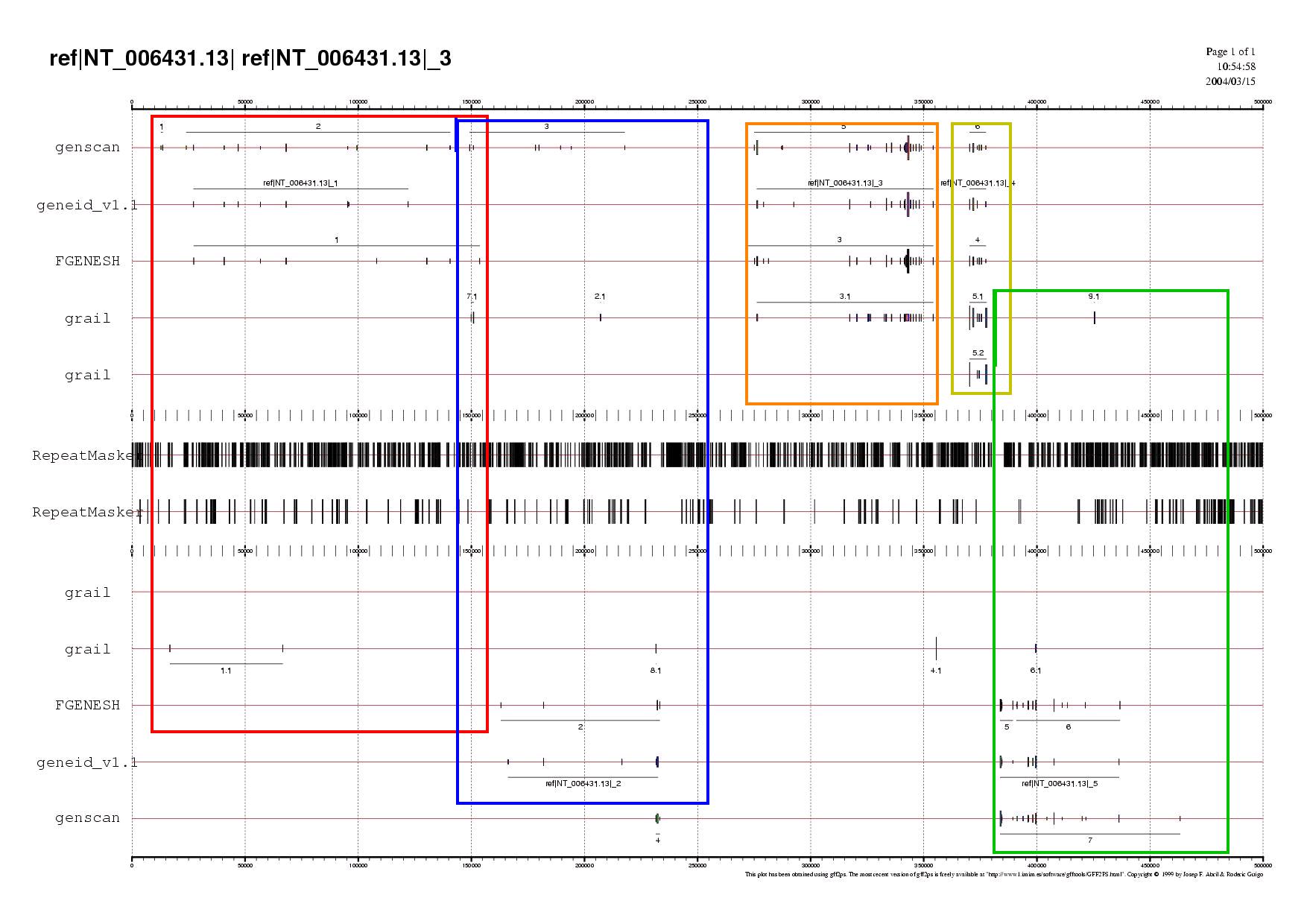
Observacions
Atès a que la seqüència a estudiar és molt llarga i que
seria molt difícil treballar amb ella, ja que els servidors utilitzats tenen un límit en el tamany de les seqüències que es poden introduir, s'ha cregut convenient dividir-la
en subseqüències o regions. Aquestes són 5 i coincideixen
aproximadament amb els clusters de gens descrits anteriorment.
Per a fer les
subseqüències s'han seleccionat com a inici el començament
i finals de gens que abarcaven el màxim de distància i se'ls hi
ha sumat 1000 bases per cada costat. Per exemple, el començament de la
primera subseqüència seria l'inici del gen 1 predit per genscan
(posició 12744) menys 1000 bases per extendre-la una mica més.
És a dir, que l'inici de la subseqüència seria el nucleòtid
11744. El final de la subseqüència seria l'últim nucleòtid
de la proteïna 1 predita per Fgenesh (153755) més 1000 nucleòtids
més. Llavors en aquest cas seria 154755.
A continuació s'adjunta una taula amb les coordenades d'inici i final
de cada una de les subseqüències que han estat triades (ja corregides
):
|
INICI |
FINAL |
| subseqüència 1 |
inici gen 1 Genescan11744 |
gen 1 Fgenesh 154755
|
| subseqüència 2 |
final gen 1 Fgenesh 152755 |
gen 2 Geneid 233502 |
| subseqüència 3 |
gen 3 Fgenesh 270735 |
gen 3 Geneid 355258 |
| subseqüència 4 |
gen 4 Fgenesh 269224 |
gen 4 Fgenesh 378480 |
| subseqüència 5 |
gen 7 Genscan 382706 |
gen 7Genscan 464391 |
En el següent gràfic es mostra cada una de les finestres enmarcades amb un color diferent: