsomides A, Kim AJ, Saunders D, Hwang KL, Evason KJ, et al. Selenoprotein H is an essential regulator of redox homeostasis that cooperates with p53 in development and tumorigenesis. Proc Natl Acad Sci USA. September 2016;113(38):E5562-71
(17) Yan J, Fei Y, Han Y, Lu S. Selenoprotein O deficiencies suppress chondrogenic differentiation of ATDC5 cells. Cell Biol Int. October 2016;40(10):1033-40
(18) Gonzalez-Flores JN, Gupta N, DeMong LW, Copeland PR. The selenocysteine-specific elongation factor contains a novel and multi-functional domain. J Biol Chem. 2012; 287(46): 38936-45
(19) Carlson BA, Xu XM, Kryukov GV, Rao M, Berry MJ, Gladyshev VN, et al. Identification and characterization of phosphoseyl-tRNA[Ser]Sec kinase. Proc Natl Acad Sci U S A. August 2004;101(35):12848-53.
(20) Squires JE, Berry MJ. Eukaryotic Selenoprotein Synthesis: Mechanistic Insight Incorporating New Factors and New Functions for Old Factors. April 2008;60(4):232-235.
(21) Gekko japonicus (SCHLEGEL, 1836) [Internet]. The Reptile Database [cited 13 November 2016]. Available from: http://reptile-database.reptarium.cz/species?genus=Gekko&species=japonicus
(22) Toda M, Okada S, Hikida T, Ota H. Extensive Natural Hybridization Between Two Geckos, Gekko tawaensis and Gekko japonicus (Reptilia: Squamata), Throughout Their Broad Sympatric Area. Biochemical Genetics. 2006;44(1-2):1-17.
(23) Invasive Species of Japan: Gekko japonicus [Internet]. National Institute for Environmental Studies. 2016 [cited 13 November 2016]. Available from: https://www.nies.go.jp/biodiversity/invasive/DB/detail/30160e.html
(24) Liu Y, Zhou Q, Wang Y, Luo L, Yang J, Yang L et al. Gekko japonicus genome reveals evolution of adhesive toe pads and tail regeneration. Nature Communications. 2015;6:10033.
(25) Nguyen TQ, Wang YY, Yang JH, Lehmann T, Le MD, Zeigler T, et al. A new species of the Gekko japonicus group (Squamata: Sauria: Gekkonidae) from the border region between China and Vietnam. Zootaxa. 2013;3652:501-18.
(26) SelenoDB: selenoproteins database [Internet]. Selenodb.org. 2016 [cited 3 December 2016]. Available from: http://www.selenodb.org/
(27) BLAST: Basic Local Alignment Search Tool [Internet]. Blast.ncbi.nlm.nih.gov. 2016 [cited 3 December 2016]. Available from: https://blast.ncbi.nlm.nih.gov/Blast.cgii
(28) Exonerate | European Bioinformatics Institute [Internet]. Ebi.ac.uk. 2016 [cited 3 December 2016]. Available from: http://www.ebi.ac.uk/about/vertebrate-genomics/software/exonerate
(29) T-COFFEE Multiple Sequence Alignment Server [Internet]. Tcoffee.crg.cat. 2016 [cited 3 December 2016]. Available from: http://tcoffee.crg.cat/
(30) Selenoprotein prediction server [Internet]. Seblastian.crg.es. 2016 [cited 3 December 2016]. Available from: http://seblastian.crg.es/
(31) GeneWise < Pairwise Sequence Alignment < EMBL-EBI [Internet]. Ebi.ac.uk. 2016 [cited 5 December 2016]. Available from: http://www.ebi.ac.uk/Tools/psa/genewise/
(32) Gu Y, Yang J, Chen H, Li J, Xu M, Hua J et al. Different Astrocytic Activation between Adult Gekko japonicus and Rats during Wound Healing In Vitro. PLOS ONE. 2015;10(5):e0127663.
(33) Boesel L, Greiner C, Arzt E, del Campo A. Gecko-Inspired Surfaces: A Path to Strong and Reversible Dry Adhesives. Advanced Materials. 2010;22(19):2125-2137.
AUTHORS

CARLOTA BELLOT

MARCEL LUCAS

IRENE ORTEGA
