Universitat Pompeu Fabra.
Curs 2006-2007
El nostre treball consisteix en l’estudi genòmic computacional de la proteïna de fusió AML1-MTG8 . Aquesta proteïna era la que presentava una identitat més alta i un evalue més baix després de realitzar un tBLASTn amb la seqüència aminoacídica assignada.
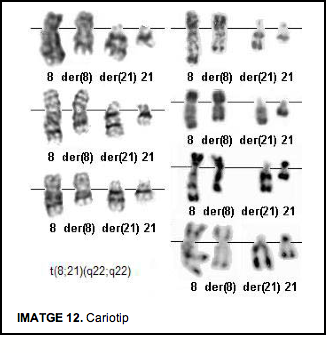
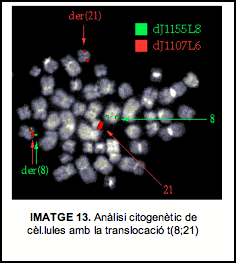
Aquesta proteïna es forma com a resultat de la translocació t(8;21) que és una de les translocacions més freqüents en la leucèmia mieloide aguda .
Aquesta translocació es produeix degut al trencament en un intró específic del gen AML1 al cromosoma 21. Aquest fragment del gen AML1 s’introdueix al costat del gen MTG8 al cromosoma 8 de manera que la pauta de lectura es manté i el resultat és un trànscrit de fusió AML1-MTG8 que en transcriure’s donarà lloc a la proteïna de fusió AML1-MTG8.
Al tractar-se d’una proteïna que tan sols és present en cas de malaltia per assolir els objectius del treball treballarem amb les dues proteïnes i els seus gens corresponents independentment però sempre que sigui possible s’intentarà comparar els resultats obtinguts amb la proteïna de fusió que és l’objectiu principal del treball.
Dels resultats obtinguts després de realitzar un tBLASTn a partir de la seqüència peptídica assignada ens vam quedar amb el que presentava una identitat més elevada amb un Score més alt i un evalue més baix. Aquest resultat corresponia al transcrit de la proteïna de fusió AML1-MTG8.
Al tractar-se d’una proteína de fusió quan realitzavem aliniaments amb altres bases de dades només trobàvem dos fragments d’alta homologia amb la nostra seqüència que corresponien a les dues proteïnes que formen part de la proteïna de fusió independentment.
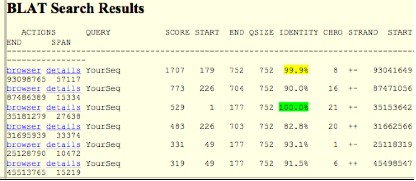
Aquest és el resultat obtingut després de realitzar un BLAT a la base de dades UCSC.
Veiem que aquest dos fragments amb alta identitat corresponen a les proteïnes MTG8 i AML1:
MRIPVDASTSRRFTPPSTALSPGKMSEALPLGAPDAGAALAGKLRSGDRSMVEVLADHPGELVRTDSPNF LCSVLPTHWRCNKTLPIAFKVVALGDVPDGTLVTVMAGNDENYSAELRNATAAMKNQVARFNDLRFVGRS GRGKSFTLTITVFTNPPQVATYHRAIKITVDGPREPRNRTEKHSTMPDSPVDVKTQSRLTPPTMPPPPTT QGAPRTSSFTPTTLTNGTSHSPTALNGAPSPPNGFSNGPSSSSSSSLANQQLPPACGARQLSKLKRFLTT LQQFGNDISPEIGERVRTLVLGLVNSTLTIEEFHSKLQEATNFPLRPFVIPFLKANLPLLQRELLHCARL AKQNPAQYLAQHEQLLLDASTTSPVDSSELLLDVNENGKRRTPDRTKENGFDREPLHSEHPSKRPCTISP GQRYSPNNGLSYQPNGLPHPTPPPPQHYRLDDMAIAHHYRDSYRHPSHRDLRDRNRPMGLHGTRQEEMID HRLTDREWAEEWKHLDHLLNCIMDMVEKTRRSLTVLRRCQEADREELNYWIRRYSDAEDLKKGGGSSSSH SRQQSPVNPDPVALDAHREFLHRPASGYVPEEIWKKAEEAVNEVKRQAMTELQKAVSEAERKAHDMITTE RAKMERTVAEAKRQAAEDALAVINQQEDSSESCWNCGRKASETCSGCNTARYCGSFCQHKDWEKHHHICG QTLQAQQQGDTPAVSSSVTPNSGAGSPMDTPPAATPRSTTPGTPSTIETTPR

Al cercar els trànscrits associats al gen ens vam adonar que les dues bases de dades (Ensembl i UCSC) ens aportaven informació diferent. Pel què fa a Ensembl vam trobar que tenia 5 trànscrits :
![]()
| TRÀNSCRIT 1: ENT00000300305 | |||||||
| Exons | Inici | Final | Inici Fase | Final Fase | Codificant | No Codificant | Híbrid |
| 1 | 35,343,009 | 35,343,511 | - | 1 | NO | NO | SÍ |
| 2 | 35,187,092 | 35,187,130 | 1 | 1 | SÍ | NO | NO |
| 3 | 35,181,010 | 35,181,263 | 1 | 0 | SÍ | NO | NO |
| 4 | 35,174,724 | 35,174,880 | 0 | 1 | SÍ | NO | NO |
| 5 | 35,153,641 | 35,153,745 | 1 | 1 | SÍ | NO | NO |
| 6 | 35,128,577 | 35,128,768 | 1 | 1 | SÍ | NO | NO |
| 7 | 35,093,468 | 35,093,629 | 1 | 1 | SÍ | NO | NO |
| 8 | 35,081,975 | 35,086,777 | 1 | - | NO | NO | SÍ |
| TRÀNSCRIT 2: ENST00000325074 | |||||||
| Exons | Inici | Final | Inici Fase | Final Fase | Codificant | No Codificant | Híbrid |
| 1 | 35,183,844 | 35,183,904 | 0 | 1 | SÍ | NO | NO |
| 2 | 35,181,010 | 35,181,263 | 1 | 0 | SÍ | NO | NO |
| 3 | 35,174,724 | 35,174,880 | 0 | 1 | SÍ | NO | NO |
| 4 | 35,153,641 | 35,153,745 | 1 | 1 | SÍ | NO | NO |
| 5 | 35,128,577 | 35,128,768 | 1 | 1 | SÍ | NO | NO |
| 6 | 35,093,468 | 35,093,629 | 1 | 1 | SÍ | NO | NO |
| 7 | 35,081,975 | 35,086,777 | 1 | - | NO | NO | SÍ |
| TRÀNSCRIT 3: ENST00000342083 | |||||||
| Exons | Inici | Final | Inici Fase | Final Fase | Codificant | No Codificant | Híbrid |
| 1 | 35,181,010 | 35,182,857 | - | 0 | NO | NO | SÍ |
| 2 | 35,174,724 | 35,174,880 | 0 | 1 | SÍ | NO | NO |
| 3 | 35,153,641 | 35,153,745 | 1 | 1 | SÍ | NO | NO |
| 4 | 35,150,580 | 35,150,614 | 1 | 0 | SÍ | NO | NO |
| TRÀNSCRIT 4: ENST00000344691 | |||||||
| Exons | Inici | Final | Inici Fase | Final Fase | Codificant | No Codificant | Híbrid |
| 1 | 35,181,010 | 35,182,857 | - | 0 | NO | NO | SÍ |
| 2 | 35,174,724 | 35,174,880 | 0 | 1 | SÍ | NO | NO |
| 3 | 35,153,641 | 35,153,745 | 1 | 1 | SÍ | NO | NO |
| 4 | 35,128,577 | 35,128,768 | 1 | 1 | SÍ | NO | NO |
| 5 | 35,093,468 | 35,093,629 | 1 | 1 | SÍ | NO | NO |
| 6 | 35,086,335 | 35,086,777 | 1 | 0 | SÍ | NO | NO |
| 7 | 35,086,318 | 35,086,330 | 0 | 1 | SÍ | NO | NO |
| 8 | 35,086,146 | 35,086,222 | 1 | 0 | SÍ | NO | NO |
| TRÀNSCRIT 5: ENST00000358356 | |||||||
| Exons | Inici | Final | Inici Fase | Final Fase | Codificant | No Codificant | Híbrid |
| 1 | 35,181,010 | 35,182,857 | - | 0 | NO | NO | SÍ |
| 2 | 35,174,724 | 35,174,880 | 0 | 1 | SÍ | NO | NO |
| 3 | 35,153,641 | 35,153,745 | 1 | 1 | SÍ | NO | NO |
| 4 | 35,128,577 | 35,128,768 | 0 | 1 | SÍ | NO | NO |
| 5 | 35,115,444 | 35,115,863 | 1 | - | NO | NO | SÍ |
| Trànscrit | 1 | 2 | 3 | 4 | 5 |
| Info peptídica | 480 aa | 468 aa | 188 aa | 472 aa | 250 aa |
D’aquests tant sols els trànscrits 3, 4 i 5 poden formar part de la proteïna de fusió, les altres formes presenten exons diferents que no tenen la seqüència aminoacídica necessària per donar lloc a la proteïna de fusió.
A la base de dades UCSC vam trobar informació sobre els trànscrits Refseq. Per la proteïna AML1 vam obtenir 2 trànscrits Refseq:
![]()
| TRÀNSCRIT 1: NM_001001890 | |||||||
| Exons | Inici | Final | Fase | Codificant | No Codificant | Híbrid | |
| 1 | 35181010 | 35182857 | 0 | NO | NO | SÍ | |
| 2 | 35174724 | 35174880 | 0 | SÍ | NO | NO | |
| 3 | 35153641 | 35153745 | 2 | SÍ | NO | NO | |
| 4 | 35128577 | 35128768 | 2 | SÍ | NO | NO | |
| 5 | 35093468 | 35093629 | 2 | SÍ | NO | NO | |
| 6 | 35081969 | 35086777 | 2 | NO | NO | SÍ | |
| TRÀNSCRIT 2: NM_001754 | |||||||
| Exons | Inici | Final | Fase | Codificant | No Codificant | Híbrid | |
| 1 | 35343009 | 35343465 | 0 | NO | NO | SÍ | |
| 2 | 35187092 | 35187130 | 2 | SÍ | NO | NO | |
| 3 | 35181010 | 35181263 | 2 | SÍ | NO | NO | |
| 4 | 35174724 | 35174880 | 0 | SÍ | NO | NO | |
| 5 | 35153641 | 35153745 | 2 | SÍ | NO | NO | |
| 6 | 35128577 | 35128768 | 2 | NO | NO | SÍ | |
| 7 | 35093468 | 35093629 | 2 | NO | NO | SÍ | |
| 8 | 35081969 | 35086777 | 2 | SÍ | NO | NO | |
| Trànscrit | 1 | 2 |
| Info peptídica | 453 aa | 480 aa |
Finalment, vam decidir donar més confiança a les dades de Refseq ja que vam considerar que es tracta d’una bona base de dades; ben curada i basada més en anàlisi funcional que en prediccions, com seria el cas de l’Ensembl. A partir d’aquest punt els resultats es basaran en els trànscrits RefSeq.
Aquests resultats els vam obtenir amb l’opció Table Browser de la base de dades UCSC. D’aquesta forma podíem obtenir mitjançant l’indicador de cada trànscrit la longitud de la regió codificant de cada exó i el frame corresponent. Amb aquestes dades podem concloure que els dos tràncrits formen dues isoformes generades per splicing alternatiu. La diferència consisteix en què el segon trànscrit comença a transcriure dos exons abans. Els exons 1 i 2 del segon trànscrit no es troben en el primer. El 3r exó del segon trànscrit i el 1r exó del primer trànscrit no coincideixen. A partir del 4t exó del segon trànscrit i el 2n exó del primer trànscrit hi ha una correspondència exacte en longitud dels exons i de fase.
![]()
Finalment vam buscar quines isoformes protèiques trobàvem per les dues proteïnes, els resultats de la base de dades uniprot van ser els que es mostraran a continuació. A la vegada, vam intentar averiguar quines d’aquestes isoformes pertanyien als trànscrits obtinguts fins al moment:
| ISOFORMES (UniProt) | Correspondéncia amb tránscrits Ensembl | Correspondéncia amb tránscrits RefSeq |
| Q01196 | - | TRÀNSCRIT 1:NM_001001890 |
| AML1-1A | TRÀNSCRIT 4:ENST00000344691 | - |
| AML1-1C | TRÀNSCRIT 5 : ENST00000358356 | - |
| AML1-1E | - | - |
| AML1-1FA | - | - |
| AML1-1FB | - | - |
| AML1-1FC | - | - |
| AML1-1G | - | TRÀNSCRIT 2: NM_001754 |
| AML1-1H | - | - |
| AML1-1I | TRÀNSCRIT 2: ENST00000325074 | - |
| AML1-1L | - | - |
Amb totes aquestes dades podem arribar a la conclusió que el trànscrit de AML1 necessari per la formació de la proteína de fusió AML1-MTG8 és el primer trànscrit de Refseq i la isoforma resultant d’aquest és la primera de la base de dades Uniprot. I per tant a l’hora de caracteritzar el promotor ho farem amb la seqüència obtinguda d’aquest trànscrit.
MTG8 ( RUNX1T1):El gen que codifica per aquesta proteïna es troba localitzat al cromosoma 8:

De nou, la informació obtinguda sobre els trànscrits en les dues bases de dades no coincidia. A la base de dades UCSC trobàvem 4 trànscrits mentre que amb l’Ensembl dos. Pel que fa a Ensembl :
![]()
| TRÀNSCRIT 1: ENST00000265814 | ||||||||||
| Exons | Inici | Final | Inici Fase | Final Fase | Codificant | No Codificant | Híbrid | |||
| 1 | 93,157,369 | 93,157,540 | - | 1 | NO | NO | SÍ | |||
| 2 | 93,098,630 | 93,098,767 | 1 | 1 | SÍ | NO | NO | |||
| 3 | 93,095,983 | 93,096,224 | 1 | 0 | SÍ | NO | NO | |||
| 4 | 93,092,406 | 93,092,495 | 0 | 0 | SÍ | NO | NO | |||
| 5 | 93,086,520 | 93,086,701 | 0 | 2 | SÍ | NO | NO | |||
| 6 | 93,073,043 | 93,073,293 | 2 | 1 | SÍ | NO | NO | |||
| 7 | 93,068,291 | 93,068,376 | 1 | 0 | SÍ | NO | NO | |||
| 8 | 93,067,528 | 93,067,729 | 0 | 1 | SÍ | NO | NO | |||
| 9 | 93,057,309 | 93,057,377 | 1 | 1 | SÍ | NO | NO | |||
| 10 | 93,052,062 | 93,052,252 | 1 | 0 | SÍ | NO | NO | |||
| 11 | 93,040,328 | 93,041,921 | 0 | - | NO | NO | SÍ | |||
| TRÀNSCRIT 2: ENST00000360348 | ||||||||||
| Exons | Inici | Final | Inici Fase | Final Fase | Codificant | No Codificant | Híbrid | |||
| 1 | 93,176,432 | 93,176,619 | - | - | NO | SÍ | NO | |||
| 2 | 93,098,630 | 93,098,767 | - | 1 | NO | NO | SÍ | |||
| 3 | 93,095,983 | 93,096,224 | 1 | 0 | SÍ | NO | NO | |||
| 4 | 93,092,406 | 93,092,495 | 0 | 0 | SÍ | NO | NO | |||
| 5 | 93,086,520 | 93,086,701 | 0 | 2 | SÍ | NO | NO | |||
| 6 | 93,073,043 | 93,073,293 | 2 | 1 | SÍ | NO | NO | |||
| 7 | 93,068,291 | 93,068,376 | 1 | 0 | SÍ | NO | NO | |||
| 8 | 93,067,528 | 93,067,729 | 0 | 1 | SÍ | NO | NO | |||
| 9 | 93,057,309 | 93,057,377 | 1 | 1 | SÍ | NO | NO | |||
| 10 | 93,052,062 | 93,052,252 | 1 | 0 | SÍ | NO | NO | |||
| 11 | 93,040,328 | 93,041,921 | 0 | - | NO | NO | SÍ | |||
| Trànscrit | 1 | 2 |
| Info Peptídica | 604 aa | 567 aa |
Aquests dos trànscrits coincideixen exactament ( mateixa seqüència, mateixa regió codificant, i la proteïna produïda conté mateix nombre i seqüència d’aminoàcids) amb dos dels quatre trànscrits RefSeq trobats a UCSC. Al comentar per tant, els trànscrits RefSeq se sobrentendrà que també s’estan comentant aquests.
Els resultats obtinguts al UCSC són:
![]()
| TRÀNSCRIT 1: NM_175636 | |||||||||
| Exons | Inici | Final | Fase | Codificant | No Codificant | Híbrid | |||
| 1 | 93,098,630 | 93,099,084 | 0 | NO | NO | SÍ | |||
| 2 | 93,095,983 | 93,096,224 | 2 | SÍ | NO | NO | |||
| 3 | 93,092,406 | 93,092,495 | 0 | SÍ | NO | NO | |||
| 4 | 93,086,520 | 93,086,701 | 0 | SÍ | NO | NO | |||
| 5 | 93,073,043 | 93,073,293 | 1 | SÍ | NO | NO | |||
| 6 | 93,068,291 | 93,068,376 | 2 | SÍ | NO | NO | |||
| 7 | 93,067,528 | 93,067,729 | 0 | SÍ | NO | NO | |||
| 8 | 93,057,309 | 93,057,377 | 2 | SÍ | NO | NO | |||
| 9 | 93,052,062 | 93,052,252 | 2 | SÍ | NO | NO | |||
| 10 | 93,040,328 | 93,041,221 | 0 | NO | NO | SÍ | |||
| TRÀNSCRIT 2: NM_004349 | ||||||||||
| Exons | Inici | Final | Fase | Codificant | No Codificant | Híbrid | ||||
| 1 | 93,143,950 | 93,144,367 | 0 | NO | NO | SÍ | ||||
| 2 | 93,098,630 | 93,098,767 | 2 | SÍ | NO | NO | ||||
| 3 | 93,095,983 | 93,096,224 | 2 | SÍ | NO | NO | ||||
| 4 | 93,092,406 | 93,092,495 | 0 | SÍ | NO | NO | ||||
| 5 | 93,086,520 | 93,086,701 | 0 | SÍ | NO | NO | ||||
| 6 | 93,073,043 | 93,073,293 | 1 | SÍ | NO | NO | ||||
| 7 | 93,068,291 | 93,068,376 | 2 | SÍ | NO | NO | ||||
| 8 | 93,067,528 | 93,067,729 | 0 | SÍ | NO | NO | ||||
| 9 | 93,057,309 | 93,057,377 | 2 | SÍ | NO | NO | ||||
| 10 | 93,052,062 | 93,052,252 | 2 | SÍ | NO | NO | ||||
| 11 | 93,040,328 | 93,041,921 | 0 | NO | NO | SÍ | ||||
| TRÀNSCRIT 3: NM_175634 | ||||||||||
| Exons | Inici | Final | Fase | Codificant | No Codificant | Híbrid | ||||
| 1 | 93,157,369 | 93,157,540 | 0 | NO | NO | SÍ | ||||
| 2 | 93,098,630 | 93,098,767 | 2 | SÍ | NO | NO | ||||
| 3 | 93,095,983 | 93,096,224 | 2 | SÍ | NO | NO | ||||
| 4 | 93,092,406 | 93,092,495 | 0 | SÍ | NO | NO | ||||
| 5 | 93,086,520 | 93,086,701 | 0 | SÍ | NO | NO | ||||
| 6 | 93,073,043 | 93,073,293 | 1 | SÍ | NO | NO | ||||
| 7 | 93,068,291 | 93,068,376 | 2 | SÍ | NO | NO | ||||
| 8 | 93,067,528 | 93,067,729 | 0 | SÍ | NO | NO | ||||
| 9 | 93,057,309 | 93,057,377 | 2 | SÍ | NO | NO | ||||
| 10 | 93,052,062 | 93,052,252 | 2 | SÍ | NO | NO | ||||
| 11 | 93,040,328 | 93,041,921 | 0 | NO | NO | SÍ | ||||
| TRÀNSCRIT 4: NM_175635 | ||||||||||
| Exons | Inici | Final | Fase | Codificant | No Codificant | Híbrid | ||||
| 1 | 93,176,432 | 93,176,619 | - | NO | SÍ | NO | ||||
| 2 | 93,098,630 | 93,098,767 | 0 | SÍ | NO | NO | ||||
| 3 | 93,095,983 | 93,096,224 | 2 | SÍ | NO | NO | ||||
| 4 | 93,092,406 | 93,092,495 | 0 | SÍ | NO | NO | ||||
| 5 | 93,086,520 | 93,086,701 | 0 | SÍ | NO | NO | ||||
| 6 | 93,073,043 | 93,073,293 | 1 | SÍ | NO | NO | ||||
| 7 | 93,068,291 | 93,068,376 | 2 | SÍ | NO | NO | ||||
| 8 | 93,067,528 | 93,067,729 | 0 | SÍ | NO | NO | ||||
| 9 | 93,057,309 | 93,057,377 | 2 | SÍ | NO | NO | ||||
| 10 | 93,052,062 | 93,052,252 | 2 | SÍ | NO | NO | ||||
| 11 | 93,040,328 | 93,041,921 | 0 | NO | NO | SÍ | ||||
| Trànscrit | 1 | 2 | 3 | 4 |
| Info Peptídica | 567 aa | 577 aa | 604 aa | 567 aa |
Els trànscrits 3 i 4 de RefSeq corresponen als trànscrits 1 i 2 de Ensembl respectivament.
El trànscrit 1 és el que difereix més de la resta: primerament presenta un exó menys i la longitud dels exons no coincideix amb cap de les longituds dels exons dels altres tres trànscrits. Els altres tres trànscrits s’assemblen més entre ells, ja que presenten el mateix número d’exons amb les mateixes coordeenades amb l’excepció del primer exó que és diferent en els tres casos. Però tots tres presenten diferències en el primer exó : són tots diferents en longitud i part codificant (CDS). Concretament, en l’últim trànscrit, tot el primer exó és no codificant. Finalment, observem que aquests trànscrits donen lloc a seqüències aminoacídiques diferents.
Amb aquests resultats podem concloure que aquests tres trànscrits donen lloc a diferents isoformes produïdes per splicing alternatiu que afecta en tots els casos a la regió codificant i per tant donen lloc a diferents pèptids.
![]()
Tant sols dos dels quatre trànscrits poden formar part de la proteïna de fusió, el 2 i el 3, ja que la resta no presenten tots el aminioàcids presents a la proteïna de fusió.
Posteriorment, vam buscar les isoformes a través d’Uniprot. El resultat van ser dues isoformes MTG8-A I MTG8-B que coincidien exactament amb la seqüència peptídica predita a paritir dels trànscrit Refseq 2 i 3 respectivament.
| ISOFORMES (UniProt) | Correspondéncia amb tránscrits |
| MTG8-A | NM_004349 |
| MTG8-B | NM_175634 |
Homogia de AML1 amb altres espècies per ordre decreixent de percentatge d’identitat:
| IMATGE | ESPÈCIE | GEN | TIPUS D’HOMOLOGIA | QUERY % ID |
 |
Pan troglodytes | ENSPTRG00000013883 | 1-to-1 | 100 |
 |
Macaca mulatta | ENSMMUUG00000001649 | 1-to-1 | 99 |
 |
Bos taurus | ENSBTAG0000004742 | 1-to-1 | 98 |
 |
Oryctolagus cuniculus | ENSOCUG00000013731 | 1-to-1 | 93 |
 |
Canis familiaris | ENSCAFG00000009596 | 1-to-1 | 92 |
 |
Mus musculus | ENSMUSG00000022952 | 1-to-1 | 89 |
 |
Rattus norvegicus | ENSRNOG00000001704 | 1-to-1 | 88 |
 |
Echinops telfairi | ENSETEG00000011313 | 1-to-1 | 86 |
 |
Monodelphis domestica | ENSMODG00000021051 | 1-to-1 | 85 |
 |
Xenopus tropicalis | ENSXETG00000014140 | 1-to-1 | 82 |
 |
Tupaia belangeri | ENSTBEG00000000192 | 1-to-1 | 74 |
 |
Gallus gallus | ENSGALG00000016022 | 1-to-1 | 66 |
 |
Felis catus | ENSFCAG00000006761 | 1-to-1 | 65 |
 |
Cavia porcellus | ENSCPOG00000002684 | 1-to-1 | 62 |
 |
Takifugu rubripes | SINFRUG00000149207 | 1-to-1 | 57 |
 |
Orycias latipes | ENSORLG00000020699 | 1-to-1 | 55 |
 |
Gasterostus aculeatus | ENSGACG00000015276 | 1-to-1 | 49 |
 |
Loxodonta africana | ENSLAFG00000004290 | 1-to-1 | 47 |
 |
Dasypus novemcintus | ENSDNOG00000015041 | 1-to-1 | 46 |
 |
Tetraodon nigroviridis | GSTENG00034595001 | 1-to-1 | 34 |
 |
Drosophila melanogaster | CDG1689 | many to many | 30 |
|
Drosophila melanogaster | CG1849 | many to many | 27 |
 |
Aedes aegypti | AAEL006167 | many to many | 26 |
 |
Ciona intestinalis | ENSCING00000002253 | 1-to-many | 24 |
|
Drosophila melanogaster | CG1379 | many to many | 24 |
 |
Ciona savignyi | ENSCSAVG00000004072 | 1-to-many | 22 |
|
Drosophila melanogaster | CG15455 | many to many | 22 |
|
Aedes aegypti | AAEL006160 | many to many | 21 |
 |
Anopheles gambiae | ENSANGG00000011627 | many to many | 20 |
|
Aedes aegypti | AAEL007040 | many to many | 19 |
|
Anopheles gambiae | ENSANGG00000019555 | many to many | 19 |
 |
Caernorhabditis elegans | B0414.2 | 1-to-many | 18 |
|
Aedes aegypti | AAEL007036 | many to many | 16 |
 |
Ornithorhynchus anatinus | ENSOANG00000011162 | 1-to-1 | 12 |
Els resultats obtinguts mostren que tant sols troben alta homologia d’aquesta proteïna en altres espècies quan aquestes són molt properes filogenèticament. A mesura que ens allunyem en l’escala filogenètica els percentatges d’identitat disminueixen.
Homologia de MTG8 amb altres espècies per ordre decreixent de percentatge d’identitat:
| IMATGE | ESPÈCIE | GEN | TIPUS D’HOMOLOGIA | QUERY % ID |
|
Pan troglodytes | ENSPTRG00000013883 | 1-to-1 | 100 |
|
Macaca mulatta | ENSMMUUG000000023115 | 1-to-1 | 99 |
|
Tupaia belangeri | ENSTBEG00000010312 | 1-to-1 | 98 |
|
Gallus gallus | ENSGALG00000015926 | 1-to-1 | 97 |
|
Bos taurus | ENSBTAG00000017339 | 1-to-1 | 94 |
|
Oryctolagus cuniculus | ENSOCUG00000013731 | 1-to-1 | 93 |
|
Mus musculus | ENSMUSG0000006586 | 1-to-1 | 94 |
|
Rattus norvegicus | ENSRNOG00000005673 | 1-to-1 | 94 |
|
Canis familiaris | ENSCAFG00000009078 | 1-to-1 | 92 |
|
Monodelphis domestica | ENSMODG0000007500 | 1-to-1 | 92 |
|
Ornithorhynchus anatinus | ENSOANG00000001913 | 1-to-1 | 92 |
|
Xenopus tropicalis | ENSXETG00000014592 | 1-to-1 | 92 |
 |
Danio rerio | ENSDARG00000003680 | 1-to-1 | 87 |
|
Felis catus | ENSFCAG00000005350 | 1-to-1 | 85 |
|
Gasterostus aculeatus | ENSGACG00000005059 | 1-to-1 | 84 |
|
Loxodonta africana | ENSLAFG00000005779 | 1-to-1 | 84 |
|
Orycias latipes | ENSORLG00000012311 | 1-to-1 | 80 |
|
Takifugu rubripes | SINFRUG00000133596 | 1-to-1 | 80 |
|
Tetraodon nigroviridis | GSTENG00017458001 | 1-to-1 | 80 |
|
Echinops telfairi | ENSETEG00000014837 | 1-to-1 | 75 |
|
Dasypus novemcintus | ENSDNOG00000008847 | 1-to-1 | 51 |
|
Aedes aegypti | AAEL003615 | many to many | 26 |
|
Aedes aegypti | AAEL014203 | many to many | 26 |
|
Anopheles gambiae | ENSANGG00000015731 | 1 to many | 26 |
|
Drosophila melanogaster | CDG3385 | 1 to many | 24 |
Els resultats obtinguts mostren una identitat molt alta entre aquesta proteïnes i les seves homòlogues en altres espècies. El percentatge d’identitat és molt alt fins i tot en espècies bastant separades en l’escala filogenètica. No és fins que ens allunyem molt que la identitat disminueix considerablement, es tracta per tant d’una proteïna molt conservada.
Els resultats obtinguts per les dues proteïnes independentment amb l’ensembl coincideixen amb els resultats de que podem observar realitzant un tblastn amb la seqüència de la proteïna de fusió contra tots els genomes i posteriorment mirar els resultats de taxonomy report. Veiem que les espècies que presenten regions homòlogues a la proteïna de fusió són les mateixes que en l’ensembl es mostren com a ortòlogues de cada proteïna per separat en diferents espècies.
Per tal de caracteritzar l’expressió del gen vam buscar informació al gene Atlas 2 a través de la base de dades UCSC. Aquest track el podem trobar al Genome Browser i ens mostra els resultats d’un anàlisi d’expressió que consisteix en dos rèpliques de 79 teixits humans que s’analitzen a través de microarrays. Com tot els resultats basats en microarrays, el color vermell indica sobreexpressió mentre que el verd indica expressió inferior a la normal (mirar llegenda):
Els resultats obtinguts van ser:

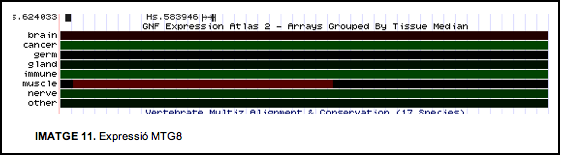
| TEIXIT | AML1 | MTG8 | |
| Cervell |  |
abscent | present |
| Càncer |  |
present | absent |
| Germinals |  |
abscent | abscent |
| Glàndules |  |
abscent | abscent |
| Sist.immune |  |
present | abscent |
| Múscul |  |
abscent | present |
| Sist.nerviós |  |
abscent | abscent |
No hem obtingut informació de l’expressió sobre la proteïna de fusió però si de les dues proteïnes AML1 i MTG8 per separat:
Els següents resultats mostren una sopreexpressió de AML1 en teixit cancerós i en sistema immunitari però no s’observa expressió en els altres teixits. Pel que fa a MTG8 tant sols observem sobreexpressió en múscul i en cervell.
Aquests resultats coincideixen amb els que esperàvem a partir de la informació proporcionada per l’article : The t(8;21) translocation in acute myeloid leucemia results in production of an AML1-MTG8 fusion transcript. En aquest article confirmaven l’expressió de AML1 en cèl.lules hematopoiètiques i la seva funció com a factor de transcripció essencial per la diferenciació i creixement de les diferents línies cel.lulars hematopoiètiques. En canvi, l’expressió de MTG8 va ser detectada en alts nivells en el cervell i en nivells més baixos en múscul. Però sorprenentment no es va detectar en òrgans hematopoiètics. Segons aquest article, la proteïna de fusió que resulta de la translocació t(8;21) s’expressa en cèl.lules hematopoiètiques igual que AML1, per tant la porció de MTG8 que trobem a la proteïna de fusió si que s’expressa en cèl.lules hematopoiètiques. Finalment amb aquests resultats i el fet que aquesta proteïna de fusió provoqui el desenvolupament de leucèmia mieloide els va portar a hipotetitzar que aquesta translocació provoca una mutació amb efecte dominant negatiu sobre AML1, i per tant aquesta perd el seu control en diferenciació i creixement sobre cèl.lules hematopoiètiques.
L’única discordància que trobem en els resultats de Gene Atlas 2 és que no troba expressió de MTG8 en càncer. Creiem que aquest fet es pot deure a que tan sols part de la proteïna de fusió està formada per MTG8 i per tant aquesta pot passar desepercebuda en un analisis d’expressió amb microarrays, és molt improbable que la sonda hibridi exactament amb aquest petit fragment.
Per tal de caracteritzar la regió promotora primerament hem d’obtenir la regió promotora de tots els trànscrits que puguin formar part de la proteïna de fusió. Considerarem regió promotora 1000pb upstream del lloc de començament de la transcripció i 100pb downstream. Aquesta regió l’hem extret de la base de dades UCSC a través de l’opció del table browser. Les seqüències obtingudes estan en format fasta i hi podeu accedir amb els següents links:
AML1.fa
MTG8A.fa
MTG8B.fa
Un cop obtinguda la seqüència promotora intentarem predir quins possibles factors de transcripció s’uneixen a la nostra seqüència. Per aconseguir-ho realitzarem aquestes prediccions de dues formes diferents: La primera a través d’un programa disponible a la xarxa anomenat PROMO i la segona a partir d’un programa elaborat per nosaltres mateixes en Perl. Un cop obtinguem ambdues prediccions intentarem comparar-ne els resultats.
Teòricament aquests resultats són comparables ja que la idea en la que es basen per trobar aquestes prediccions és similar: els dos parteixen de les mateixes matrius d’ocurrència ( tot i que el nostre programa disposa només de 13 d’aquestes matrius). A partir d’aquestes matrius s’elaboren matrius de pesos a partir de les quals podem estimar la puntuació dels diferents motius que es puguin trobar en la regió promotora. En els dos casos obtenim valors de referència per comparar els resultats obtinguts amb la nostra seqüència promotora amb resultats que podriem obtenir amb seqüències generades a l’atzar.
Per obtenir resultats amb el programa PROMO hem seleccionat que només busques factors humans i només motius d’unió humans. Posteriorment hem introduït la seqüència promotora on voliem identificar llocs d’unió de factors de transcripció i vam limitar la cerca per aquells motius que presentessin un índex de dissimilaritat igual o inferior al 15%. De tots els resultats obtinguts ens vam quedar amb aquells que presentessin un RE equally (a l’atzar en una seqüència que presenti una composició de núcleotids equiprobable quants cops trobariem aquest motiu en concret) menor a 0,09. Vam considerar que era suficientment baix com per discriminar aquelles cerques que no són significatives, és a dir, que es podien donar perfectament per atzar. Després de tots aquests filtres els resultats obtinguts van ser els següents:
| RESULTATS PROMO AML1 | ||||||
| FACTOR DE TRANSCRIPCIÓ | POSICIÓ INCIAL | POSICIÓ INCIAL | SEQÜÈNCIA | RE EQUALLY | RE QUERY | |
| WT1 [T00899] | 828 | 836 | GCGGGGGCG | 0,0042 | 0,13526 | |
| Sp1 [T00759] | 48 | 57 | GGGGCGGGGA | 0,0042 | 0,13841 | |
| Sp1 [T00759] | 465 | 474 | CCCCCGCCCT | 0,00734 | 0,1902 | |
| Sp1 [T00759] | 729 | 738 | CGGGCGGGGC | 0,00734 | 0,1902 | |
| AhR:Arnt [T05394] | 724 | 733 | GCACGCGGGC | 0,00944 | 0,12448 | |
| NF-AT1 [T01948] | 978 | 987 | TTCATTTCCA | 0,01049 | 0,00198 | |
| EBF [T05427] | 469 | 479 | CGCCCTGGAAG | 0,01049 | 0,07001 | |
| EBF [T05427] | 489 | 499 | GGCCCTGGGCG | 0,01364 | 0,07945 | |
| ETF [T00270] | 728 | 738 | GCGGGCGGGGC | 0,01574 | 0,43859 | |
| ETF [T00270] | 825 | 835 | GCGGCGGGGGC | 0,01574 | 0,43859 | |
| E2F-1 [T01542] | 292 | 299 | GCGGTAAA | 0,01678 | 0,00632 | |
| GCF [T00320] | 503 | 511 | GCGCAGGAT | 0,01678 | 0,04782 | |
| GCF [T00320] | 1070 | 1078 | GCCCTGCGC | 0,01678 | 0,13062 | |
| Sp1 [T00759] | 789 | 798 | TCCCCGCCCG | 0,01783 | 0,30133 | |
| NF-kappaB1 [T00593] | 89 | 99 | GGGGAGACGCG | 0,0181 | 0,0645 | |
| NF-kappaB1 [T00593] | 432 | 442 | AGTGGCTCCCC | 0,0181 | 0,0645 | |
| Sp1 [T00759] | 911 | 920 | CGGCCGCCCC | 0,01888 | 0,31353 | |
| Sp1 [T00759] | 1017 | 1026 | CGGGCGGGAC | 0,01993 | 0,28742 | |
| STAT5A [T04683] | 308 | 320 | ATTACAGAAACCG | 0,02095 | 0,00143 | |
| NF-AT2 [T01945] | 218 | 227 | GGAAACTCTT | 0,02098 | 0,00185 | |
| NF-AT1 [T00550] | 650 | 658 | TCTTTTTCC | 0,02098 | 0,00535 | |
| CTF [T00174] | 840 | 851 | GGGCCAATTCCA | 0,02124 | 0,01069 | |
| CTF [T00174] | 898 | 909 | TGTGATTGGCCG | 0,0236 | 0,01952 | |
| EBF [T05427] | 1069 | 1079 | GGCCCTGCGCC | 0,02623 | 0,1144 | |
| AhR:Arnt [T05394] | 349 | 358 | GCACGCGCGG | 0,02832 | 0,21419 | |
| PPAR-alpha:RXR-alpha [T05221] | 25 | 35 | ACCTGGGGCCG | 0,02832 | 0,16829 | |
| PPAR-alpha:RXR-alpha [T05221] | 510 | 520 | ATCTGGGGCCG | 0,02832 | 0,16829 | |
| NF-AT1 [T00550] | 218 | 226 | GGAAACTCT | 0,02937 | 0,00628 | |
| NF-AT2 [T01945] | 202 | 211 | GGGTCTTTCC | 0,03777 | 0,00738 | |
| NF-AT2 [T01945] | 649 | 658 | TTCTTTTTCC | 0,03777 | 0,00738 | |
| NF-AT2 [T01945] | 1087 | 1096 | ACTTCTTTCC | 0,03777 | 0,00738 | |
| NF-AT1 [T00550] | 1088 | 1096 | CTTCTTTCC | 0,03777 | 0,00852 | |
| RAR-beta:RXR-alpha [T05420] | 438 | 449 | TCCCCCGGGCCC | 0,03836 | 0,13369 | |
| ETF [T00270] | 60 | 70 | GGAGCGGGGGC | 0,03934 | 0,79684 | |
| ETF [T00270] | 446 | 456 | GCCCCGCGGCC | 0,03934 | 0,79684 | |
| ETF [T00270] | 580 | 590 | GCTCGCGGGGC | 0,03934 | 0,79684 | |
| ETF [T00270] | 1031 | 1041 | GCCCCGCGGCC | 0,03934 | 0,79684 | |
| c-Ets-2 [T00113] | 947 | 955 | TTCCTCCGG | 0,04196 | 0,03749 | |
| NF-AT1 [T01948] | 650 | 659 | TCTTTTTCCA | 0,04196 | 0,00692 | |
| EBF [T05427] | 873 | 883 | CGCCCTGGCTG | 0,04406 | 0,15258 | |
| EBF [T05427] | 1047 | 1057 | CAGCCAGGGCA | 0,04406 | 0,15258 | |
| PPAR-alpha:RXR-alpha [T05221] | 1041 | 1051 | CGGACCCAGCC | 0,04721 | 0,29215 | |
| Sp1 [T00759] | 494 | 503 | TGGGCGGCCG | 0,0493 | 0,41348 | |
| GCF [T00320] | 131 | 139 | TGCCGGCGC | 0,05035 | 0,84673 | |
| GCF [T00320] | 611 | 619 | GCGCCGGCC | 0,05035 | 0,84673 | |
| GCF [T00320] | 836 | 844 | GCGCGGGCC | 0,05035 | 0,84673 | |
| GATA-2 [T00308] | 882 | 890 | TGATACCGG | 0,05035 | 0,02422 | |
| NF-AT2 [T01945] | 977 | 986 | GTTCATTTCC | 0,05875 | 0,01279 | |
| NF-AT2 [T01945] | 173 | 182 | TCAACTTTCC | 0,06294 | 0,01491 | |
| c-Ets-1 [T00112] | 216 | 222 | TAGGAAA | 0,06714 | 0,00633 | |
| ENKTF-1 [T00255] | 1076 | 1083 | CGCCGCCA | 0,06714 | 0,35848 | |
| NF-1 [T00539] | 839 | 846 | CGGGCCAA | 0,06714 | 0,12852 | |
| HIF-1 [T01609] | 970 | 978 | AAAGCACGT | 0,07133 | 0,05854 | |
| STAT1beta [T01573] | 885 | 894 | TACCGGAAAG | 0,08183 | 0,0313 | |
| ETF [T00270] | 23 | 33 | GCACCTGGGGC | 0,08261 | 1,15588 | |
| ETF [T00270] | 633 | 643 | GCCGGCGGGGC | 0,08261 | 1,15588 | |
| ETF [T00270] | 735 | 745 | GGGCCCCGGGC | 0,08261 | 1,15588 | |
| ETF [T00270] | 760 | 770 | GGATGCGGGGC | 0,08261 | 1,15588 | |
| E2F-1 [T01542] | 1020 | 1027 | GCGGGACG | 0,08392 | 0,33331 | |
| USF2 [T00878] | 20 | 29 | TCCGCACCTG | 0,08497 | 0,107 | |
| STAT1beta [T01573] | 981 | 990 | ATTTCCAGGC | 0,08497 | 0,02097 | |
| AhR:Arnt [T05394] | 696 | 705 | GCCTGCGTGT | 0,08497 | 0,21318 | |
| AhR:Arnt [T05394] | 1058 | 1067 | CCACGCTGCC | 0,08497 | 0,21318 | |
| c-Ets-2 [T00113] | 375 | 383 | TGCAAGGAA | 0,08812 | 0,01036 | |
| RESULTATS PROMO MTG8A | ||||||
| FACTOR DE TRANSCRIPCIÓ | POSICIÓ INCIAL | POSICIÓ INCIAL | SEQÜÈNCIA | RE EQUALLY | RE QUERY | |
| RBP-Jkappa | 460 | 471 | TTCATGGGAAGG | 0 | 0 | |
| HOXD9 [T01424] | 663 | 672 | AATAAAAGTG | 0 | 0,01 | |
| HOXD10 [T01425] | 663 | 672 | AATAAAAGTG | 0 | 0,01 | |
| POU2F2 (Oct-2,1) [T00646] | 857 | 867 | TTTTTAATACA | 0 | 0,01 | |
| NF-AT2 [T01945] | 177 | 186 | GGAAAGATTT | 0 | 0,01 | |
| HOXD9 [T01424] | 908 | 917 | GCCTTTTATT | 0,01 | 0,01 | |
| HOXD10 [T01425] | 908 | 917 | GCCTTTTATT | 0,01 | 0,01 | |
| HNF-4alpha [T03828] | 779 | 791 | CAAAGTCTTATAA | 0,01 | 0,01 | |
| POU2F2 (Oct-2,1) [T00646] | 310 | 320 | TGTTTTACAAA | 0,01 | 0,03 | |
| AhR:Arnt [T05394] | 279 | 288 | GCAGGCGTGT | 0,01 | 0 | |
| SRF [T00764] | 906 | 918 | AAGCCTTTTATTG | 0,01 | 0,01 | |
| NF-AT1 [T00550] | 177 | 185 | GGAAAGATT | 0,01 | 0,02 | |
| HNF-4alpha [T03828] | 739 | 751 | TTCTGATACTTTG | 0,01 | 0,02 | |
| EBF [T05427] | 634 | 644 | ATCCCAGGGGG | 0,01 | 0 | |
| RBP-Jkappa [T01616] | 867 | 878 | AGTTCCCAATTA | 0,02 | 0,02 | |
| SRY [T00997] | 373 | 381 | ATAACAAAG | 0,02 | 0,02 | |
| TBP [T00794] | 391 | 400 | TTTATATATC | 0,02 | 0,05 | |
| HNF-1C [T01951] | 456 | 464 | GTTATTCAT | 0,03 | 0,05 | |
| TCF-4 [T02918] | 834 | 843 | GCTTTGAGTT | 0,03 | 0,02 | |
| NF-AT1 [T01948] | 111 | 120 | TGGAAAGGTA | 0,03 | 0,04 | |
| c-Ets-2 [T00113] | 727 | 735 | CAAAAGGAA | 0,03 | 0,06 | |
| SRY [T00997] | 775 | 783 | TATACAAAG | 0,03 | 0,05 | |
| Elk-1 [T00250] | 421 | 429 | ATAGGGAAG | 0,03 | 0,05 | |
| HOXD9 [T01424] | 452 | 461 | ATGTGTTATT | 0,04 | 0,13 | |
| HOXD10 [T01425] | 452 | 461 | ATGTGTTATT | 0,04 | 0,13 | |
| EBF [T05427] | 63 | 73 | GACCCTGAGTG | 0,04 | 0,02 | |
| NF-AT2 [T01945] | 593 | 602 | GGAAAGTAAG | 0,04 | 0,06 | |
| MEF-2A [T01005] | 341 | 351 | AGAAGAAAATA | 0,04 | 0,1 | |
| MEF-2A [T01005] | 656 | 666 | CGAGTAAAATA | 0,04 | 0,1 | |
| IRF-1 [T00423] | 229 | 237 | TTTCCTTCT | 0,04 | 0,07 | |
| NF-AT2 [T01945] | 112 | 121 | GGAAAGGTAA | 0,04 | 0,05 | |
| NF-AT1 [T01948] | 811 | 820 | GGGATTTCCA | 0,04 | 0,06 | |
| T3R-beta1 [T00851] | 994 | 1002 | TGGTGGTGA | 0,04 | 0,04 | |
| PEA3 [T00685] | 755 | 763 | AGGATGATA | 0,05 | 0,07 | |
| GATA-2 [T00308] | 361 | 369 | AGATAAAGC | 0,05 | 0,06 | |
| HNF-1C [T01951] | 971 | 979 | GTTAACCTT | 0,06 | 0,09 | |
| AR [T00040] | 512 | 520 | GGACATGAT | 0,06 | 0,04 | |
| NF-AT1 [T00550] | 811 | 819 | GGGATTTCC | 0,06 | 0,06 | |
| NF-AT2 [T01945] | 224 | 233 | AGTATTTTCC | 0,06 | 0,07 | |
| HNF-1B [T01950] | 455 | 463 | TGTTATTCA | 0,06 | 0,11 | |
| MEF-2A [T01005] | 699 | 709 | TATTTTACACA | 0,07 | 0,15 | |
| RXR-alpha [T01345] | 623 | 629 | TCAACCC | 0,07 | 0,07 | |
| PR B [T00696] | 691 | 697 | AAGTGTT | 0,07 | 0,11 | |
| PR A [T01661] | 691 | 697 | AAGTGTT | 0,07 | 0,11 | |
| c-Myb [T00137] | 763 | 770 | AAACTGGC | 0,07 | 0,06 | |
| c-Ets-1 [T00112] | 175 | 181 | TAGGAAA | 0,07 | 0,11 | |
| SRY [T00997] | 313 | 321 | TTTACAAAG | 0,07 | 0,09 | |
| PXR-1:RXR-alpha [T05671] | 437 | 444 | TGAACCTG | 0,07 | 0,04 | |
| PXR-1:RXR-alpha [T05671] | 519 | 526 | ATTGTTCA | 0,07 | 0,1 | |
| LEF-1 [T02905] | 835 | 842 | CTTTGAGT | 0,07 | 0,1 | |
| TBP [T00794] | 783 | 792 | GTCTTATAAA | 0,07 | 0,19 | |
| Elk-1 [T00250] | 462 | 470 | CATGGGAAG | 0,07 | 0,07 | |
| IRF-1 [T00423] | 108 | 116 | CGATGGAAA | 0,07 | 0,08 | |
| IRF-1 [T00423] | 589 | 597 | TAGAGGAAA | 0,07 | 0,09 | |
| IRF-1 [T00423] | 815 | 823 | TTTCCAGTT | 0,07 | 0,1 | |
| NF-AT1 [T00550] | 225 | 233 | GTATTTTCC | 0,07 | 0,07 | |
| RAR-beta [T00721] | 621 | 630 | TATCAACCCG | 0,08 | 0,07 | |
| RAR-beta [T00721] | 968 | 977 | AGGGTTAACC | 0,08 | 0,07 | |
| PPAR-alpha:RXR-alpha [T05221] | 764 | 774 | AACTGGCACAA | 0,08 | 0,05 | |
| RESULTATS PROMO MTG8B | ||||||
| FACTOR DE TRANSCRIPCIÓ | POSICIÓ INCIAL | POSICIÓ INCIAL | SEQÜÈNCIA | RE EQUALLY | RE QUERY | |
| ELF-1 [T01113] | 67 | 79 | TTCTAGGAAGTAA | 0 | 0 | |
| POU2F2 (Oct-2,1) [T00646] | 484 | 494 | TGTTTTAAACT | 0 | 0,04 | |
| IRF-1 [T00423] | 976 | 984 | TTTCCCTTT | 0 | 0,01 | |
| PPAR-alpha:RXR-alpha [T05221] | 1033 | 1043 | CTGTCCCAGTC | 0,01 | 0 | |
| c-Ets-2 [T00113] | 343 | 351 | TAGCAGGAA | 0,01 | 0,01 | |
| NF-AT2 [T01945] | 201 | 210 | TTATATTTCC | 0,01 | 0,02 | |
| MEF-2A [T01005] | 86 | 96 | CTCAAAAAATA | 0,01 | 0,07 | |
| MEF-2A [T01005] | 661 | 671 | TATTTTTTTGA | 0,01 | 0,07 | |
| HOXD9 [T01424] | 198 | 207 | CCCTTATATT | 0,01 | 0,03 | |
| HOXD9 [T01424] | 361 | 370 | AATTTATATT | 0,01 | 0,22 | |
| HOXD10 [T01425] | 198 | 207 | CCCTTATATT | 0,01 | 0,03 | |
| HOXD10 [T01425] | 361 | 370 | AATTTATATT | 0,01 | 0,22 | |
| MEF-2A [T01005] | 657 | 667 | TATTTATTTTT | 0,01 | 0,16 | |
| PU,1 [T02068] | 67 | 79 | TTCTAGGAAGTAA | 0,02 | 0,01 | |
| HOXD9 [T01424] | 28 | 37 | TTGTTTTATT | 0,02 | 0,29 | |
| HOXD10 [T01425] | 28 | 37 | TTGTTTTATT | 0,02 | 0,29 | |
| SRF [T00764] | 169 | 181 | CTACCTTATATGT | 0,02 | 0,02 | |
| NF-AT1 [T01948] | 784 | 793 | TGGAAAATTA | 0,02 | 0,04 | |
| MEF-2A [T01005] | 299 | 309 | GACAATAAATA | 0,02 | 0,17 | |
| MEF-2A [T01005] | 426 | 436 | TATTTGTTTCA | 0,02 | 0,17 | |
| NF-AT2 [T01945] | 785 | 794 | GGAAAATTAA | 0,03 | 0,03 | |
| HNF-1B [T01950] | 444 | 452 | TTTTTAACT | 0,03 | 0,11 | |
| ELF-1 [T01113] | 203 | 215 | ATATTTCCTAGTT | 0,03 | 0,02 | |
| TCF-4 [T02918] | 767 | 776 | GCTTTGAGTC | 0,03 | 0,01 | |
| STAT1beta [T01573] | 205 | 214 | ATTTCCTAGT | 0,03 | 0,03 | |
| NF-AT1 [T00550] | 348 | 356 | GGAAAAATG | 0,03 | 0,05 | |
| NF-AT1 [T00550] | 972 | 980 | TTTTTTTCC | 0,03 | 0,05 | |
| HNF-1C [T01951] | 443 | 451 | TTTTTTAAC | 0,03 | 0,11 | |
| HOXD9 [T01424] | 93 | 102 | AATAATAGCT | 0,03 | 0,13 | |
| HOXD10 [T01425] | 93 | 102 | AATAATAGCT | 0,03 | 0,13 | |
| STAT5A [T04683] | 63 | 75 | TAATTTCTAGGAA | 0,03 | 0,1 | |
| c-Ets-2 [T00113] | 116 | 124 | TTCCTTTTG | 0,03 | 0,08 | |
| c-Fos [T00123] | 772 | 781 | GAGTCAGATG | 0,03 | 0,01 | |
| SRY [T00997] | 565 | 573 | CTTTGTTTT | 0,03 | 0,06 | |
| SRY [T00997] | 981 | 989 | CTTTGTTGT | 0,03 | 0,06 | |
| POU2F1 [T00641] | 35 | 45 | ATTTACATCAG | 0,04 | 0,03 | |
| HOXD9 [T01424] | 607 | 616 | AATAATAATG | 0,04 | 0,25 | |
| HOXD10 [T01425] | 607 | 616 | AATAATAATG | 0,04 | 0,25 | |
| Elk-1 [T00250] | 374 | 382 | AAAAGGAAG | 0,04 | 0,03 | |
| NF-AT2 [T01945] | 348 | 357 | GGAAAAATGA | 0,05 | 0,08 | |
| NF-AT2 [T01945 | 971 | 980 | TTTTTTTTCC | 0,05 | 0,08 | |
| c-Ets-2 [T00113] | 815 | 823 | TGATAGGAA | 0,05 | 0,08 | |
| Elk-1 [T00250] | 68 | 76 | TCTAGGAAG | 0,05 | 0,05 | |
| HNF-1C [T01951] | 680 | 688 | AAATGTAAC | 0,05 | 0,14 | |
| LEF-1 [T02905] | 981 | 988 | CTTTGTTG | 0,05 | 0,04 | |
| AP-1 [T00029] | 769 | 777 | TTTGAGTCA | 0,05 | 0,04 | |
| POU2F1 [T00641] | 964 | 974 | ATATGCATTTT | 0,06 | 0,27 | |
| VDR [T00885] | 1017 | 1025 | CTGGTGAAC | 0,06 | 0,02 | |
| NF-AT2 [T01945] | 1057 | 1066 | GGAAATTAGC | 0,06 | 0,06 | |
| AR [T00040] | 1030 | 1038 | TCTCTGTCC | 0,06 | 0,01 | |
| MEF-2A [T01005] | 600 | 610 | TTCCATAAATA | 0,07 | 0,32 | |
| c-Ets-1 [T00112] | 206 | 212 | TTTCCTA | 0,07 | 0,13 | |
| c-Jun [T00133] | 771 | 777 | TGAGTCA | 0,07 | 0,05 | |
| c-Jun [T00133] | 1038 | 1044 | CCAGTCA | 0,07 | 0,02 | |
| LEF-1 [T02905] | 768 | 775 | CTTTGAGT | 0,07 | 0,13 | |
| c-Myb [T00137] | 905 | 912 | AAACTGGC | 0,07 | 0,03 | |
| NF-Y [T00150] | 721 | 728 | AAACCAAT | 0,07 | 0,08 | |
| IRF-1 [T00423] | 781 | 789 | GATTGGAAA | 0,07 | 0,07 | |
| IRF-1 [T00423] | 1053 | 1061 | GAGAGGAAA | 0,07 | 0,07 | |
| T3R-beta1 [T00851] | 747 | 755 | TCAGGGTGA | 0,08 | 0,03 | |
| c-Ets-2 [T00113] | 166 | 174 | TTCCTACCT | 0,08 | 0,03 | |
| NF-AT1 [T00550] | 202 | 210 | TATATTTCC | 0,08 | 0,14 | |
| NF-AT1 [T00550] | 785 | 793 | GGAAAATTA | 0,08 | 0,14 | |
| PPAR-alpha:RXR-alpha [T05221] | 822 | 832 | AACTGAGACAA | 0,08 | 0,03 | |
La segona metodologia utilitzada per resoldre el problema es basa en el programa en Perl elaborat per nosaltres mateixes i el fitxer de les 13 matrius que ja sen’s proporcionava en les instruccions del treball. Aquest dos documents hi podeu accedir a través dels següents links:
PROGRAMA
MATRIUS
Dels resultats obtinguts vam seleccionar aquells que presentaven puntuacions positives i dels resultants ens vam quedar tant sols amb aquells que presentaven un p-value inferior a 0,2. A l’hora d’avaluar els resultats obtinguts hem de tenir present que es tracta d’una gran simplificació del mètode utilitzat anteriorment i per tant és important saber que el programa PROMO serà molt més sensible, per exemple pot tenir en compte canvis que es poden donar a la matriu. També recordar que el p-value que obtenim amb el nostre programa es basa en una permutació a l’atzar de la nostra seqüència que té lloc 100 vegades per tant cada vegada que executem el programa obtindrem p-values diferents. Després d’executar el programa vàries vegades vam arribar a la conclusió que p-values inferiors a 0,2 podrien ser acceptats com a valors relativament significatius en la nostra aproximació.
Els resultats obtinguts van ser els següents ( amb negre mostrem els resultats que considerem significatius i en gris aquells que presenten puntuacions positives però p-values més alts de 0,2):
| RESULTATS PROGRAMA PERL AML1 | |||||
| FACTOR DE TRANSCRIPCIÓ | PUNTUACIÓ | INICI | FINAL | SEQÜÈNCIA | pVALUE |
| FA NF-AT1 [T00550] | 2,9174 | 713 | 719 | ggaaagg | 0.18 |
| FA YY1 [T00915] | 2,6893 | 942 | 947 | atggaa | 0,65 |
| FA HIF-1 [T01609] | 3,8836 | 971 | 979 | aaagcacgt | 0,02 |
| FA AhR [T01795] | 2,8983 | 701 | 707 | gcgtgtg | 0,44 |
| FA PU.1 [T02068] | 3,1481 | 379 | 385 | aaggaat | 0,28 |
| RESULTATS PROGRAMA PERL MTG8A | |||||
| FACTOR DE TRANSCRIPCIÓ | PUNTUACIÓ | INICI | FINAL | SEQÜÈNCIA | pVALUE |
| FA AR [T00040] | 2,8661 | 981 | 987 | gaacagg | 0,34 |
| FA NF-AT1 [T00550] | 2,9573 | 178 | 184 | ggaaaga | 0,44 |
| FA SRF [T00764] | 3,4952 | 874 | 882 | caattatgg | 0,06 |
| FA YY1 [T00915] | 2,4594 | 879 | 884 | atggct | 0,55 |
| FA RXR-alpha [T01345] | 3,3085 | 438 | 443 | tgaacc | 0,08 |
| FA AhR [T01795] | 3,2154 | 284 | 290 | gcgtgtg | 0,16 |
| FA PU.1 [T02068] | 2,4176 | 501 | 507 | caggaat | 0,58 |
| RESULTATS PROGRAMA PERL MTG8B | |||||
| FACTOR DE TRANSCRIPCIÓ | PUNTUACIÓ | INICI | FINAL | SEQÜÈNCIA | pVALUE |
| FA AP-1 [T00029] | 4,0233 | 772 | 778 | tgagtca | 0,06 |
| FA AR [T00040] | 3,5576 | 529 | 535 | gaacagc | 0 |
| FA NF-AT1 [T00550] | 3,2255 | 349 | 355 | ggaaaaa | 0,11 |
| FA YY1 [T00915] | 2,584 | 833 | 838 | atgggg | 0,6 |
| FA RXR-alpha [T01345] | 2,162 | 554 | 559 | tgaaac | 0,73 |
| FA PU.1 [T02068] | 2,9479 | 292 | 298 | gaggaat | 0,18 |
| FA HNF-4 [T02758] | 4,434 | 195 | 202 | tggaccct | 0 |
Si comparem els resultats obtinguts amb el programa PROMO i el programa perl veiem que alguns dels factors de transcripció es repeteixen: en el cas de la proteïna AML1 l’únic resultat que comparteixen les dues solucions és el factor de transcripció NF-AT1. En el cas de MTG8A trobem dos resultats comuns: NA-SFR i RXR-alpha. Pel què fa a MTG8B en trobem 4: AP-1, AR, NF_AT1, PU.1 i HNF-4.
Però quan mirem aquests resultats en més detall ens adonem que les posicions en la seqüència promotora on el PROMO troba els motius d’unió d’aquests factors no coincideixen amb les obtingudes amb el nostre programa ni en longitud ni en composició de núcleotids. Finalment ens vam adonar que les matrius que utilitzem en el nostre programa no coincideixen amb les matrius del programa PROMO i és per aquest motiu que no podem comparar els resultats.
Resultats de la cerca de la funció de les diferents proteïnes a la base de dades GeneOntology:
Per AML1:
Pel que fa a la proteïna de fusió sabem que intereferix en l’expressió de gens hematopoiètics i és un element important per la generació de la leucèmia. Les translocacions cromosòmiques estan molt involucrades en el desenvolupament de leucèmies ja sigui forçant la l’activació d’oncogens o formant nous gens de fusió. La translocació t(8;21)(q22;q22) és una de les translocacions més freqüent en la leucemia mieloide aguda (AML). Aquesta proteïna de fusió consisteix en la porció N-terminal de ALM1 fusionada mantenint la pauta de lectura amb gairebé tota la proteïna MTG8.
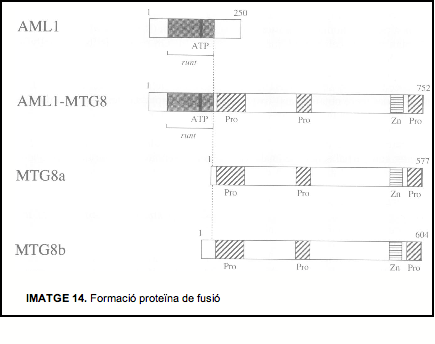
La proteína AML1 forma complexes heterodimerics amb CBFβ i regula la transcripció dels gens diana unint-se al DNA a través d’un domini d’unió que es troba a la regió N-terminal. Aquest domini d’unió presenta molta homologia amb el gen Runt que és un gen pair-rule de Drosophila. Perquè es produeixi l’activació transcripcional mediada per AML1 també necessita el seu domini de transactivació C-terminal que interactua amb altres coactivadors. L’AML1 és un regulador essencial de molts gens específics de cèl.lules hematopoiètiques.
La proteïna MTG8 conté dos dominis Zn-finger i vàries regions riques en prolina. També interactua amb receptors nuclears correpressors com complexes histona deacetilasa (HDAC) cosa que suggereix la seva funció és de correpressor transcripcional.
La proteïna de fusió AML1-MTG8 conté el domini d’unió al DNA de la proteïna AML1 i la porció de MTG8 que interacciona amb el complexe correpressor HDAC. Per tant és molt probable que la proteína AML1-MTG8 recluti histona deacetilasas als promotors dels gens diana de AML1 i produeixi la deacetilació de les histones d’aquesta regió que resultarà en una repressió transcripcional. Coneixent la funció de AML1 podem concloure que quan això tingui lloc la hematopoiesis definitiva serà absent. A més a més aquesta proteïna no només té aques efecte dominant negatiu sobre AML1 sinó que també se sap que altera l’expressió de diferents gens. Alguns d’aquests gens han estat identificats com és el cas de Tis11b i s’ha vist que participaven en el procés de generació de leucèmia
La metodología usada per realitzar aquest treball es basa en mètodes computacionals.
Primerament, vam haver d’identificar la seqüència proteica assignada al nostre grup. Per fer-ho vam realitzar un alineament amb l’opció tBLASTn i ens vam quedar amb el resultat que presentava una puntuació més alta, un percentatge d’identitat més alt i un evalue més baix. Aquest resultat va correpondre amb el trànscrit de la proteïna de fusió AML1-MTG8.
Posteriorment, per tal de caractertizar l’estructura genòmica vam realitzar un BLAT a la base de dades UCSC i vam obtenir informació sobre les dues proteïnes que formen part de la proteïna de fusió independentment. Paral.lelament, vam realitzar la mateixa cerca de l’Ensembl. En aquestes dues bases de dades la informació que vam buscar per cada trànscrit va ser: número d’exons, posició final, posició inicial, frame, i si es tractaven d’exons codificants, no codificants o híbrids. Finalment ens vam quedar amb els resultats proporcionats per la base de dades RefSeq ja que eren molt més verossímils tenint en compte la seqüència proteica inicial i sabent que es tracta d’una base de dades en que la informació que s’hi trobava es basa en anàlisis funcionals en comptes de en prediccions. A partir d’aquests resultats vam intentar averiguar si eren formes de splicing alternatiu i si aquestes afectaven a la regió codificant. A continuació vam buscar les possibles isoformes de cada proteïna a una tercera base de dades, UNIPROT.
Per tal de buscar informació sobre la homologia de les proteïnas que constitueixen la proteïna de fusió vam usar l’Ensembl. Vam extreure dades sobre el gen, el tipus d’homologia i el percentatge d’identitat. A més a més vam realitzar un altre aliniament amb la seqüència de nucleòtids en FASTA de la proteïna de fusió per averiguar si aquesta presentava algun ortòleg en altres espècies. Però en el resultat no vam obtenir cap homòleg per la proteína sencera, només per les diferents parts de la proteïna tal i com haviem obtingut prèviamet amb l’ensembl, per tant no ho vam incloure en els resultats.
Per duu a terme la caracterització de l’expressió; del gen ens vam basar una opció que ens proporcionava la base de dades UCSC . Vam usar la opció Gene Atlas-2 que com hem explicat abans es basa en assajos d’expressió realitzats a partir de microarrays amb mostres de diferents teixits.
Per caracteritzar la regió promotora, primerament, vam haver d’obtenir la regió promotora (es va considerar regió promotora 1000pb abans del TSS i 100 pb després) en format fasta. Per fer-ho vam usar la opció de Table browser de la base de dades UCSC. Una vegada obtingudes les regions promotores per els tres trànscrits que poden formar part de la proteïna de fusió, vam analitzar-la per tal de trobar-hi possibles llocs d’unió de factors de transcripció. Aquest anàlisi el vam elaborar de dues formes diferents: primer a través del programa PROMO i seguidament a través d’un programa perl elaborat per nosaltres que es basa en una simplificació del PROMO. Els dos programes segueixen el mateix principi: a partir d’una matriu d’ocurrències per cada factor de transcripció, elaboren una matriu de pesos, i apartir de la matriu de pesos, es puntuen els possibles llocs d’unió del factor que vagin trobant a la seqüència on es vulgui realitzar la cerca. Com he dit anteriorment, el nostre programa es tracta d’una gran simplificació i per tant serà molt menys sensible.
Dels resultats que vam obtenir amb el PROMO, a partir d’una cerca amb els següents filtres: que només busqués factors de transcripció humans, només llocs d’unió humans i que presentessin un índex de dissimilaritat inferior o igual al 15%, ens vam quedar només amb aquells que presentessin un RE equally inferior a 0,09, ja que vam considerar que es tracta d’un número suficientment baix com per poder discriminar aquells casos no significatius.
Dels resultats que vam obtenir amb el nostre programa vam escollir aquells que presentaven un pvalue inferior a 0,2 també considerant que es tractava d’un valor força raonable per discriminar els casos no significatius. Vam utilitzar un p-value relativament més alt perquè com he dit anteriorment, el nostre programa no és tant sensible i si restringim molt el p-value encara limitariem més els resultats obtinguts.
Finalment vam comparar els resultats obtinguts amb els dos mètodes per tal d’averiguar si algun dels factors de transcripció coincidia en els dos resultats. Això va ser així en alguns casos, però sorprenentment quan es van analitzar al detall ens vam adonar que ni la longitud ni la composició de nucleòtids coincidia.
A l’hora de buscar informació sobre la funció del gen vam utilitzar dues bases de dades: la base de dades Gene Ontology on vam cercar informació de les dues proteïnes per separat i el Pubmed on vam buscar articles sobre la proteïna de fusió.
En aquest treball el que es preten és estudiar els diferents aspectes d’un gen a través del seu analisi computacional. L’estudi es va iniciar amb una seqüència proteica de la qual es desconeixia la identitat. Per identificar-la vam realitar un alineament amb Blast contra tot el genoma humà. El resultat va ser una proteïna de fusió anomenada AML1-MTG8. Aquesta proteïna es produeix per una translocació que ajunta un gen del cromosoma 21 (AML1) amb un gen al cromosoma 8 (MTG8).
 En aquest procés no es trenca la pauta de lectura de manera que dóna un trànscrit de fusió AML1-MTG8. Aquesta translocació t(8;21) porta al desenvolupament de leucemia mieloide aguda i és una de les translocacions més freqüents en aquest tipus de càncer.
En aquest procés no es trenca la pauta de lectura de manera que dóna un trànscrit de fusió AML1-MTG8. Aquesta translocació t(8;21) porta al desenvolupament de leucemia mieloide aguda i és una de les translocacions més freqüents en aquest tipus de càncer.
Per caracteritzar l’estructura genòmica del gen vam estudiar les dues proteïnes per separat. Pel que fa a AML1 segons les dades de refSeq, observem que presenta dos trànscrits amb número i longitud d’exons diferents. Amb aquestes dades juntament amb la informació sobre la fase en que s’acaben els diferents exons podem concloure que es tracta de diferents isoformes generades per splicing alternatiu i buscant les isoformes vam poder concloure que aquest afectava a la regió codificant. De tots els resultats obtinguts l’únic que podia formar part de la proteïna de fusó tenint en compte la seqüència d’aquesta era el trànscrit número 1 de RefSeq (NM_001001890) que corresponia a la isoforma 1 de Uniprot (Q01196). Pel que fa a MTG8, amb les dades de RefSeq obtenim 4 trànscrits diferents, Els 1er d’aquests 4 presenta diferents número i longitud d’exons. Els altres 3 tenen els mateix número d’exons i només difereixen en la longitud i porció codificant del primer exó. Aquests 4 trànscrits són els resultat d’un procés de splicing alternatiu. Per altra banda, vam cercar informació sobre les isoformes i a la base de dades Uniprot en vam trobar 2 que correponen a :MTG8a i MTG8b. Comparant les seqüències concluïm que es correponen amb els trànscrits NM_004349 i NM_175634.
A l’hora d’evaluar l’homologia del gen que codifica per la proteïna de fusió amb altres espècies vam realitzar un BLAST, però en el resultat no vam trobar seqüència en altres espècies que sigui homòloga a la proteïna de fusió sencera sino que eren homòlogues o bé a la porció que codifica per AML1 o per MTG8. Per tant una vegada més vam analitzar els resultats per separat. Pel que fa a AML1, tant sols observem resultats d’homologia alts en espècies filogenèticament molt properes. En canvi, per MTG8 observem percentatges d’identitat més alts fins i tots en espècies més allunyades filogenèticament cosa que suggeriex que es podria tractar d’una proteïna més conservada.
Per caracteritzar l’expressió d’aquesta proteïna vam buscar resultats d’analisis d’expressió. En aquests vam trobar informació de les dues proteïnes per separat. AML1 s’expressa en teixit cancerós i sistema immunitari mentre que MTG8 s’expressa en múscul i cervell. Paral.lelament vam buscar informació en articles sobre l’expressó de la proteïna de fusió. La informció obtinguda coincida gairebé al 100% amb l’expressió de les proteïnes per separat amb l’excepció de que MTG8 no era present ni en teixit cancerós ni en teixit hematopoiètic quan s’analitza per separat però si quan forma part de la proteïna de fusió. Aquest és el primer indici que insinuava ja que AML1 és un factor molt important per les cèl.lules hematopoiètiques i que probablement la seva activitat es veurà interferida al fusionar-se amb MTG8.
Per tal de caracteritzar la regió promotora del gen vam buscar les seqüències promotores pels 3 trànscrits que poden formar part de la proteïna de fusió. Amb aquestes seqüències es van realitzar prediccions dels diferents llocs d’unió de factors de transcripció que podiem trobar al llarg de cada seqüència promotora. Aquestes prediccions es van realitzar seguint dues metodologies diferents el programa PROMO i el programa en perl elaborat per nosaltres. Amb el programa PROMO utilitzant els límits ja comentats en l’apartat de resultats i metodologia vam obtenir: 65 prediccions per AML1, 60 per MTG8A i 65 per MTG8B. Per altre banda els resultats obtinguts amb el nostre programa van ser: 2 per AML1, 3 per MTG8A i 5 per MTG8B. Els resultats obtinguts pels dos mètodes coincideixen per alguns factors de transcripció: per AML1 comparteixen NF-AT1, per MTG8A comparteixen: NA-SFR i RXR-alpha i per MTG8B comparteixen AP-1, AR, NF_AT1 i PU.1. No obstant, quan mirem les seqüències que corresponen als llocs d’unió per aquests factors de transcripció trobades per cadascun dels mètodes s’observa sorprenentment que difereixen tant en longitud del motiu com en composició de nucleòtids. Aquest fet es deu a que inicialment creiem que els dos programes partien de les mateixes matrius d’ocurrències però al buscar les matrius del programa promo ens vam adonar que no eren les mateixes que teniem al fitxer per elaborar el programa. El fet que per un mateix factor de transcripció puguem tenir matrius d’ocurrències diferents en composició de nucleòtids es podria deure a que el lloc d’unió d’aquests factors transcripció sigui molt heterogeni.
A l’hora d’estudiar la funció del gen ho hem fet a partir de dos perspectives diferents: d’una banda vam analitzar la funció de cada proteïna per separat a la base de dades GeneOntology i per l’altre vam buscar informació sobre la proteïna de fusió en diferents articles. Dels resultants obtinguts concloem que les dues proteines actuen com a factors de transcripció i presenten diferents dominis d’unió al DNA. Pel que fa a AML1 sabem que es tracta d’un regulador essencial de molts gens hematopoiètics mentre que MTG8 també interacciona amb receptors nuclears però en aquest cas són correpressors com complexes histona deacetilasa i per tant actua coma correpressor transcripcional. Pel que fa a la proteïna de fusió se sap que interfereix en l’expressió de gens hematopoiètics i que té un paper essencial en la generació de leucèmia mieloide aguda . Aquesta proteïna manté el domini d’unió al DNA de AML1 i el domini de MTG8 que interacciona amb el complexe histona deacetilasa. És fàcil de pensar doncs, que el que aquesta translocació provocarà serà l’acúmul de histona deacetilases als promotors dels gen que es troben sota el control de AML1 i per tant serà una mutació amb efecte dominant negatiu de AML1 i farà que la diferenciació hematopoiètica final sigui completament abscent. A més s’ha comprovat a través d’assajos d’expressió que aquesta proteïna de fusió altera també l’expressió de diferents gens alguns dels quals se’n coneix la seva participació en el procés de generació de leucèmia.