{kind=link}
{kind=link}

| Introducció | Materials i mètodes | Anàlisi de dades | Conclusions |

A l'igual que l'apartat anterior dividirem aquest en dos per tal de poder extreure les conclusions a partir de les taules i gràfic de l'apartat anterior.
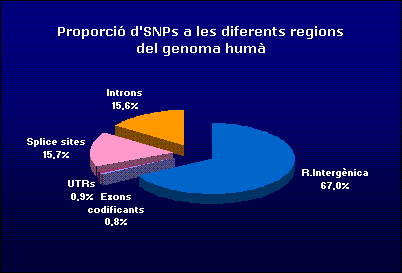
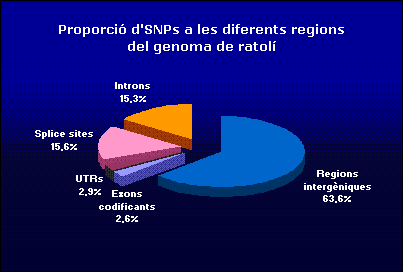
Si ens fixem en la distribució dels SNPs en les diferents regions del genoma humà i de ratolí; veiem que la major part cauen en regions intergèniques, amb un 67 i 63.3% del total dels SNPs analitzats en el genoma humà i de ratolí respectivament. Això és degut a que són zones que no formen part de cap gen, per tant no estan implicades en la traducció de proteďnes amb el què no estàn sotmeses a cap tipus de pressió selectiva i accepten més variació que no pas les regions gèniques.
En quant a les regions gèniques, el què més sobta és que en els exons codificants observem una proporció molt baixa d'SNPs, només un 2.5% pel què fa al genoma humà i un 7.2% en el cas del genoma de ratolí.
És lògic que hi hagi pocs SNPs en aquestes regions ja que codifiquen per proteïnes, i qualsevol canvi en un nucleòtid comportaria una variació en la composició aminoacídica de la proteïna. Així doncs, es tracta de zones amb una alta pressió selectiva que no toleren massa bé el canvis en els diferents nucleòtids.
El fet que trobem una proporció d'SNPs en els exons codificants és deguda a que el codi genètic es degenerat amb el què diferents combinacions de nucleòtids poden donar lloc al mateix aminoàcid. Segurament els SNPs que trobem en aquestes regions cauen en posicions que no comporten canvi d'aminoàcid (canvis sinònims) i per tant l'aminoàcid pel qual codifica és el mateix. La Selecció Natural així, actuará sobre els casos en que hi hagi modificació de l'aminoàcid ja que pot tenir repercussions a nivell de proteina.
Les regions UTR també conten una proporció bastant baixa d'SNPs, 2.6% pel què fa al genoma humà i un 8% en el cas del genoma de ratolí. Són regions que no tradueixen per proteïna, per tant haurien d'acceptar certa variació, però per altra banda tenim que es tracta de regions essencials per la transcripció i la traducció de gens, aixi que canvis en aquesta regió poden desencadenar errors tant de transcripcio com de traduccio. Es lògic doncs que aquestes regions presentin molta menor quantitat d'SNPs que no pas les regions intròniques del gen que no tindran cap paper fonamental en la transcripció i traducció dels gens.
A més, observem que el grau de conservació entre l'UTR 3' i l'UTR 5' és molt similar, ja que aproximadament, per ambdues espècies, trobem els SNPs distribuits en un 50% en cada regió UTR. No observem diferències significatives així que podem afirmar que la pressió slectiva és similar per ambdues regions.
Ja per acabar comentarem les regions d'splicing, en el nostre cas hem obtingut uns resultats que indiquen que pel genoma humà trobem un 47.7% d'SNPs en aquesta regió i en el genoma de ratolí un 42.9%. Aquests resultats son molt xocants ja que ens indica que les regions s'splicing contenen una proporció d'SNPs similar a la que contenen les regions intròniques.
Aquestes regions d'splicing son imprescindibles per al processament del pre-mRNA a mRNA madur, que serà el que es traduirà a proteïna. Les variacions de nucleòtids en aquestes regions seran poc acceptades, al igual que en les regions exòniques i UTR ja que s'interferiria en el processament del mRNA amb repercusions sobre la proteina.
Com ja hem dit observem que la Selecció Natural no ha exercit massa pressio en aquestes regions, fet que xoca amb el que realment hauriem d'esperar, una forta pressió en aquestes regions.
Si ens fixem en el gràfic on hi ha les diferències entre les regions donor i acceptor, veiem que hi ha una proporció molt més elevada en regions donor que no pas aceptor. Quan mirem les xifres, veiem que en el cas d'humà trobem 9475 SNPs en regions Acceptor mentre que a les regions Donor n'arribem a trobar 1446962. Pel que fa a ratolí obtenim uns resultats similars però amb menor quantitat ja que els SNPs descrits en el genoma de ratolí són molt menors. Trobem 846 SNPs en regions Acceptor i 62943 en regions Donor. Analitzant amb cura aquests resultats obtinguts, podem arribar a afirmar que la quantitat d'SNPs que es troben en regions Donor és molt elevada i que es tracta d'un resultats que no són massa fiables. Per contra la quantitat d'SNPs en regions Acceptor ens sembla molt més raonable. Per tant podriem plantejar que el programa presenta alguna mena d'error i que el comptatge d'SNPs en regions Donor ha és erroni.
Un cop finalitzat aquest projecte volem agrair la col·laboració d'en Robert Castelo en l'elaboració d'aquest.
| Introducció | Materials i mètodes | Anàlisi de dades | Conclusions |