

____ESPECIFICACIONES____
1) Este programa está escrito en lenguaje PERL. Por tanto necesita un ordenador que tenga UNIX instalado para ser ejecutado.
2) Es muy importante introducir los parámetros, y en el orden correcto (es decir, primero el nombre del fichero que contiene la secuencia, y después el del fichero que contiene la tabla de sesgo en el uso de codones). Así mismo, se debe comprobar que tanto la tabla como la secuencia sean de DNA.
3) Es necesario cerciorarse de que el formato de la secuencia y de la tabla sean los adecuados. A la hora de bajarse la tabla de la web recomendada hay que seguir los siguientes pasos:
- seleccionar el organismo
- hacer un "submit" de la primera tabla seleccionando "standard" en format
y "A style like
Codon Frequency output in GCG"
- clicar en "submit" y grabar esa tabla en un fichero .txt
- correr el programa TRANSFORMER con el fichero.txt para tener la tabla
en el formato
adecuado para ORFFINDER
4) Una vez obtenido el archivo de salida de ORFFINDER, se puede filtrar para obtener en otros archivos de salida los ORFs con mayor probabilidad de ser codificantes. El umbral de aceptación es fijado por el usuario mediante comandos de UNIX, y puede aplicarse tanto al score como a la longitud de los ORFs.
5) El archivo filtrado se tiene que pasar a formato GFF para que el programa que genera el archivo en Postscript pueda trabajar con él. Ésto se consigue utilizando un comando de UNIX.
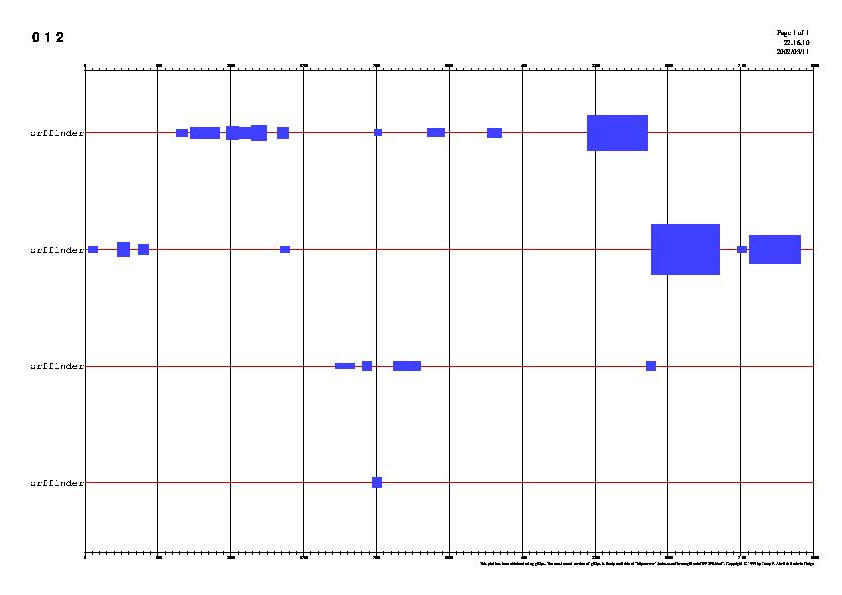
6) El archivo GFF lo transformamos a formato PS con el programa GFF2PS.
7) El archivo PS lo visualizamos gráficamente con el programa GHOSTVIEW (ejecutado desde el SHELL).
NOTA: todos los comandos de UNIX necesarios están ejemplificados más abajo.
./orffinder.pl
secuencia.fa tabla.txt
El nombre de los ficheros es orientativo; se puede escoger cualquiera.
La entrada de la secuencia en NCBI
se encuentra aquí.
La tabla se ha conseguido en la web recomendada en la sección anterior.
NOTA: Los parámetros del filtro son modificables.
NOTA: Para modificar el formato del archivo .ps que obtenemos se pueden utilizar diferentes parámetros de GFF2PS que encontrarás en el manual del usuario de la web del programa.
AGRADECIMIENTOS
A
todos aquellos que nos han ayudado (you know who you are!)

![]()