La gran majoria del DNA genòmic està format per elements repetius,
aproximadament un 40% del total, que no codifiquen per a res, és l'anomenat
"DNA deixalla".
Aquest DNA pot representar una interferència (falsos positius) en la predicció de
gens i és per això que cal enmascarar-lo.
Per a fer aquest enmascarament s'ha utilitzat el programa
RepeatMasker i després
d'introduir la seqüència en format fasta s'han obtingut els següents
resultats:
1. Seqüència emmascarada Accés
2. Tipus i contingut de repeticions presents Accés
3. Taula resum
==================================================
file name: repeat.seq
sequences: 1
total length: 500000 bp (500000 bp excl N-runs)
GC level: 40.20 %
bases masked: 206908 bp ( 41.38 %)
==================================================
number of length percentage
elements* occupied of sequence
-------------------------------------------------
SINEs: 252 57501 bp 11.50 %
ALUs 155 42226 bp 8.45 %
MIRs 97 15275 bp 3.06 %
LINEs: 149 80427 bp 16.09 %
LINE1 85 62190 bp 12.44 %
LINE2 55 16205 bp 3.24 %
L3/CR1 9 2032 bp 0.41 %
LTR elements: 77 39200 bp 7.84 %
MaLRs 40 18185 bp 3.64 %
ERVL 30 11602 bp 2.32 %
ERV_classI 7 9413 bp 1.88 %
ERV_classII 0 0 bp 0.00 %
DNA elements: 83 24248 bp 4.85 %
MER1_type 51 12831 bp 2.57 %
MER2_type 13 7120 bp 1.42 %
Unclassified: 1 85 bp 0.02 %
Total interspersed repeats: 201461 bp 40.29 %
Small RNA: 2 198 bp 0.04 %
Satellites: 0 0 bp 0.00 %
Simple repeats: 65 3064 bp 0.61 %
Low complexity: 53 2182 bp 0.44 %
==================================================
* most repeats fragmented by insertions or deletions
have been counted as one element
En aquesta taula es pot observar que hi ha un 40.20% d'elements repetitius,
que és el que s'esperava trobar.
Per tal de poder visualitzar els resultats, aquests es passen en format GFF. El GFF és un format que permetrà estandaritzar totes les dades per així poder visualitzar les anotacions de les seqüències genòmiques. Per obtenir-lo s'ha executat la següent comanda:
grep ref|NT_006431.13| repeat.seq.out | \
awk 'BEGIN{ OFS="\t" }
{ print $5, $11, "repeat", $6, $7, ".", ".", "."; }
' > repeat.seq.out.gff
Un cop obtinguts els resultats en format gff, es pot córrer el programa Gff2ps, aplicant la següent ordre:
gff2ps repeat.seq.out.gff > repeat.seq.out.ps
Finalment, per a poder veure la imatge correctament s'ha convertit el format .ps en format .jpg amb el següent script:
convert -rotate 90 -density 150 repeat.seq.out.ps repeat.seq.out.jpg
| A la dreta es mostra la imatge obtinguda amb el resultats de la seqüència on s'observa d'acord amb el què es veu a la Taula resum que
hi ha una gran quantitat de SINES i LINES, arribant fins a un 65% del total d'elements repetitius continguts en la seqüència problema |
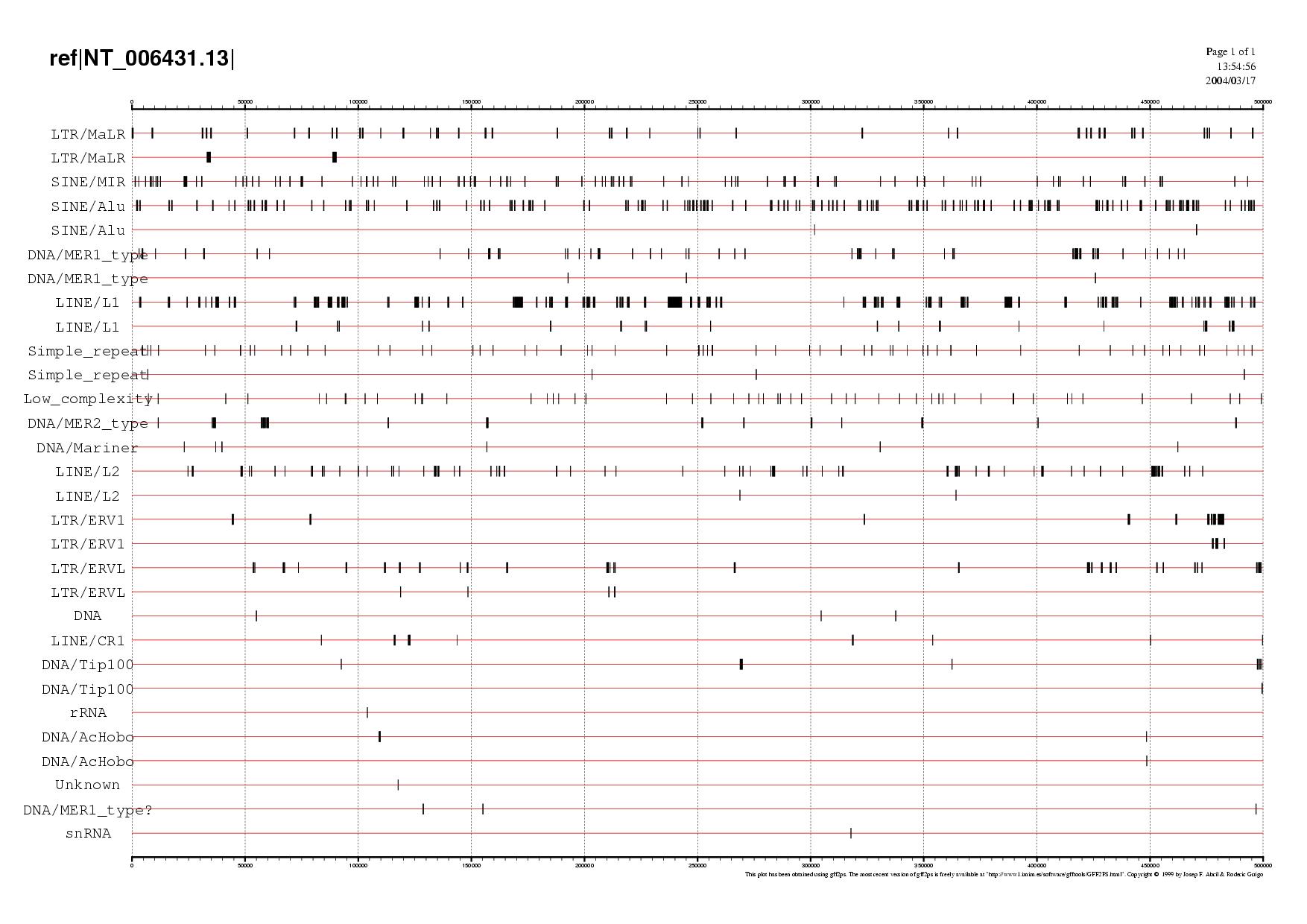 |
En el gràfic s'observa que els elements repetitius més abundants són els LINES, i que la seva distribució al llarg de la seqüència és força localitzada. En canvi, els SINES presenten una distribució més homogènia.